


Choice tree learners are highly effective classifiers that make the most of a tree construction to mannequin the relationships among the many options and the potential outcomes. This construction earned its title as a result of the truth that it mirrors the way in which a literal tree begins at a large trunk and splits into narrower and narrower branches as it’s adopted upward. In a lot the identical manner, a choice tree classifier makes use of a construction of branching choices that channel examples right into a last predicted class worth.
On this article, we display the implementation of resolution tree utilizing C5.0 algorithm in R.
This text is taken from the e book, Machine Studying with R, Fourth Version written by Brett Lantz.
There are quite a few implementations of resolution timber, however probably the most well-known is the C5.0 algorithm. This algorithm was developed by laptop scientist J. Ross Quinlan as an improved model of his prior algorithm, C4.5 (C4.5 itself is an enchancment over his Iterative Dichotomiser 3 (ID3) algorithm). Though Quinlan markets C5.0 to industrial purchasers, the supply code for a single-threaded model of the algorithm was made public, and has due to this fact been integrated into packages reminiscent of R.
The C5.0 resolution tree algorithm
The C5.0 algorithm has turn into the trade customary for producing resolution timber as a result of it does nicely for many forms of issues instantly out of the field. In comparison with different superior machine studying fashions, the choice timber constructed by C5.0 typically carry out practically as nicely however are a lot simpler to know and deploy. Moreover, as proven within the following desk, the algorithm’s weaknesses are comparatively minor and may be largely averted.
Strengths
- An all-purpose classifier that does nicely on many forms of issues.
- Extremely computerized studying course of, which may deal with numeric or nominal options, in addition to lacking knowledge.
- Excludes unimportant options.
- Can be utilized on each small and enormous datasets.
- Ends in a mannequin that may be interpreted with out a mathematical background (for comparatively small timber).
- Extra environment friendly than different complicated fashions.
Weaknesses
- Choice tree fashions are sometimes biased towards splits on options having numerous ranges.
- It’s straightforward to overfit or underfit the mannequin.
- Can have hassle modeling some relationships as a result of reliance on axis-parallel splits.
- Small adjustments in coaching knowledge can lead to massive adjustments to resolution logic.
- Giant timber may be troublesome to interpret and the choices they make could appear counterintuitive.
To maintain issues easy, our earlier resolution tree instance ignored the arithmetic concerned with how a machine would make use of a divide and conquer technique. Let’s discover this in additional element to look at how this heuristic works in follow.
Selecting the perfect cut up
The primary problem {that a} resolution tree will face is to establish which function to separate upon. Within the earlier instance, we appeared for a option to cut up the information such that the ensuing partitions contained examples primarily of a single class. The diploma to which a subset of examples accommodates solely a single class is named purity, and any subset composed of solely a single class known as pure.
There are numerous measurements of purity that can be utilized to establish the perfect resolution tree splitting candidate. C5.0 makes use of entropy, an idea borrowed from data idea that quantifies the randomness, or dysfunction, inside a set of sophistication values. Units with excessive entropy are very numerous and supply little details about different objects that will additionally belong within the set, as there is no such thing as a obvious commonality. The choice tree hopes to seek out splits that cut back entropy, in the end growing homogeneity throughout the teams.
Usually, entropy is measured in bits. If there are solely two doable courses, entropy values can vary from 0 to 1. For n courses, entropy ranges from 0 to log2(n). In every case, the minimal worth signifies that the pattern is totally homogenous, whereas the utmost worth signifies that the information are as numerous as doable, and no group has even a small plurality.
In mathematical notion, entropy is specified as:
On this components, for a given section of knowledge (S), the time period c refers back to the variety of class ranges, and pi refers back to the proportion of values falling into class degree i. For instance, suppose now we have a partition of knowledge with two courses: crimson (60 %) and white (40 %). We will calculate the entropy as:
> -0.60 * log2(0.60) - 0.40 * log2(0.40)[1] 0.9709506
We will visualize the entropy for all doable two-class preparations. If we all know the proportion of examples in a single class is x, then the proportion within the different class is (1 – x). Utilizing the curve() perform, we will then plot the entropy for all doable values of x:
> curve(-x * log2(x) - (1 - x) * log2(1 - x), col = "crimson", xlab = "x", ylab = "Entropy", lwd = 4)
This leads to the next determine:

