


The sphere of analysis focuses on optimizing algorithms for coaching giant language fashions (LLMs), that are important for understanding and producing human language. These fashions are important for numerous functions, together with pure language processing and synthetic intelligence. Coaching LLMs requires vital computational sources and reminiscence, making optimizing these processes a high-priority space for researchers.
The first drawback addressed by this paper is the excessive reminiscence demand of optimization algorithms utilized in coaching giant language fashions. Particularly, the Adam optimizer, a typical within the subject resulting from its superior efficiency, requires substantial reminiscence to retailer optimizer states corresponding to first-order and second-order momentum values. This reminiscence demand doubles the required sources in comparison with the mannequin measurement, creating a major burden. Because of this, coaching giant fashions turns into costly and fewer accessible to researchers with restricted sources. Various strategies like Adafactor try to scale back reminiscence utilization however usually compromise efficiency, highlighting the necessity for extra environment friendly options.
The Adam optimizer is broadly used for coaching LLMs due to its skill to deal with numerous mannequin sizes and duties successfully. Nonetheless, Adam’s requirement for intensive reminiscence to retailer its optimizer states, notably the first-order and second-order momentums, poses a substantial problem. As an example, coaching a 7 billion parameter mannequin with Adam requires about 56 GB per card for these states alone, totaling 86 GB when gradients are included. This makes coaching prohibitively costly, even with superior graphical playing cards just like the A100-80GB. Moreover, CPU-offloading and sharding are employed to handle this excessive reminiscence requirement, rising latency and slowing down the coaching course of.
Researchers from The Chinese language College of Hong Kong, Shenzhen, Shenzhen Analysis Institute of Large Knowledge, Duke College, and Stanford College launched Adam-mini, an optimizer designed to realize comparable or higher efficiency than Adam whereas decreasing reminiscence utilization by 45% to 50%. Adam-mini accomplishes this by partitioning mannequin parameters into blocks primarily based on the Hessian construction of transformers. Every block is then assigned a single high-quality studying charge, considerably decreasing the variety of studying charges from billions to a manageable quantity. This method permits Adam-mini to take care of and even enhance efficiency with a fraction of the reminiscence required by Adam.
Adam-mini works by leveraging the near-block diagonal construction of transformers’ Hessians, partitioning parameters into blocks corresponding to Question, Key, Worth, and MLP layers. For every block, a single efficient studying charge is calculated utilizing the common of Adam’s second-order momentum values in that block. This methodology reduces the reminiscence footprint and simplifies the educational charge project course of. For instance, in the course of the pre-training of Llama2-7B on two A800-80GB GPUs, Adam-mini achieved a throughput of 5572.19 tokens per second, in comparison with 3725.59 tokens per second with AdamW, representing a 49.6% enhance. This effectivity ends in a 33% discount in wall-clock time for processing the identical variety of tokens.
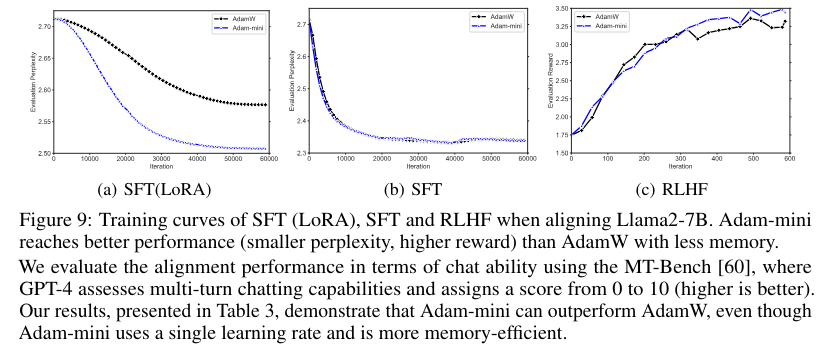
The researchers validated Adam-mini’s efficiency throughout numerous language fashions starting from 125 million to 7 billion parameters, together with pre-training, supervised fine-tuning (SFT), and reinforcement studying from human suggestions (RLHF). The optimizer demonstrated on-par or superior efficiency to AdamW, with notable enhancements in reminiscence effectivity and coaching velocity. As an example, in supervised fine-tuning and reinforcement studying duties, Adam-mini persistently outperformed AdamW, reaching greater analysis scores and sooner convergence.

In conclusion, the Adam-mini optimizer addresses the numerous reminiscence inefficiencies of conventional optimization strategies like Adam by introducing a novel partitioning technique primarily based on the Hessian construction of fashions. This progressive method ends in substantial reminiscence financial savings and improved coaching effectivity, making it a invaluable instrument for researchers working with large-scale language fashions. By decreasing the reminiscence footprint by as much as 50% and rising throughput by practically 50%, Adam-mini not solely enhances the feasibility of coaching giant fashions but additionally encourages broader participation from researchers with restricted GPU sources.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Overlook to hitch our 45k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.




/cdn.vox-cdn.com/uploads/chorus_asset/file/23932925/acastro_STK108__03.jpg)
