


Finding out scaling legal guidelines in giant language fashions (LLMs) is essential for enhancing machine translation efficiency. Understanding these relationships is important for optimizing LLMs, enabling them to be taught from huge datasets and enhance in duties comparable to language translation, thereby pushing the boundaries of what’s achievable with present computational sources and knowledge availability.
Of all the most important challenges related to the sector, a key problem in advancing LLMs is figuring out the impact of pretraining knowledge measurement and its alignment with downstream duties, significantly in machine translation. The intricacies of how pretraining on various datasets influences mannequin efficiency on particular duties nonetheless must be explored. This challenge is vital because the pretraining part considerably impacts the mannequin’s potential to know and translate languages successfully.
Current methods for enhancing LLM efficiency primarily deal with adjusting the scale of the pretraining datasets and the mannequin structure. These strategies make use of upstream metrics like perplexity or cross-entropy loss to gauge mannequin enhancements throughout pretraining. Nevertheless, these metrics might circuitously translate to raised efficiency on downstream duties comparable to translation. Thus, there’s a urgent want for extra focused approaches that contemplate the downstream job efficiency, particularly metrics like BLEU scores, which extra precisely replicate the interpretation high quality of fashions.
Researchers from Stanford College and Google Analysis have developed new scaling legal guidelines that predict the interpretation high quality of LLMs primarily based on pretraining knowledge measurement. These legal guidelines illustrate that the BLEU rating adheres to a log whereas cross-entropy follows an influence regulation. They spotlight that cross-entropy might not reliably point out downstream efficiency, with BLEU rating developments offering a extra correct evaluation of the worth of pretraining knowledge. This framework provides a way to judge whether or not pretraining aligns with the duty, guiding efficient knowledge utilization for enhancing mannequin efficiency.
The analysis makes use of a 3-billion T5 encoder-decoder mannequin pretraining on MC4 dataset sections (English, German, French, Romanian), adopted by finetuning on chosen checkpoints. It investigates translation duties throughout various dataset sizes, using particular hyperparameters like batch measurement and studying price. Outcomes embody scaling regulation coefficients optimized through Huber loss and L-BFGS algorithm, with prediction errors detailed in appendices. This experimental framework underscores the nuanced affect of pretraining knowledge measurement and alignment on translation efficiency.
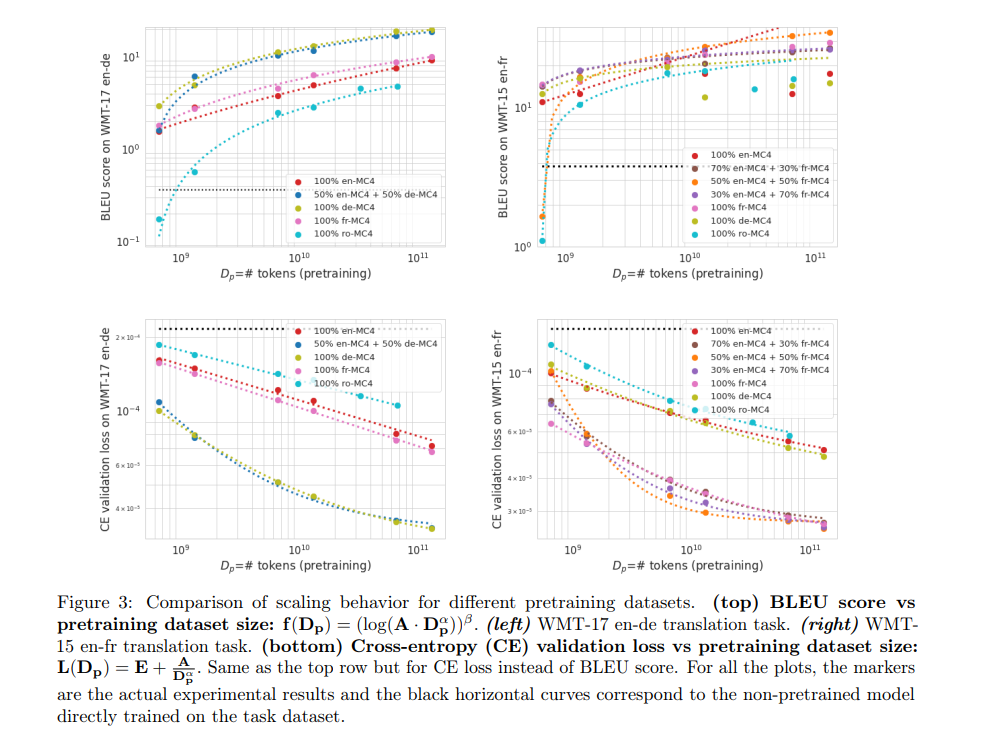
The outcomes reveal that bigger finetuning datasets enhance BLEU scores and cut back cross-entropy loss, particularly notable in smaller datasets the place pretraining’s affect is important. Pretraining proves redundant with ample finetuning knowledge. Misaligned pretraining datasets adversely have an effect on efficiency, emphasizing the significance of knowledge alignment. English-to-German translations exhibit constant metric correlations, not like English-to-French, questioning cross-entropy’s reliability as a efficiency indicator. Pretraining advantages fluctuate by language, with German or French exhibiting benefits over English, indicating the nuanced effectiveness of scaling legal guidelines in predicting mannequin habits throughout totally different translation duties.
In conclusion, by introducing and validating new scaling legal guidelines, the analysis group supplies a useful framework for predicting mannequin efficiency, providing a pathway to more practical and environment friendly mannequin coaching. The research’s revelations concerning the vital function of knowledge alignment in attaining optimum mannequin efficiency illuminate a path ahead for future analysis and growth in LLMs, highlighting the potential for these fashions to revolutionize language translation by way of knowledgeable and strategic knowledge utilization.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and Google Information. Be part of our 37k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to affix our Telegram Channel
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



