


Pure Language Processing (NLP) is a important space of synthetic intelligence that focuses on the interplay between computer systems and human language. It includes creating algorithms and fashions that allow computer systems to grasp, interpret, and generate human language. This know-how finds purposes in numerous domains, comparable to machine translation, sentiment evaluation, and data retrieval.
What presents a problem is the analysis of long-context language fashions. These fashions are essential for duties that require understanding and producing textual content primarily based on in depth context. Nevertheless, they usually need assistance sustaining consistency and accuracy over lengthy passages, resulting in potential errors and inefficiencies in purposes requiring deep contextual understanding.
Current analysis contains frameworks like “needle-in-a-haystack” (NIAH) for long-context language mannequin analysis. Fashions comparable to GPT-4 and RULER are evaluated utilizing these strategies. These frameworks usually contain artificial duties generated programmatically or by language fashions, which might lack real-world complexity. Benchmarks like NIAH and its variants should absolutely seize the nuances of narrative textual content, usually failing in international reasoning duties. This artificial nature of present strategies limits their effectiveness in assessing true language comprehension.
Researchers from UMass Amherst, Allen Institute for AI, and Princeton College have launched a brand new analysis methodology known as NOCHA (Narrative Open-Contextualized Human Annotation). This strategy is designed to evaluate the efficiency of long-context language fashions extra precisely. NOCHA includes gathering minimal narrative pairs, the place one declare is true, and the opposite is fake, each written by readers of books.
The NOCHA methodology includes gathering narrative minimal pairs from just lately printed fictional books. Annotators acquainted with these books generate pairs of true and false claims primarily based on the content material. This dataset contains 1,001 pairs derived from 67 books used to judge fashions like GPT-4 and RULER. Every mannequin is prompted with these claims and all the ebook content material to confirm the claims. The method ensures fashions are examined on reasonable, contextually wealthy eventualities. Knowledge assortment and high quality management contain a number of annotators and in depth evaluations to keep up excessive accuracy in declare verification.
The analysis demonstrated that present long-context language fashions, together with GPT-4 and its variants, obtain various levels of accuracy. For instance, GPT-4 attained an accuracy of 76.7% on balanced information however solely 55.8% when correct context utilization was required. This outcome signifies a considerable hole between human and mannequin efficiency, highlighting the necessity for additional developments.
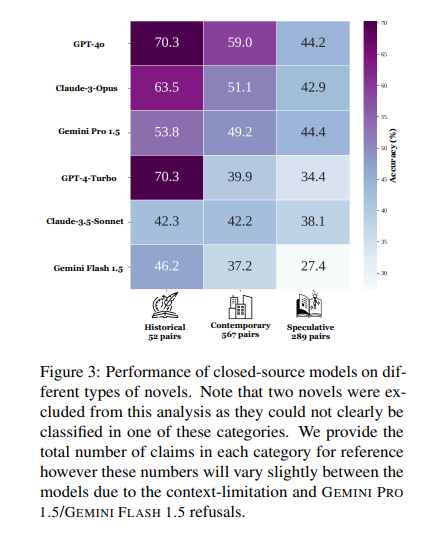
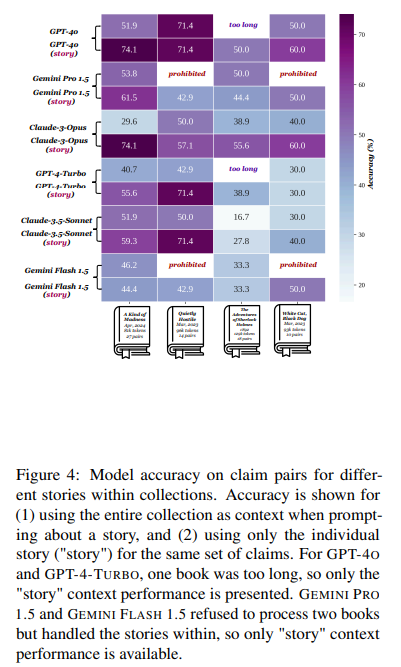
The efficiency of those fashions was evaluated on numerous metrics, together with their potential to confirm claims about ebook content material precisely. Human readers achieved a declare verification accuracy of 96.9%, considerably greater than the best-performing mannequin. This outcome underscores the fashions’ struggles with duties that require international reasoning over prolonged contexts as an alternative of straightforward sentence-level retrieval.
In conclusion, the analysis identifies important challenges in evaluating long-context language fashions and introduces a novel methodology to handle these points. The NOCHA strategy affords a extra reasonable and rigorous framework for testing these fashions, offering helpful insights into their strengths and limitations. This work emphasizes the significance of creating extra subtle analysis strategies to advance the sector of NLP.
Try the Paper, GitHub, and Leaderboard. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 45k+ ML SubReddit
🚀 Create, edit, and increase tabular information with the primary compound AI system, Gretel Navigator, now typically obtainable! [Advertisement]
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.



/cdn.vox-cdn.com/uploads/chorus_asset/file/23932925/acastro_STK108__03.jpg)


