


Amazon Textract is a machine studying (ML) service that routinely extracts textual content, handwriting, and information from any doc or picture. AnalyzeDocument Structure is a brand new characteristic that permits prospects to routinely extract structure components corresponding to paragraphs, titles, subtitles, headers, footers, and extra from paperwork. Structure extends Amazon Textract’s phrase and line detection by routinely grouping the textual content into these structure components and sequencing them in accordance with human studying patterns. (That’s, studying order from left to proper and high to backside.).
Constructing doc processing and understanding options for monetary and analysis studies, medical transcriptions, contracts, media articles, and so forth requires extraction of data current in titles, headers, paragraphs, and so forth. For instance, when cataloging monetary studies in a doc database, extracting and storing the title as a catalog index allows straightforward retrieval. Previous to the introduction of this characteristic, prospects needed to assemble these components utilizing post-processing code and the phrases and features response from Amazon Textract.
The complexity of implementing this code is amplified with paperwork with a number of columns and sophisticated layouts. With this announcement, extraction of generally occurring structure components from paperwork turns into simpler and permits prospects to construct environment friendly doc processing options sooner with much less code.
In Sept 2023, Amazon Textract launched the Structure characteristic that routinely extracts structure components corresponding to paragraphs, titles, lists, headers, and footers and orders the textual content and components as a human would learn. We additionally launched the up to date model of the open supply postprocessing toolkit, purpose-built for Amazon Textract, referred to as Amazon Textract Textractor.
On this publish, we focus on how prospects can make the most of this characteristic for doc processing workloads. We additionally focus on a qualitative examine demonstrating how Structure improves generative synthetic intelligence (AI) job accuracy for each abstractive and extractive duties for doc processing workloads involving giant language fashions (LLMs).
Structure components
Central to the Structure characteristic of Amazon Textract are the brand new Structure components. The LAYOUT characteristic of AnalyzeDocument API can now detect as much as ten totally different structure components in a doc’s web page. These structure components are represented as block sort within the response JSON and include the arrogance, geometry (that’s, bounding field and polygon data), and Relationships, which is a listing of IDs comparable to the LINE block sort.
- Title – The principle title of the doc. Returned as
LAYOUT_TITLEblock sort. - Header – Textual content situated within the high margin of the doc. Returned as
LAYOUT_HEADERblock sort. - Footer – Textual content situated within the backside margin of the doc. Returned as
LAYOUT_FOOTERblock sort. - Part Title – The titles beneath the primary title that characterize sections within the doc. Returned as
LAYOUT_SECTION_HEADERblock sort. - Web page Quantity – The web page variety of the paperwork. Returned as
LAYOUT_PAGE_NUMBERblock sort. - Record – Any data grouped collectively in record type. Returned as
LAYOUT_LISTblock sort. - Determine – Signifies the situation of a picture in a doc. Returned as
LAYOUT_FIGUREblock sort. - Desk – Signifies the situation of a desk within the doc. Returned as
LAYOUT_TABLEblock sort. - Key Worth – Signifies the situation of type key-value pairs in a doc. Returned as
LAYOUT_KEY_VALUEblock sort. - Textual content – Textual content that’s current sometimes as part of paragraphs in paperwork. It’s a catch all for textual content that isn’t current in different components. Returned as
LAYOUT_TEXTblock sort.
Every structure aspect could include a number of LINE relationships, and these traces represent the precise textual content material of the structure aspect (for instance, LAYOUT_TEXT is usually a paragraph of textual content containing a number of LINEs). It is very important word that structure components seem within the appropriate studying order within the API response because the studying order within the doc, which makes it straightforward to assemble the structure textual content from the API’s JSON response.
Use instances of layout-aware extraction
Following are a few of the widespread use instances for the brand new AnalyzeDocument LAYOUT characteristic.
- Extracting structure components for search indexing and cataloging functions. The contents of the
LAYOUT_TITLEorLAYOUT_SECTION_HEADER, together with the studying order, can be utilized to appropriately tag or enrich metadata. This improves the context of a doc in a doc repository to enhance search capabilities or manage paperwork. - Summarize your complete doc or components of a doc by extracting textual content in correct studying order and utilizing the structure components.
