


Present multi-modal language fashions (LMs) face limitations in performing complicated visible reasoning duties. These duties, equivalent to compositional motion recognition in movies, demand an intricate mix of low-level object movement and interplay evaluation with high-level causal and compositional spatiotemporal reasoning. Whereas these fashions excel in varied areas, their effectiveness in duties requiring detailed consideration to fine-grained, low-level particulars alongside superior rationale has but to be totally explored or demonstrated, indicating a big hole of their capabilities.
Present analysis in multi-modal LMs is advancing with auto-regressive fashions and adapters for visible processing. Key image-based fashions embrace Pix2seq, ViperGPT, VisProg, Chameleon, PaLM-E, LLaMA-Adapter, FROMAGe, InstructBLIP, Qwen-VL, and Kosmos-2, whereas video-based fashions like Video-ChatGPT, VideoChat, Valley, and Flamingo are gaining consideration. Spatiotemporal video grounding is a brand new concentrate on object localization in media utilizing linguistic cues. Consideration-based fashions are pivotal on this analysis, using methods like multi-hop characteristic modulation and cascaded networks for enhanced visible reasoning.
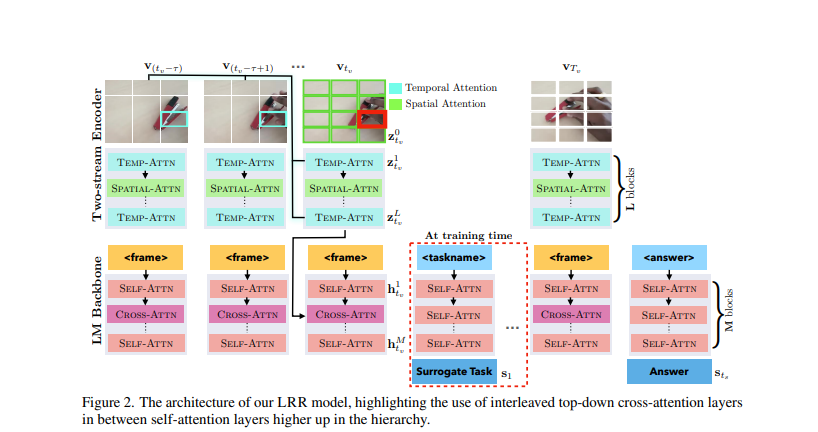
Researchers at Qualcomm AI Analysis have launched a multi-modal LM, skilled end-to-end on duties like object detection and monitoring, to enhance low-level visible abilities. It employs a two-stream video encoder with spatiotemporal consideration for static and movement cues, following a “Look, Bear in mind, Cause” course of.
The analysis focuses on enhancing a multi-model LM and makes use of ACRE, CATER, and STAR datasets. The surrogate duties of object recognition, re-identification, and figuring out the state of the blicket machine are launched throughout coaching with a likelihood of 30 after every context trial or question. Utilizing fewer parameters, the mannequin is skilled with the OPT-125M and OPT-1.3B architectures. The mannequin is skilled till convergence with a batch measurement of 4 utilizing the AdamW optimizer.
The LRR framework leads the STAR problem leaderboard as of January 2024, showcasing its superior efficiency in video reasoning. The mannequin’s effectiveness is confirmed throughout varied datasets like ACRE, CATER, and One thing-Else, indicating its adaptability and proficiency in processing low-level visible cues. The LRR mannequin’s end-to-end trainability and efficiency surpassing task-specific strategies underscore its functionality to boost video reasoning.
In conclusion, the framework follows a three-step “Look, Bear in mind, Cause” course of the place visible data is extracted utilizing low-level graphic abilities and built-in to reach at a closing reply. The LRR mannequin successfully captures static and motion-based cues in movies by a two-stream video encoder with spatiotemporal consideration. Future work might contain exploring the inclusion of datasets like ACRE by treating pictures as nonetheless movies, additional bettering the LRR mannequin’s efficiency. The LRR framework will be prolonged to different visible reasoning duties and datasets, doubtlessly enhancing its applicability and efficiency in a broader vary of eventualities.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter. Be part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our Telegram Channel
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



