


Pre-training massive fashions on time sequence knowledge faces a number of challenges: the shortage of a complete public time sequence repository, the complexity of various time sequence traits, and the infancy of experimental benchmarks for mannequin analysis, particularly beneath resource-constrained and minimally supervised situations. Regardless of these hurdles, time sequence evaluation stays important throughout functions like climate forecasting, coronary heart price irregularity detection, and anomaly identification in software program deployments. Using pre-trained language, imaginative and prescient, and video fashions presents promise, although adaptation to time sequence knowledge specifics is important for optimum efficiency.
Making use of transformers to time sequence evaluation presents challenges because of the quadratic development of the self-attention mechanism with enter token dimension. Treating time sequence sub-sequences as tokens enhances effectivity and effectiveness in forecasting. Using cross-modal switch studying from language fashions, ORCA extends pre-trained fashions to various modalities by align-then-refine fine-tuning. Latest research have utilized this method to reprogram language pre-trained transformers for time sequence evaluation, albeit resource-intensive fashions require substantial reminiscence and computational sources for optimum efficiency.
Researchers from Carnegie Mellon College and the College of Pennsylvania current MOMENT, an open-source household of basis fashions for general-purpose time sequence evaluation. It makes use of the Time sequence Pile, a various assortment of public time sequence, to handle time series-specific challenges and allow large-scale multi-dataset pretraining. These high-capacity transformer fashions are pre-trained utilizing a masked time sequence prediction activity on in depth knowledge from numerous domains, providing versatility and robustness in tackling various time sequence evaluation duties.
MOMENT begins by assembling a various assortment of public time sequence knowledge referred to as the Time Collection Pile, combining datasets from numerous repositories to handle the shortage of complete time-series datasets. These datasets embody long-horizon forecasting, short-horizon forecasting, classification, and anomaly detection duties. MOMENT’s structure entails a transformer encoder and a light-weight reconstruction head pre-trained on a masked time sequence prediction activity. The pre-training setup contains variations of MOMENT comparable to completely different sizes of encoders, skilled with Adam optimizer and gradient checkpointing for reminiscence optimization. MOMENT is designed for fine-tuning downstream duties comparable to forecasting, classification, anomaly detection, and imputation, both end-to-end or with linear probing, relying on the duty necessities.

The research compares MOMENT with state-of-the-art deep studying and statistical machine studying fashions throughout numerous duties, opposite to TimesNet, which primarily focuses on transformer-based approaches. These comparisons are important for evaluating the sensible applicability of the proposed strategies. Apparently, statistical and non-transformer-based strategies, comparable to ARIMA for short-horizon forecasting, N-BEATS for long-horizon forecasting, and k-nearest neighbors for anomaly detection, exhibit superior efficiency over many deep studying and transformer-based fashions.
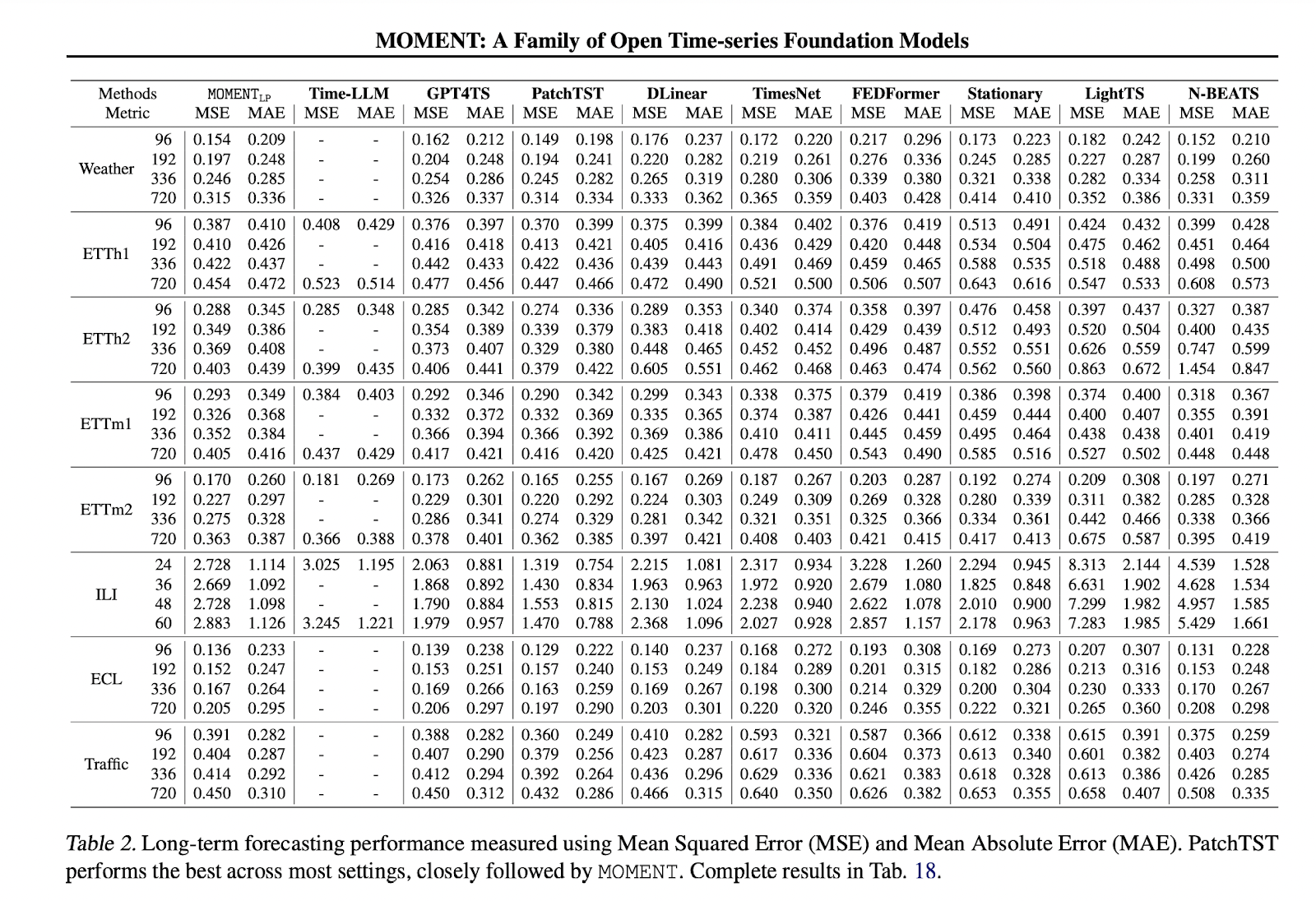
To recapitulate, this analysis presents MOMENT, the primary open-source household of time sequence basis fashions developed by complete phases of knowledge compilation, mannequin pre-training, and systematic addressing of time series-specific challenges. By using the Time Collection Pile and modern methods, MOMENT demonstrates excessive efficiency in pre-training transformer fashions of varied sizes. Additionally, the research designs an experimental benchmark for evaluating time sequence basis fashions throughout a number of sensible duties, significantly emphasizing situations with restricted computational sources and supervision. MOMENT displays effectiveness throughout numerous duties, showcasing superior efficiency, particularly in anomaly detection and classification, attributed to its pre-training. The analysis additionally underscores the viability of smaller statistical and shallower deep studying strategies throughout many duties. Finally, the research goals to advance open science by releasing the Time Collection Pile, together with code, mannequin weights, and coaching logs, fostering collaboration and additional developments in time sequence evaluation.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 42k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



