


It is a visitor publish by Jose Benitez, Founder and Director of AI and Mattias Ponchon, Head of Infrastructure at Intuitivo.
Intuitivo, a pioneer in retail innovation, is revolutionizing procuring with its cloud-based AI and machine studying (AI/ML) transactional processing system. This groundbreaking expertise permits us to function thousands and thousands of autonomous factors of buy (A-POPs) concurrently, reworking the best way clients store. Our resolution outpaces conventional merchandising machines and alternate options, providing a cost-effective edge with its ten instances cheaper price, simple setup, and maintenance-free operation. Our revolutionary new A-POPs (or merchandising machines) ship enhanced buyer experiences at ten instances decrease price due to the efficiency and value benefits AWS Inferentia delivers. Inferentia has enabled us to run our You Solely Look As soon as (YOLO) laptop imaginative and prescient fashions 5 instances sooner than our earlier resolution and helps seamless, real-time procuring experiences for our clients. Moreover, Inferentia has additionally helped us scale back prices by 95 % in comparison with our earlier resolution. On this publish, we cowl our use case, challenges, and a short overview of our resolution utilizing Inferentia.
The altering retail panorama and wish for A-POP
The retail panorama is evolving quickly, and customers count on the identical easy-to-use and frictionless experiences they’re used to when procuring digitally. To successfully bridge the hole between the digital and bodily world, and to fulfill the altering wants and expectations of consumers, a transformative method is required. At Intuitivo, we imagine that the way forward for retail lies in creating extremely personalised, AI-powered, and laptop vision-driven autonomous factors of buy (A-POP). This technological innovation brings merchandise inside arm’s attain of consumers. Not solely does it put clients’ favourite gadgets at their fingertips, nevertheless it additionally gives them a seamless procuring expertise, devoid of lengthy traces or complicated transaction processing methods. We’re excited to guide this thrilling new period in retail.
With our cutting-edge expertise, retailers can rapidly and effectively deploy hundreds of A-POPs. Scaling has all the time been a frightening problem for retailers, primarily as a result of logistic and upkeep complexities related to increasing conventional merchandising machines or different options. Nonetheless, our camera-based resolution, which eliminates the necessity for weight sensors, RFID, or different high-cost sensors, requires no upkeep and is considerably cheaper. This permits retailers to effectively set up hundreds of A-POPs, offering clients with an unmatched procuring expertise whereas providing retailers an economical and scalable resolution.
Utilizing cloud inference for real-time product identification
Whereas designing a camera-based product recognition and fee system, we bumped into a call of whether or not this must be carried out on the sting or the cloud. After contemplating a number of architectures, we designed a system that uploads movies of the transactions to the cloud for processing.
Our finish customers begin a transaction by scanning the A-POP’s QR code, which triggers the A-POP to unlock after which clients seize what they need and go. Preprocessed movies of those transactions are uploaded to the cloud. Our AI-powered transaction pipeline robotically processes these movies and prices the shopper’s account accordingly.
The next diagram exhibits the structure of our resolution.
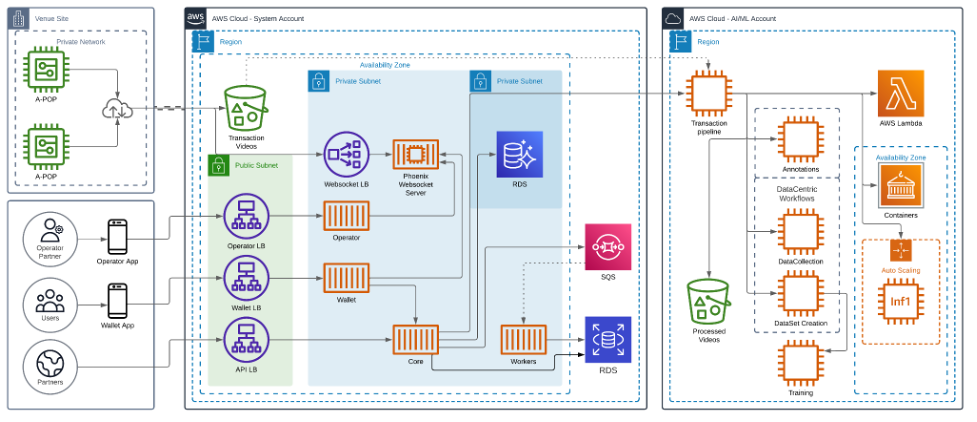
Unlocking high-performance and cost-effective inference utilizing AWS Inferentia
As retailers look to scale operations, price of A-POPs turns into a consideration. On the identical time, offering a seamless real-time procuring expertise for end-users is paramount. Our AI/ML analysis crew focuses on figuring out the most effective laptop imaginative and prescient (CV) fashions for our system. We have been now offered with the problem of the way to concurrently optimize the AI/ML operations for efficiency and value.