- Extracting particular components of the doc. For instance, a doc could include a mixture of photographs with textual content inside it and different plaintext sections or paragraphs. Now you can isolate the textual content sections utilizing the
LAYOUT_TEXTaspect. - Higher efficiency and correct solutions for in-context doc Q&A and entity extractions utilizing an LLM.
There are different attainable doc automation use instances the place Structure could be helpful. Nonetheless, on this publish we clarify extract structure components as a way to assist perceive use the characteristic for conventional documentation automation options. We focus on the advantages of utilizing Structure for a doc Q&A use case with LLMs utilizing a typical methodology referred to as Retrieval Augmented Technology (RAG), and for entity extraction use-case. For the outcomes of each of those use-cases, we current comparative scores that helps differentiate the advantages of structure conscious textual content versus simply plaintext.
To focus on the advantages, we ran exams to match how plaintext extracted utilizing raster scans with DetectDocumentText and layout-aware linearized textual content extracted utilizing AnalyzeDocument with LAYOUT characteristic impacts the result of in-context Q&A outputs by an LLM. For this take a look at, we used Anthropic’s Claude Immediate mannequin with Amazon Bedrock. Nonetheless, for advanced doc layouts, the technology of textual content in correct studying order and subsequently chunking them appropriately could also be difficult, relying on how advanced the doc structure is. Within the following sections, we focus on extract structure components, and linearize the textual content to construct an LLM-based software. Particularly, we focus on the comparative analysis of the responses generated by the LLM for doc Q&A software utilizing raster scan–based mostly plaintext and layout-aware linearized textual content.
Extracting structure components from a web page
The Amazon Textract Textractor toolkit can course of a doc via the AnalyzeDocument API with LAYOUT characteristic and subsequently exposes the detected structure components via the web page’s PAGE_LAYOUT property and its personal subproperty TITLES, HEADERS, FOOTERS, TABLES, KEY_VALUES, PAGE_NUMBERS, LISTS, and FIGURES. Every aspect has its personal visualization perform, permitting you to see precisely what was detected. To get began, you begin by putting in Textractor utilizing
As demonstrated within the following code snippet, the doc news_article.pdf is processed with the AnalyzeDocument API with LAYOUT characteristic. The response ends in a variable doc that incorporates every of the detected Structure blocks from the properties.

See a extra in-depth instance in the official Textractor documentation.
Linearizing textual content from the structure response
To make use of the structure capabilities, Amazon Textract Textractor was extensively reworked for the 1.4 launch to supply linearization with over 40 configuration choices, permitting you to tailor the linearized textual content output to your downstream use case with little effort. The brand new linearizer helps all at the moment accessible AnalyzeDocument APIs, together with types and signatures, which helps you to add choice gadgets to the ensuing textual content with out making any code adjustments.
See this instance and extra in the official Textractor documentation.
Now we have additionally added a structure fairly printer to the library that lets you name a single perform by passing within the structure API response in JSON format and get the linearized textual content (by web page) in return.
You have got the choice to format the textual content in markdown format, exclude textual content from inside figures within the doc, and exclude web page header, footer, and web page quantity extractions from the linearized output. You can too retailer the linearized output in plaintext format in your native file system or in an Amazon S3 location by passing the save_txt_path parameter. The next code snippet demonstrates a pattern utilization –
Evaluating LLM performing metrics for abstractive and extractive duties
Structure-aware textual content is discovered to enhance the efficiency and high quality of textual content generated by LLMs. Particularly, we consider two kinds of LLM duties—abstractive and extractive duties.
Abstractive duties seek advice from assignments that require the AI to generate new textual content that isn’t straight discovered within the supply materials. Some examples of abstractive job embrace summarization and query answering. For these duties, we use the Recall-Oriented Understudy for Gisting Analysis (ROUGE) metric to guage the efficiency of an LLM on question-answering duties with respect to a set of floor reality information.
Extractive duties seek advice from actions the place the mannequin identifies and extracts particular parts of the enter textual content to assemble a response. In these duties, the mannequin is concentrated on deciding on related segments (corresponding to sentences, phrases, or key phrases) from the supply materials quite than producing new content material. Some examples are named entity recognition (NER) and key phrase extraction. For these duties, we use Common Normalized Levenshtein Similarity (ANLS) on named entity recognition duties based mostly on the layout-linearized textual content extracted by Amazon Textract.
