


Picture by Freepik
Pure Language Processing, or NLP, is a subject inside synthetic intelligence for machines to have the power to grasp textual information. NLP analysis has existed for a very long time, however solely not too long ago has it change into extra distinguished with the introduction of huge information and better computational processing energy.
With the NLP subject changing into larger, many researchers would attempt to enhance the machine’s functionality to grasp the textual information higher. Via a lot progress, many strategies are proposed and utilized within the NLP subject.
This text will examine numerous strategies for processing textual content information within the NLP subject. This text will give attention to discussing RNN, Transformers, and BERT as a result of it’s the one that’s typically utilized in analysis. Let’s get into it.
Recurrent Neural Community or RNN was developed in 1980 however solely not too long ago gained attraction within the NLP subject. RNN is a specific kind inside the neural community household used for sequential information or information that may’t be unbiased of one another. Sequential information examples are time sequence, audio, or textual content sentence information, mainly any sort of information with significant order.
RNNs are totally different from common feed-forward neural networks as they course of data in a different way. Within the regular feed-forward, the knowledge is processed following the layers. Nevertheless, RNN is utilizing a loop cycle on the knowledge enter as consideration. To know the variations, let’s see the picture beneath.
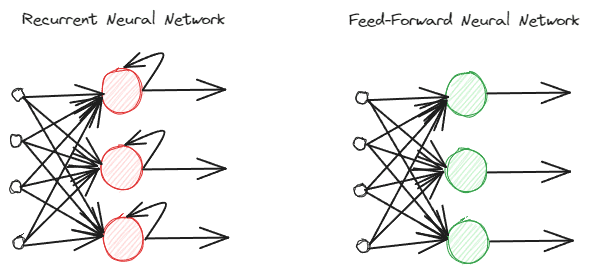
Picture by Creator
As you possibly can see, the RNNs mannequin implements a loop cycle through the data processing. RNNs would take into account the present and former information enter when processing this data. That’s why the mannequin is appropriate for any kind of sequential information.
If we take an instance within the textual content information, think about we have now the sentence “I get up at 7 AM”, and we have now the phrase as enter. Within the feed-forward neural community, after we attain the phrase “up,” the mannequin would already neglect the phrases “I,” “wake,” and “up.” Nevertheless, RNNs would use each output for every phrase and loop them again so the mannequin wouldn’t neglect.
Within the NLP subject, RNNs are sometimes utilized in many textual functions, equivalent to textual content classification and era. It’s typically utilized in word-level functions equivalent to A part of Speech tagging, next-word era, and many others.
Trying on the RNNs extra in-depth on the textual information, there are a lot of forms of RNNs. For instance, the beneath picture is the many-to-many varieties.
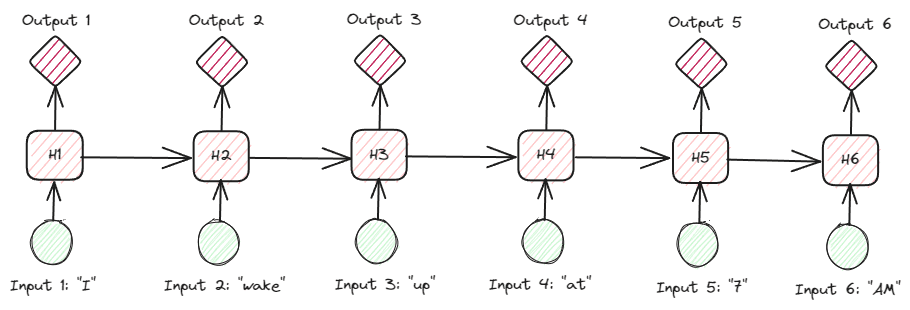
Picture by Creator
Trying on the picture above, we will see that the output for every step (time-step in RNN) is processed one step at a time, and each iteration at all times considers the earlier data.
One other RNN kind utilized in many NLP functions is the encoder-decoder kind (Sequence-to-Sequence). The construction is proven within the picture beneath.