We deploy our fashions on Amazon EC2 Inf1 situations powered by Inferentia, Amazon’s first ML silicon designed to speed up deep studying inference workloads. Inferentia has been proven to cut back inference prices considerably. We used the AWS Neuron SDK—a set of software program instruments used with Inferentia—to compile and optimize our fashions for deployment on EC2 Inf1 situations.
The code snippet that follows exhibits the way to compile a YOLO mannequin with Neuron. The code works seamlessly with PyTorch and capabilities comparable to torch.jit.hint()and neuron.hint()report the mannequin’s operations on an instance enter in the course of the ahead move to construct a static IR graph.
We migrated our compute-heavy fashions to Inf1. Through the use of AWS Inferentia, we achieved the throughput and efficiency to match our enterprise wants. Adopting Inferentia-based Inf1 situations within the MLOps lifecycle was a key to reaching exceptional outcomes:
- Efficiency enchancment: Our giant laptop imaginative and prescient fashions now run 5 instances sooner, reaching over 120 frames per second (FPS), permitting for seamless, real-time procuring experiences for our clients. Moreover, the power to course of at this body charge not solely enhances transaction velocity, but additionally permits us to feed extra data into our fashions. This enhance in information enter considerably improves the accuracy of product detection inside our fashions, additional boosting the general efficacy of our procuring methods.
- Value financial savings: We slashed inference prices. This considerably enhanced the structure design supporting our A-POPs.
Knowledge parallel inference was simple with AWS Neuron SDK
To enhance efficiency of our inference workloads and extract most efficiency from Inferentia, we wished to make use of all out there NeuronCores within the Inferentia accelerator. Attaining this efficiency was simple with the built-in instruments and APIs from the Neuron SDK. We used the torch.neuron.DataParallel() API. We’re at the moment utilizing inf1.2xlarge which has one Inferentia accelerator with 4 Neuron accelerators. So we’re utilizing torch.neuron.DataParallel() to totally use the Inferentia {hardware} and use all out there NeuronCores. This Python perform implements information parallelism on the module degree on fashions created by the PyTorch Neuron API. Knowledge parallelism is a type of parallelization throughout a number of gadgets or cores (NeuronCores for Inferentia), known as nodes. Every node accommodates the identical mannequin and parameters, however information is distributed throughout the totally different nodes. By distributing the information throughout a number of nodes, information parallelism reduces the entire processing time of enormous batch dimension inputs in comparison with sequential processing. Knowledge parallelism works greatest for fashions in latency-sensitive functions which have giant batch dimension necessities.
Wanting forward: Accelerating retail transformation with basis fashions and scalable deployment
As we enterprise into the long run, the impression of basis fashions on the retail trade can’t be overstated. Basis fashions could make a big distinction in product labeling. The power to rapidly and precisely determine and categorize totally different merchandise is essential in a fast-paced retail setting. With fashionable transformer-based fashions, we will deploy a higher variety of fashions to serve extra of our AI/ML wants with increased accuracy, bettering the expertise for customers and with out having to waste money and time coaching fashions from scratch. By harnessing the ability of basis fashions, we will speed up the method of labeling, enabling retailers to scale their A-POP options extra quickly and effectively.