ROUGE rating evaluation on abstractive question-answering job
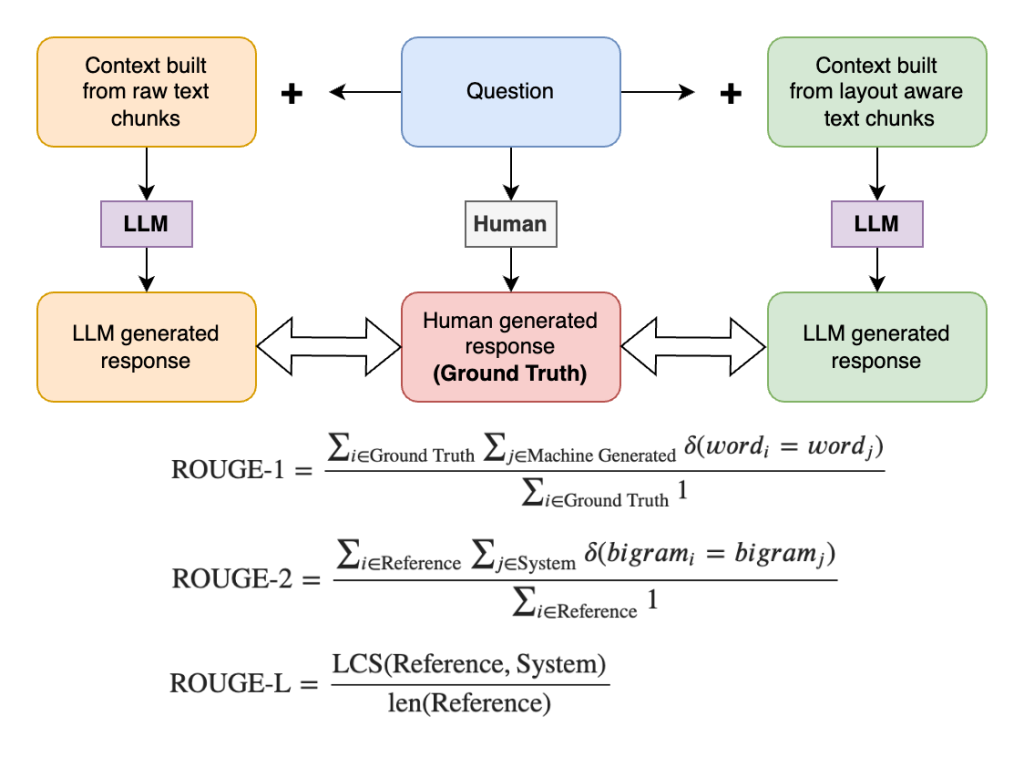
Our take a look at is ready as much as carry out in-context Q&A on a multicolumn doc by extracting the textual content after which performing RAG to get reply responses from the LLM. We carry out Q&A on a set of questions utilizing the raster scan–based mostly uncooked textual content and layout-aware linearized textual content. We then consider ROUGE metrics for every query by evaluating the machine-generated response to the corresponding floor reality reply. On this case, the bottom reality is similar set of questions answered by a human, which is taken into account as a management group.