The whole entropy because the proportion of 1 class varies in a two-class final result
As illustrated by the height in entropy at x = 0.50, a 50-50 cut up leads to the utmost entropy. As one class more and more dominates the opposite, the entropy reduces to zero.
To make use of entropy to find out the optimum function to separate upon, the algorithm calculates the change in homogeneity that will outcome from a cut up on every doable function, a measure often known as data acquire. The knowledge acquire for a function F is calculated because the distinction between the entropy within the section earlier than the cut up (S1) and the partitions ensuing from the cut up (S2):
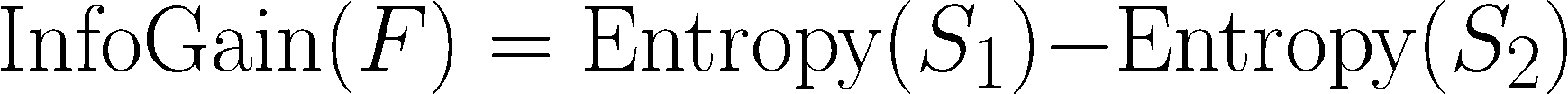
One complication is that after a cut up, the information is split into a couple of partition. Due to this fact, the perform to calculate Entropy(S2) wants to think about the whole entropy throughout all the partitions. It does this by weighting every partition’s entropy in line with the proportion of all information falling into that partition. This may be acknowledged in a components as:
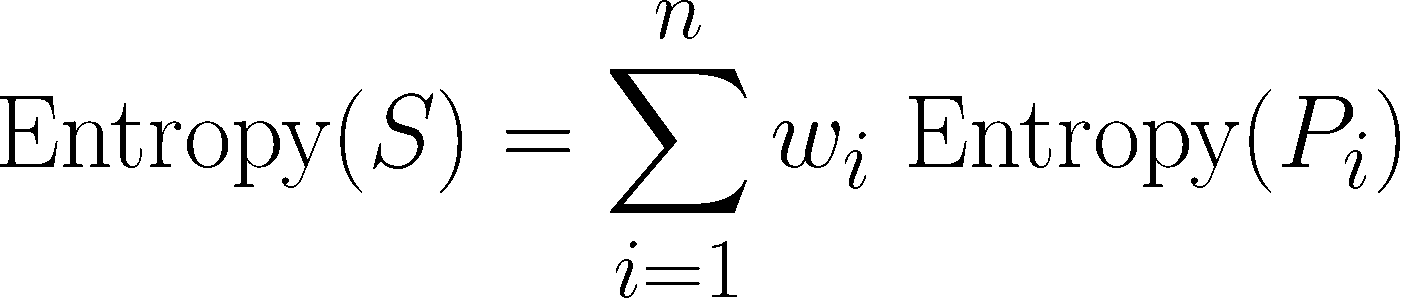
In easy phrases, the whole entropy ensuing from a cut up is the sum of entropy of every of the n partitions weighted by the proportion of examples falling within the partition (wi).
The upper the data acquire, the higher a function is at creating homogeneous teams after a cut up on that function. If the data acquire is zero, there is no such thing as a discount in entropy for splitting on this function. However, the utmost data acquire is the same as the entropy previous to the cut up. This might suggest the entropy after the cut up is zero, which signifies that the cut up leads to fully homogeneous teams.
The earlier formulation assume nominal options, however resolution timber use data acquire for splitting on numeric options as nicely. To take action, a typical follow is to check varied splits that divide the values into teams larger than or lower than a threshold. This reduces the numeric function right into a two-level categorical function that permits data acquire to be calculated as traditional. The numeric lower level yielding the biggest data acquire is chosen for the cut up.
Notice: Although it’s utilized by C5.0, data acquire is just not the one splitting criterion that can be utilized to construct resolution timber. Different generally used standards are Gini index, chi-squared statistic, and acquire ratio. For a evaluation of those (and lots of extra) standards, seek advice from An Empirical Comparability of Choice Measures for Choice-Tree Induction, Mingers, J, Machine Studying, 1989, Vol. 3, pp. 319-342.
Pruning the choice tree
As talked about earlier, a choice tree can proceed to develop indefinitely, selecting splitting options and dividing into smaller and smaller partitions till every instance is completely labeled or the algorithm runs out of options to separate on. Nonetheless, if the tree grows overly massive, most of the choices it makes will likely be overly particular and the mannequin will likely be overfitted to the coaching knowledge. The method of pruning a choice tree includes lowering its dimension such that it generalizes higher to unseen knowledge.
One resolution to this drawback is to cease the tree from rising as soon as it reaches a sure variety of choices or when the choice nodes comprise solely a small variety of examples. That is known as early stopping or prepruning the choice tree. Because the tree avoids doing unnecessary work, that is an interesting technique. Nonetheless, one draw back to this strategy is that there is no such thing as a option to know whether or not the tree will miss delicate however essential patterns that it might have realized had it grown to a bigger dimension.
An alternate, known as post-pruning, includes rising a tree that’s deliberately too massive and pruning leaf nodes to scale back the dimensions of the tree to a extra applicable degree. That is typically a more practical strategy than prepruning as a result of it’s fairly troublesome to find out the optimum depth of a choice tree with out rising it first. Pruning the tree in a while permits the algorithm to make sure that all the essential knowledge constructions had been found.
Notice: The implementation particulars of pruning operations are very technical and past the scope of this e book. For a comparability of a few of the obtainable strategies, see A Comparative Evaluation of Strategies for Pruning Choice Timber, Esposito, F, Malerba, D, Semeraro, G, IEEE Transactions on Sample Evaluation and Machine Intelligence, 1997, Vol. 19, pp. 476-491.
One of many advantages of the C5.0 algorithm is that it’s opinionated about pruning-it takes care of most of the choices routinely utilizing pretty affordable defaults. Its general technique is to post-prune the tree. It first grows a big tree that overfits the coaching knowledge. Later, the nodes and branches which have little impact on the classification errors are eliminated. In some circumstances, complete branches are moved additional up the tree or changed by less complicated choices. These processes of grafting branches are often known as subtree elevating and subtree alternative, respectively.
Getting the appropriate steadiness of overfitting and underfitting is a little bit of an artwork, but when mannequin accuracy is significant, it could be price investing a while with varied pruning choices to see if it improves the take a look at dataset efficiency.
To summarize , resolution timber are broadly used as a result of their excessive accuracy and talent to formulate a statistical mannequin in plain language. Right here, we checked out a extremely standard and simply configurable resolution tree algorithm C5.0. The foremost power of the C5.0 algorithm over different resolution tree implementations is that it is vitally straightforward to regulate the coaching choices.
The submit Implementing a choice tree utilizing C5.0 algorithm in R appeared first on Datafloq.





/cdn.vox-cdn.com/uploads/chorus_asset/file/23932925/acastro_STK108__03.jpg)