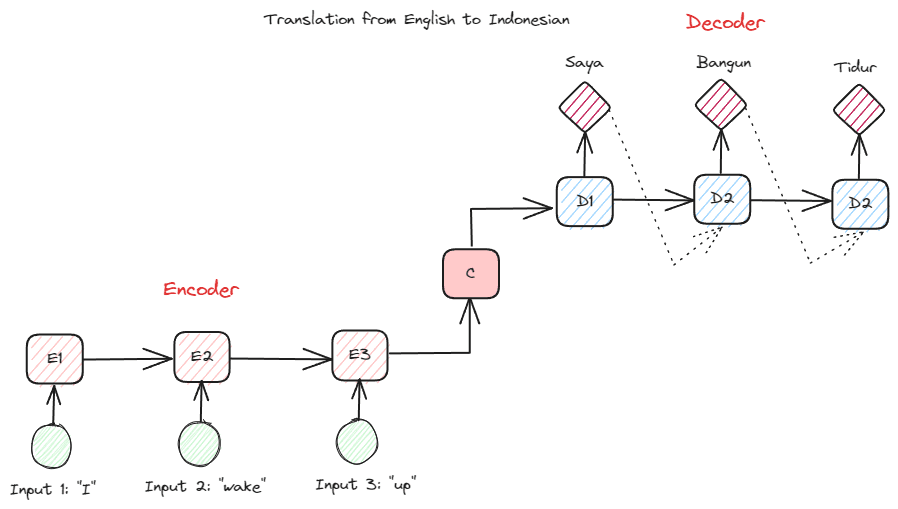
Picture by Creator
This construction introduces two components which can be used within the mannequin. The primary half known as Encoder, which is part that receives information sequence and creates a brand new illustration based mostly on it. The illustration can be used within the second a part of the mannequin, which is the decoder. With this construction, the enter and output lengths don’t essentially have to be equal. The instance use case is a language translation, which frequently doesn’t have the identical size between the enter and output.
There are numerous advantages of utilizing RNNs to course of pure language information, together with:
- RNN can be utilized to course of textual content enter with out size limitations.
- The mannequin shares the identical weights throughout on a regular basis steps, which permits the neural community to make use of the identical parameter in every step.
- Having the reminiscence of previous enter makes RNN appropriate for any sequential information.
However, there are a number of disadvantages as effectively:
- RNN is inclined to each vanishing and exploding gradients. That is the place the gradient result’s the near-zero worth (vanishing), inflicting community weight to solely be up to date for a tiny quantity, or the gradient result’s so important (exploding) that it assigns an unrealistic huge significance to the community.
- Very long time of coaching due to the sequential nature of the mannequin.
- Quick-term reminiscence signifies that the mannequin begins to neglect the longer the mannequin is educated. There’s an extension of RNN known as LSTM to alleviate this downside.
Transformers is an NLP mannequin structure that tries to unravel the sequence-to-sequence duties beforehand encountered within the RNNs. As talked about above, RNNs have issues with short-term reminiscence. The longer the enter, the extra distinguished the mannequin was in forgetting the knowledge. That is the place the eye mechanism might assist clear up the issue.
The eye mechanism is launched within the paper by Bahdanau et al. (2014) to unravel the lengthy enter downside, particularly with encoder-decoder kind of RNNs. I might not clarify the eye mechanism intimately. Principally, it’s a layer that enables the mannequin to give attention to the crucial a part of the mannequin enter whereas having the output prediction. For instance, the phrase enter “Clock” would correlate extremely with “Jam” in Indonesian if the duty is for translation.
The transformers mannequin is launched by Vaswani et al. (2017). The structure is impressed by the encoder-decoder RNN and constructed with the eye mechanism in thoughts and doesn’t course of information in sequential order. The general transformers mannequin is structured just like the picture beneath.
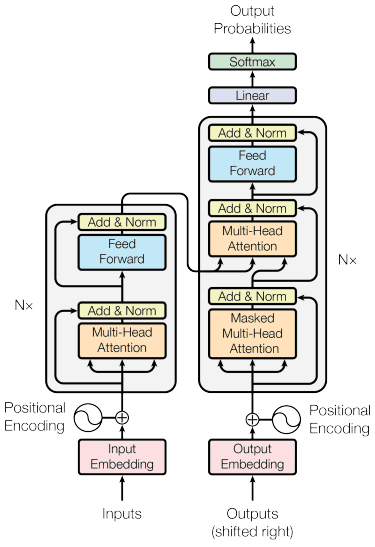
Transformers Structure (Vaswani et al. 2017)
Within the construction above, the transformers encode the info vector sequence into the phrase embedding with positional encoding in place whereas utilizing the decoding to remodel information into the unique type. With the eye mechanism in place, the encoding can given significance in response to the enter.
