


Have you ever ever questioned what it could be prefer to have a super-intelligent AI assistant who not solely has huge information but in addition understands and respects your values, ethics, and preferences? A crew of researchers might have cracked the code on making this sci-fi fantasy a actuality.
Think about having an AI companion that’s extraordinarily succesful, but operates with the identical ethical compass as you. It could by no means lie, mislead, or act towards your pursuits. It could be sure by the identical ideas of honesty, integrity, and kindness that you simply maintain pricey. Sounds too good to be true? Nicely, the researchers at Upstage AI have developed an modern method that brings us one step nearer to reaching this long-sought concord between synthetic and human intelligence.
Their method, referred to as “stepwise Direct Choice Optimization” (sDPO), is an ingenious technique to align giant language fashions with human values and preferences. These fashions are the powerhouses behind AI assistants like ChatGPT. Whereas extraordinarily succesful, they will typically reply in ways in which appear at odds with what a human would like.
The important thing perception behind sDPO is to make use of a curriculum-style studying course of to steadily instill human preferences into the mannequin. It really works like this: The researchers first gather information capturing human preferences on what constitutes good vs. dangerous responses to questions. This information is then cut up into chunks.
Within the first part, the AI mannequin is skilled on the primary chunk whereas utilizing its unique, unrefined self as a reference level. This permits it to turn into barely extra aligned with human preferences than it was earlier than. Within the subsequent part, this extra aligned model of the mannequin now turns into the brand new reference level. It’s skilled on the second chunk of desire information, pushing it to turn into even higher aligned.
This stepwise course of continues till all of the desire information has been consumed. At every step, the mannequin is nudged increased and better, climbing in direction of higher concord with human values and ethics. It’s nearly like a seasoned human mentor passing on their knowledge to the mannequin, one step at a time.
The outcomes of the sDPO experiments are nothing wanting exceptional. By fine-tuning the ten.7 billion parameter SOLAR language mannequin utilizing sDPO and leveraging two desire datasets (OpenOrca and Ultrafeedback Cleaned), the researchers achieved a degree of efficiency that surpassed even bigger fashions like Mixtral 8x7B-Instruct-v0.1.
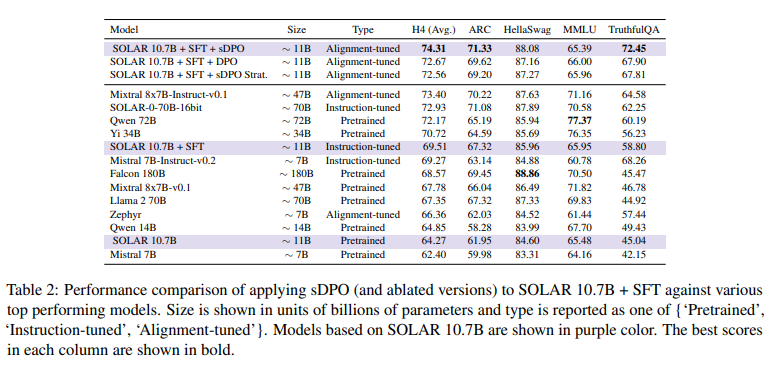
On the HuggingFace Open LLM Leaderboard, a benchmark for evaluating LLM efficiency, the sDPO-aligned SOLAR mannequin achieved a mean rating of 74.31 throughout a number of duties, outshining its bigger counterparts. However maybe much more spectacular was its efficiency on the TruthfulQA process, the place it scored a exceptional 72.45, showcasing its unwavering dedication to truthfulness – a core human worth.
Behind these groundbreaking outcomes lies a profound realization: efficient alignment tuning can unlock superior efficiency, even for smaller language fashions. By leveraging a extra aligned reference mannequin at every step, sDPO equips these fashions with the flexibility to refine their understanding of human values repeatedly, in the end enabling them to attain unprecedented ranges of functionality whereas remaining firmly grounded within the ideas that matter most to us.
Because the researchers themselves acknowledge, the trail to actually aligning AI with human values is an ongoing journey, one which requires a deeper understanding of dataset traits and their impression on efficiency. Nevertheless, the success of sDPO supplies a tantalizing glimpse right into a future the place synthetic intelligence and human knowledge coexist in good concord.
Think about a world the place AI programs not solely possess exceptional capabilities but in addition embody the very values and ideas that outline our humanity – a world the place machine intelligence is a mirrored image of our personal aspirations, hopes, and needs. With groundbreaking methods like sDPO, that future could also be nearer than we expect.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 39k+ ML SubReddit
Vineet Kumar is a consulting intern at MarktechPost. He’s at present pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s keen about analysis and the newest developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.

/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