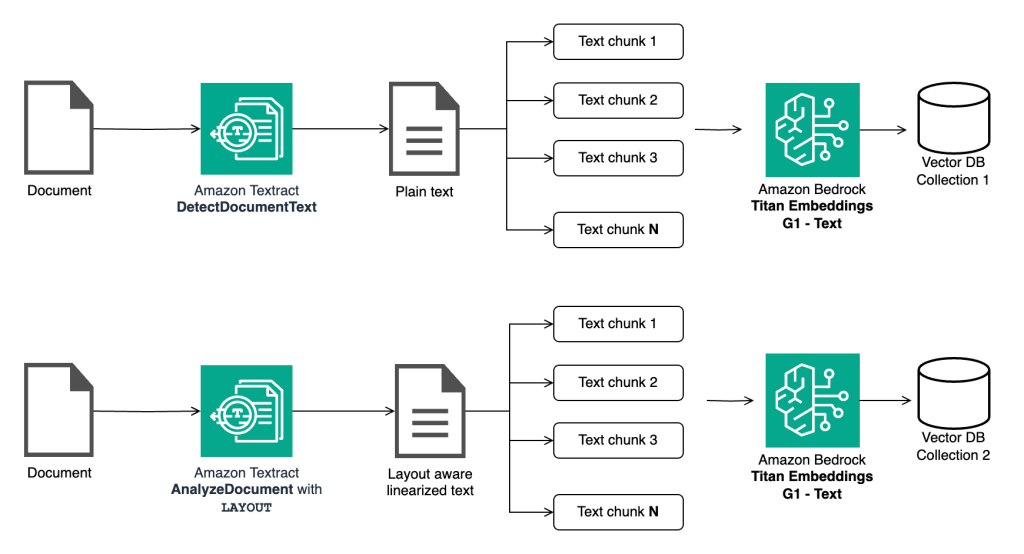
In-context Q&A with RAG requires extracting textual content from the doc, creating smaller chunks of the textual content, producing vector embeddings of the chunks, and subsequently storing them in a vector database. That is carried out in order that the system can carry out a relevance search with the query on the vector database to return chunks of textual content which are most related to the query being requested. These related chunks are then used to construct the general context and supplied to the LLM in order that it will probably precisely reply the query.
The next doc, taken from the DocUNet: Doc Picture Unwarping by way of a Stacked U-Web dataset, is used for the take a look at. This doc is a multicolumn doc with headers, titles, paragraphs, and pictures. We additionally outlined a set of 20 questions answered by a human as a management group or floor reality. The identical set of 20 questions was then used to generate responses from the LLM.

Within the subsequent step, we extract the textual content from this doc utilizing DetectDocumentText API and AnalyzeDocument API with LAYOUT characteristic. Since most LLMs have a restricted token context window, we saved the chunk dimension small, about 250 characters with a bit overlap of fifty characters, utilizing LangChain’s RecursiveCharacterTextSplitter. This resulted in two separate units of doc chunks—one generated utilizing the uncooked textual content and the opposite utilizing the layout-aware linearized textual content. Each units of chunks had been saved in a vector database by producing vector embeddings utilizing the Amazon Titan Embeddings G1 Textual content embedding mannequin.
The next code snippet generates the uncooked textual content from the doc.
The output (trimmed for brevity) appears like the next. The textual content studying order is inaccurate because of the lack of structure consciousness of the API, and the extracted textual content spans the textual content columns.
The visible of the studying order for uncooked textual content extracted by DetectDocumentText could be seen within the following picture.

The next code snippet generates the layout-linearized textual content from the doc. You should use both methodology to generate the linearized textual content from the doc utilizing the newest model of Amazon Textract Textractor Python library.
The output (trimmed for brevity) appears like the next. The textual content studying order is preserved since we used the LAYOUT characteristic, and the textual content makes extra sense.
The visible of the studying order for uncooked textual content extracted by AnalyzeDocument with LAYOUT characteristic could be seen within the following picture.

We carried out chunking on each the extracted textual content individually, with a bit dimension of 250 and an overlap of fifty.
Subsequent, we generate vector embeddings for the chunks and cargo them right into a vector database in two separate collections. We used open supply ChromaDB as our in-memory vector database and used topK worth of three for the relevance search. Which means for each query, our relevance search question with ChromaDB returns 3 related chunks of textual content of dimension 250 every. These three chunks are then used to construct a context for the LLM. We deliberately selected a smaller chunk dimension and smaller topK to construct the context for the next particular causes.
- Shorten the general dimension of our context since analysis means that LLMs are likely to carry out higher with shorter context, though the mannequin helps longer context (via a bigger token context window).
- Smaller total immediate dimension ends in decrease total textual content technology mannequin latency. The bigger the general immediate dimension (which incorporates the context), the longer it could take the mannequin to generate a response.
- Adjust to the mannequin’s restricted token context window, as is the case with most LLMs.
- Value effectivity since utilizing fewer tokens means decrease value per query for enter and output tokens mixed.