Transformers present few benefits in comparison with the opposite mannequin, together with:
- The parallelization course of will increase the coaching and inference velocity.
- Able to processing longer enter, which provides a greater understanding of the context
There are nonetheless some disadvantages to the transformers mannequin:
- Excessive computational processing and demand.
- The eye mechanism may require the textual content to be cut up due to the size restrict it could possibly deal with.
- Context may be misplaced if the cut up have been accomplished incorrect.
BERT
BERT, or Bidirectional Encoder Representations from Transformers, is a mannequin developed by Devlin et al. (2019) that includes two steps (pre-training and fine-tuning) to create the mannequin. If we examine, BERT is a stack of transformers encoder (BERT Base has 12 Layers whereas BERT Giant has 24 layers).
BERT’s general mannequin improvement may be proven within the picture beneath.
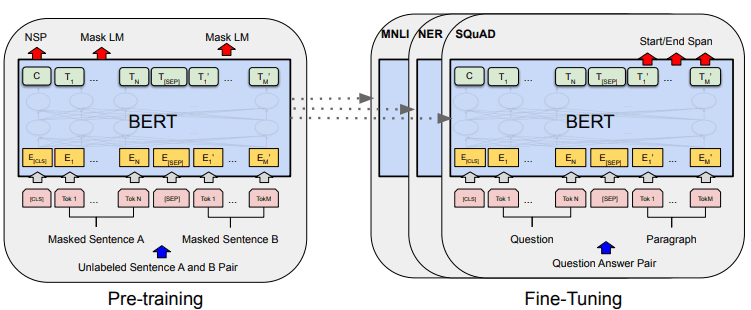
BERT general procedures (Devlin et al. (2019)
Pre-training duties provoke the mannequin’s coaching on the similar time, and as soon as it’s accomplished, the mannequin may be fine-tuned for numerous downstream duties (question-answering, classification, and many others.).
What makes BERT particular is that it’s the first unsupervised bidirectional language mannequin that’s pre-trained on textual content information. BERT was beforehand pre-trained on your entire Wikipedia and ebook corpus, consisting of over 3000 million phrases.
BERT is taken into account bidirectional as a result of it didn’t learn information enter sequentially (from left to proper or vice versa), however the transformer encoder learn the entire sequence concurrently.
In contrast to directional fashions, which learn the textual content enter sequentially (left-to-right or right-to-left), the Transformer encoder reads your entire sequence of phrases concurrently. That’s why the mannequin is taken into account bidirectional and permits the mannequin to grasp the entire context of the enter information.
To realize bidirectional, BERT makes use of two strategies:
- Masks Language Mannequin (MLM) — Phrase masking method. The method would masks 15% of the enter phrases and attempt to predict this masked phrase based mostly on the non-masked phrase.
- Subsequent Sentence Prediction (NSP) — BERT tries to study the connection between sentences. The mannequin has pairs of sentences as the info enter and tries to foretell if the next sentence exists within the authentic doc.
There are a number of benefits to utilizing BERT within the NLP subject, together with:
- BERT is straightforward to make use of for pre-trained numerous NLP downstream duties.
- Bidirectional makes BERT perceive the textual content context higher.
- It’s a well-liked mannequin that has a lot help from the group
Though, there are nonetheless a number of disadvantages, together with:
- Requires excessive computational energy and lengthy coaching time for some downstream job fine-tuning.
- The BERT mannequin may end in an enormous mannequin requiring a lot larger storage.
- It’s higher to make use of for advanced duties because the efficiency for easy duties will not be a lot totally different than utilizing easier fashions.
NLP has change into extra distinguished not too long ago, and far analysis has centered on bettering the functions. On this article, we focus on three NLP strategies which can be typically used:
- RNN
- Transformers
- BERT
Every of the strategies has its benefits and drawbacks, however general, we will see the mannequin evolving in a greater approach.
Cornellius Yudha Wijaya is an information science assistant supervisor and information author. Whereas working full-time at Allianz Indonesia, he likes to share Python and Information suggestions through social media and writing media.

/cdn.vox-cdn.com/uploads/chorus_asset/file/25520051/NASCAR_EV_car.jpg)



