


Mathematical reasoning has lengthy been a crucial space of analysis inside laptop science. With the development of enormous language fashions (LLMs), there was important progress in automating mathematical problem-solving. This includes the event of fashions that may interpret, resolve, and clarify complicated mathematical issues, making these applied sciences more and more related in instructional and sensible functions. LLMs are remodeling how we strategy mathematical schooling and analysis, offering instruments that improve understanding and effectivity.
A serious problem in mathematical reasoning is guaranteeing that fashions can deal with multi-turn interactions. Conventional benchmarks usually consider fashions based mostly on their capability to unravel single-turn questions. Nonetheless, real-world situations typically require sustained reasoning and the power to observe directions throughout a number of interactions. This complexity necessitates superior capabilities in dialogue understanding and dynamic problem-solving. Making certain that fashions can handle these complicated duties is essential for his or her utility in instructional instruments, automated tutoring programs, and interactive problem-solving assistants.
Current frameworks for mathematical reasoning in massive language fashions (LLMs) embrace benchmarks like GSM8K, MATH, and SVAMP, which consider single-turn query answering. Distinguished fashions similar to MetaMath, WizardMath, and DeepSeek-Math concentrate on bettering efficiency via methods like Chain of Thought (CoT) prompting, artificial information distillation, and in depth pre-training on math-related corpora. These strategies improve fashions’ skills in fixing remoted math issues however want to enhance in evaluating multi-turn, dialogue-based interactions important for real-world functions.
Researchers from the College of Notre Dame staff and Tencent AI Lab have launched a brand new benchmark named MathChat to deal with this hole. MathChat evaluates LLMs’ efficiency in multi-turn interactions and open-ended question-answering. This benchmark goals to push the boundaries of what LLMs can obtain in mathematical reasoning by specializing in dialogue-based duties. MathChat consists of duties impressed by instructional methodologies, similar to follow-up questioning and error correction, that are crucial for growing fashions that may perceive and reply to dynamic mathematical queries.
The MathChat benchmark consists of follow-up question-answering, error correction, evaluation, and downside era. These duties require fashions to interact in multi-turn dialogues, determine and proper errors, analyze errors, and generate new issues based mostly on given options. This complete strategy ensures that fashions are examined on numerous skills past easy problem-solving. By encompassing a number of points of mathematical reasoning, MathChat gives a extra correct evaluation of a mannequin’s capabilities in dealing with real-world mathematical interactions.
Of their experiments, the researchers discovered that whereas present state-of-the-art LLMs carry out nicely on single-turn duties, they battle considerably with multi-turn and open-ended duties. As an example, fashions fine-tuned on in depth single-turn QA information confirmed restricted capability to deal with the extra complicated calls for of MathChat. Introducing an artificial dialogue-based dataset, MathChatsync, considerably improved mannequin efficiency, highlighting the significance of coaching with numerous conversational information. This dataset focuses on bettering interplay and instruction-following capabilities, important for multi-turn reasoning.
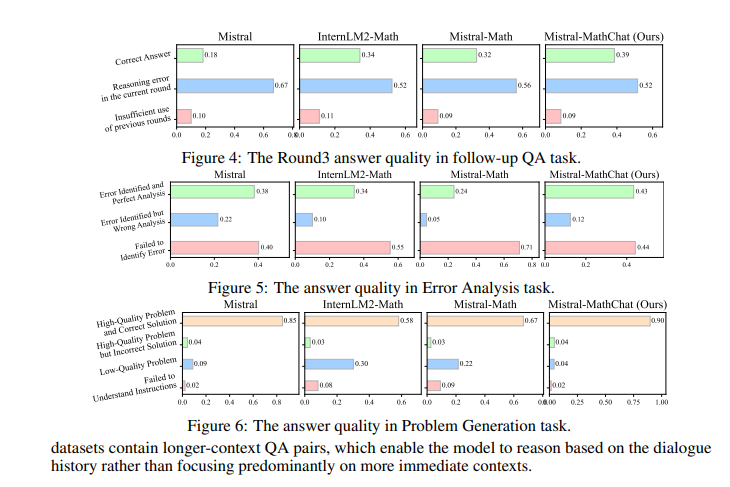
The researchers evaluated numerous LLMs on the MathChat benchmark, observing that whereas these fashions excel in single-turn query answering, they underperform in situations requiring sustained reasoning and dialogue understanding. For instance, MetaMath achieved 77.18% accuracy within the first spherical of follow-up QA however dropped to 32.16% within the second spherical and 19.31% within the third. Equally, WizardMath began with 83.20% accuracy, which fell to 44.81% and 36.86% in subsequent rounds. DeepSeek-Math and InternLM2-Math additionally exhibited important efficiency drops in multi-round interactions, with the latter attaining 83.80% accuracy in single-round duties however a lot decrease in follow-up rounds. The MathChatsync fine-tuning led to substantial enhancements: Mistral-MathChat achieved an general common rating of 0.661, in comparison with 0.623 for Gemma-MathChat, indicating the effectiveness of numerous, dialogue-based coaching information.
In conclusion, this analysis identifies a crucial hole in present LLM capabilities and proposes a brand new benchmark and dataset to deal with this problem. The MathChat benchmark and MathChatsync dataset characterize important steps in growing fashions that may successfully interact in multi-turn mathematical reasoning, paving the way in which for extra superior and interactive AI functions in arithmetic. The examine highlights the need of numerous coaching information and complete analysis to boost the capabilities of LLMs in real-world mathematical problem-solving situations. This work underscores the potential for LLMs to remodel mathematical schooling and analysis by offering extra interactive and efficient instruments.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Neglect to hitch our 43k+ ML SubReddit | Additionally, try our AI Occasions Platform
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.

/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



