


Pure language processing (NLP) is a department of synthetic intelligence specializing in the interplay between computer systems and people utilizing pure language. This area goals to develop algorithms and fashions that perceive, interpret, and generate human language, facilitating human-like interactions between techniques and customers. NLP encompasses varied purposes, together with language translation, sentiment evaluation, and conversational brokers, considerably enhancing how we work together with know-how.
Regardless of the developments in NLP, language fashions are nonetheless weak to malicious assaults that exploit their weaknesses. These assaults, referred to as jailbreaks, manipulate fashions to generate dangerous or undesirable outputs, elevating substantial issues in regards to the security and reliability of NLP techniques. Addressing these vulnerabilities is essential for making certain the accountable deployment of language fashions in real-world purposes.
Present analysis contains conventional strategies like using human evaluators, gradient-based optimization, and iterative revisions with LLMs. Automated red-teaming and jailbreaking strategies have additionally been developed, together with gradient optimization strategies, inference-based approaches, and assault era strategies reminiscent of AUTO DAN and PAIR. Different research give attention to decoding configurations, multilingual settings, and programming modes. Frameworks embrace Security-Tuned LLaMAs and BeaverTails, which offer small-scale security coaching datasets and large-scale pairwise desire datasets, respectively. Whereas these approaches have contributed to mannequin robustness, they have to enhance their skill to seize the complete spectrum of potential assaults encountered in various, real-world situations. Consequently, there’s a urgent want for extra complete and scalable options.
Researchers from the College of Washington, the Allen Institute for Synthetic Intelligence, Seoul Nationwide College, and Carnegie Mellon College have launched “WILDTEAMING,” an modern red-teaming framework designed to routinely uncover and compile novel jailbreak techniques from in-the-wild user-chatbot interactions. This technique leverages real-world information to reinforce the detection and mitigation of mannequin vulnerabilities. WILDTEAMING includes a two-step course of: mining real-world person interactions to determine potential jailbreak methods and composing these methods into various adversarial assaults to systematically check language fashions.
The WILDTEAMING framework begins by mining a big dataset of person interactions to uncover varied jailbreak techniques, categorizing them into 5.7K distinctive clusters. This in depth mining course of reveals varied human-devised jailbreak techniques from real-world person chatbot interactions. Subsequent, the framework composes these techniques with dangerous queries to create a broad vary of difficult adversarial assaults. Combining totally different techniques alternatives, the framework systematically explores novel and extra complicated jailbreaks, considerably increasing the present understanding of mannequin vulnerabilities. This method permits researchers to determine beforehand unnoticed vulnerabilities, offering a extra thorough evaluation of mannequin robustness.
The researchers demonstrated that WILDTEAMING may generate as much as 4.6 occasions extra various and profitable adversarial assaults than earlier strategies. This framework facilitated the creation of WILDJAILBREAK, a considerable open-source dataset containing 262,000 prompt-response pairs. These pairs embrace each vanilla (direct request) and adversarial (complicated jailbreak) queries, offering a wealthy useful resource for coaching fashions to successfully deal with a variety of dangerous and benign inputs. The dataset’s composition permits for analyzing the interaction between information properties and mannequin capabilities throughout security coaching. This ensures that fashions can safeguard towards direct and delicate threats with out compromising efficiency.
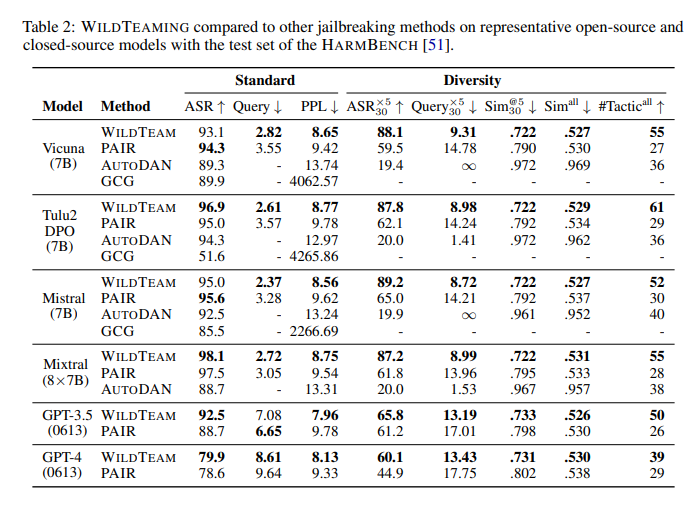
The efficiency of the fashions educated utilizing WILDJAILBREAK was noteworthy. The improved coaching led to fashions that might stability security with out over-refusal of benign queries, sustaining their basic capabilities. In in depth mannequin coaching and evaluations, the researchers recognized properties that allow a super stability of security behaviors, efficient dealing with of vanilla and adversarial queries, and minimal lower on the whole capabilities. These outcomes underscore the significance of complete and high-quality coaching information in growing sturdy and dependable NLP techniques.
To conclude, the researchers successfully addressed the problem of language mannequin vulnerabilities by introducing a scalable and systematic technique for locating and mitigating jailbreak techniques. By means of the WILDTEAMING framework and the WILDJAILBREAK dataset, their method gives a strong basis for growing safer and extra dependable NLP techniques. This development represents a big step in direction of enhancing the safety and performance of AI-driven language fashions. The analysis underscores the need of ongoing efforts to enhance mannequin security and the worth of leveraging real-world information to tell these enhancements.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 45k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.



/cdn.vox-cdn.com/uploads/chorus_asset/file/23932925/acastro_STK108__03.jpg)