Word that Anthropic Claude Immediate v1 does assist a 100,000 token context window by way of Amazon Bedrock. We deliberately restricted ourselves to a smaller chunk dimension since that additionally makes the take a look at related to fashions with fewer parameters and total shorter context home windows.
We used ROUGE metrics to guage machine-generated textual content towards a reference textual content (or floor reality), measuring varied features just like the overlap of n-grams, phrase sequences, and phrase pairs between the 2 texts. We selected three ROUGE metrics for analysis.
- ROUGE-1: Compares the overlap of unigrams (single phrases) between the generated textual content and a reference textual content.
- ROUGE-2: Compares the overlap of bigrams (two-word sequences) between the generated textual content and a reference textual content.
- ROUGE-L: Measures the longest widespread subsequence (LCS) between the generated textual content and a reference textual content, specializing in the longest sequence of phrases that seem in each texts, albeit not essentially consecutively.
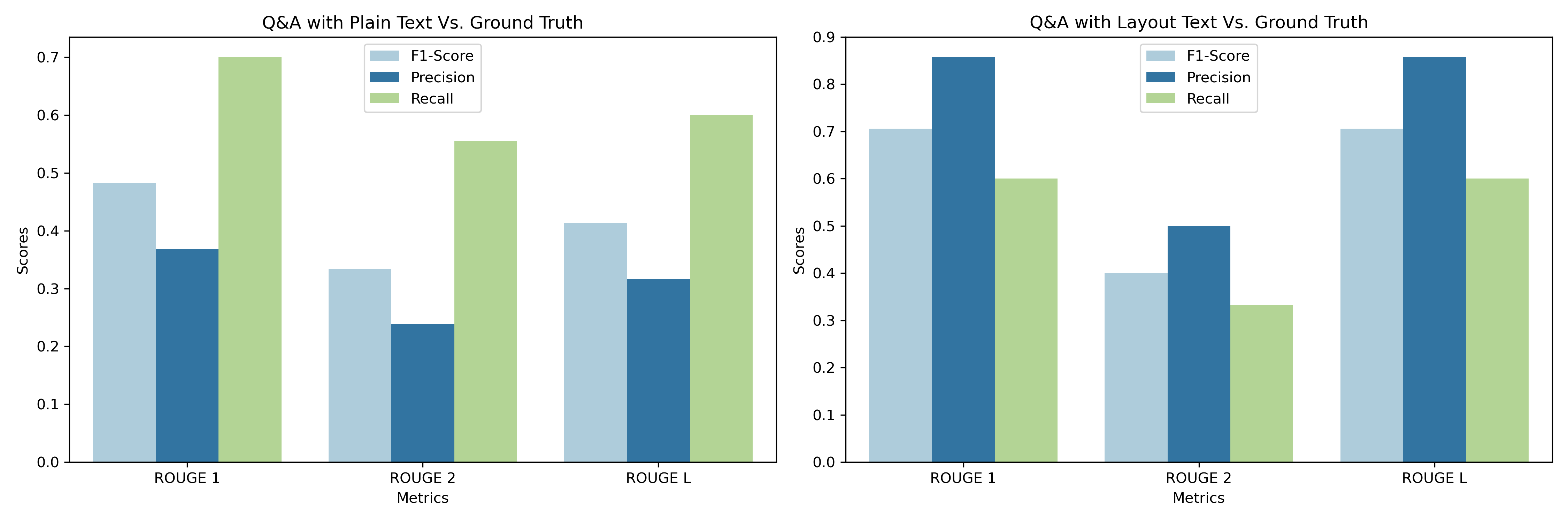
For our 20 pattern questions related to the doc, we ran Q&A with the uncooked textual content and linearized textual content, respectively, after which ran the ROUGE rating evaluation. We seen virtually 50 p.c common enchancment in precision total. And there was vital enchancment in F1-scores when layout-linearized textual content was in comparison with floor reality versus when uncooked textual content was in comparison with floor reality.
This implies that the mannequin grew to become higher at producing appropriate responses with the assistance of linearized textual content and smaller chunking. This led to a rise in precision, and the stability between precision and recall shifted favorably in direction of precision, resulting in a rise within the F1 rating. The elevated F1 rating, which balances precision and recall, suggests an enchancment. It’s important to think about the sensible implications of those metric adjustments. For example, in a state of affairs the place false positives are expensive, the rise in precision is very helpful.
ANLS rating evaluation on extractive duties over tutorial datasets
We measure the ANLS or the Common Normalized Levenshtein Similarity, which is an edit distance metric that was launched by the paper Scene Textual content Visible Query Answering and goals to softly penalize minor OCR imperfections whereas contemplating the mannequin’s reasoning skills on the similar time. This metric is a spinoff model of conventional Levenshtein distance, which is a measure of the distinction between two sequences (corresponding to strings). It’s outlined because the minimal variety of single-character edits (insertions, deletions, or substitutions) required to alter one phrase into the opposite.
For our ANLS exams, we carried out an NER job the place the LLM was prompted to extract the precise worth from the OCR-extracted textual content. The 2 tutorial datasets used for the exams are DocVQA and InfographicVQA. We used zero-shot prompting to try extraction of key entities. The immediate used for the LLMs is of the next construction.
Accuracy enhancements had been noticed in all doc question-answering datasets examined with the open supply FlanT5-XL mannequin when utilizing layout-aware linearized textual content, versus uncooked textual content (raster scan), in response to zero-shot prompts. Within the InfographicVQA dataset, utilizing layout-aware linearized textual content allows the smaller 3B parameter FlanT5-XL mannequin to match the efficiency of the bigger FlanT5-XXL mannequin (on uncooked textual content), which has practically 4 occasions as many parameters (11B).
| Dataset | ANLS* | |||||
| FlanT5-XL (3B) | FlanT5-XXL (11B) | |||||
| Not Structure-aware (Raster) | Structure-aware | Δ | Not Structure- conscious (Raster) | Structure-aware | Δ | |
| DocVQA | 66.03% | 68.46% | 1.43% | 70.71% | 72.05% | 1.34% |
| InfographicsVQA | 29.47% | 35.76% | 6.29% | 37.82% | 45.61% | 7.79% |
* ANLS is measured on textual content extracted by Amazon Textract, not the supplied doc transcription
Conclusion
The launch of Structure marks a big development in utilizing Amazon Textract to construct doc automation options. As mentioned on this publish, Structure makes use of conventional and generative AI strategies to enhance efficiencies when constructing all kinds of doc automation options corresponding to doc search, contextual Q&A, summarization, key-entities extraction, and extra. As we proceed to embrace the ability of AI in constructing doc processing and understanding programs, these enhancements will little doubt pave the best way for extra streamlined workflows, larger productiveness, and extra insightful information evaluation.
For extra data on the Structure characteristic and make the most of the characteristic for doc automation options, seek advice from AnalyzeDocument, Structure evaluation, and Textual content linearization for generative AI purposes documentation.
Concerning the Authors
 Anjan Biswas is a Senior AI Providers Options Architect who focuses on pc imaginative and prescient, NLP, and generative AI. Anjan is a part of the worldwide AI companies specialist workforce and works with prospects to assist them perceive and develop options to enterprise issues with AWS AI Providers and generative AI.
Anjan Biswas is a Senior AI Providers Options Architect who focuses on pc imaginative and prescient, NLP, and generative AI. Anjan is a part of the worldwide AI companies specialist workforce and works with prospects to assist them perceive and develop options to enterprise issues with AWS AI Providers and generative AI.
 Lalita Reddi is a Senior Technical Product Supervisor with the Amazon Textract workforce. She is concentrated on constructing machine studying–based mostly companies for AWS prospects. In her spare time, Lalita likes to play board video games and go on hikes.
Lalita Reddi is a Senior Technical Product Supervisor with the Amazon Textract workforce. She is concentrated on constructing machine studying–based mostly companies for AWS prospects. In her spare time, Lalita likes to play board video games and go on hikes.
 Edouard Belval is a Analysis Engineer within the pc imaginative and prescient workforce at AWS. He’s the primary contributor behind the Amazon Textract Textractor library.
Edouard Belval is a Analysis Engineer within the pc imaginative and prescient workforce at AWS. He’s the primary contributor behind the Amazon Textract Textractor library.

/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