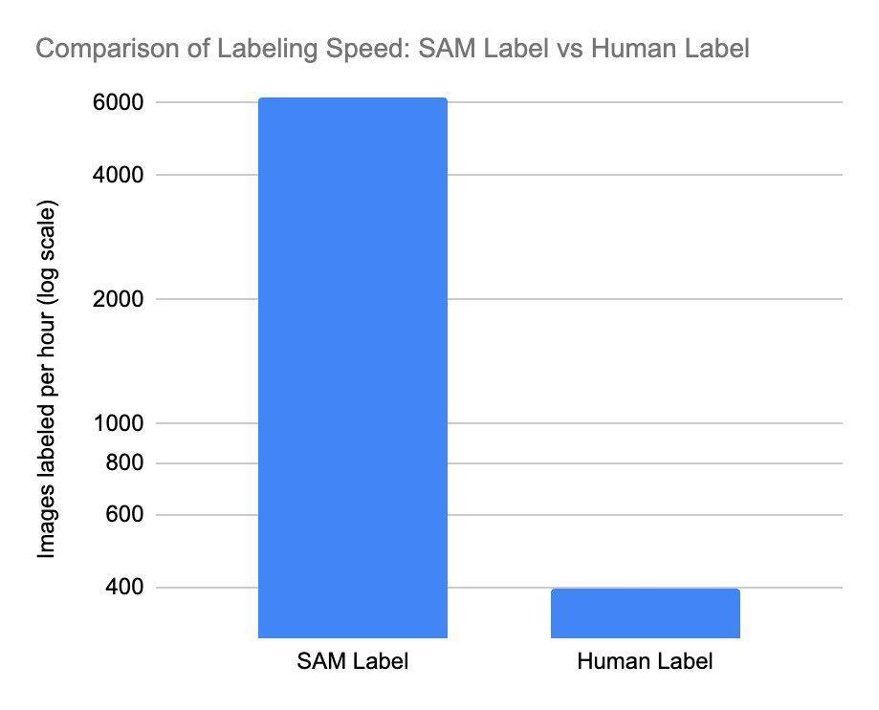
We have now begun implementing Phase Something Mannequin (SAM), a imaginative and prescient transformer basis mannequin that may phase any object in any picture (we are going to talk about this additional in one other weblog publish). SAM permits us to speed up our labeling course of with unparalleled velocity. SAM may be very environment friendly, capable of course of roughly 62 instances extra photos than a human can manually create bounding packing containers for in the identical timeframe. SAM’s output is used to coach a mannequin that detects segmentation masks in transactions, opening up a window of alternative for processing thousands and thousands of photos exponentially sooner. This considerably reduces coaching time and value for product planogram fashions.
Our product and AI/ML analysis groups are excited to be on the forefront of this transformation. The continuing partnership with AWS and our use of Inferentia in our infrastructure will be certain that we will deploy these basis fashions affordably. As early adopters, we’re working with the brand new AWS Inferentia 2-based situations. Inf2 situations are constructed for in the present day’s generative AI and enormous language mannequin (LLM) inference acceleration, delivering increased efficiency and decrease prices. Inf2 will allow us to empower retailers to harness the advantages of AI-driven applied sciences with out breaking the financial institution, finally making the retail panorama extra revolutionary, environment friendly, and customer-centric.
As we proceed to migrate extra fashions to Inferentia and Inferentia2, together with transformers-based foundational fashions, we’re assured that our alliance with AWS will allow us to develop and innovate alongside our trusted cloud supplier. Collectively, we are going to reshape the way forward for retail, making it smarter, sooner, and extra attuned to the ever-evolving wants of customers.
Conclusion
On this technical traverse, we’ve highlighted our transformational journey utilizing AWS Inferentia for its revolutionary AI/ML transactional processing system. This partnership has led to a 5 instances enhance in processing velocity and a surprising 95 % discount in inference prices in comparison with our earlier resolution. It has modified the present method of the retail trade by facilitating a real-time and seamless procuring expertise.
When you’re all for studying extra about how Inferentia might help you save prices whereas optimizing efficiency in your inference functions, go to the Amazon EC2 Inf1 situations and Amazon EC2 Inf2 situations product pages. AWS gives numerous pattern codes and getting began assets for Neuron SDK that you’ll find on the Neuron samples repository.
Concerning the Authors
Matias Ponchon is the Head of Infrastructure at Intuitivo. He focuses on architecting safe and sturdy functions. With in depth expertise in FinTech and Blockchain firms, coupled together with his strategic mindset, helps him to design revolutionary options. He has a deep dedication to excellence, that’s why he persistently delivers resilient options that push the boundaries of what’s potential.
Jose Benitez is the Founder and Director of AI at Intuitivo, specializing within the growth and implementation of laptop imaginative and prescient functions. He leads a proficient Machine Studying crew, nurturing an setting of innovation, creativity, and cutting-edge expertise. In 2022, Jose was acknowledged as an ‘Innovator Below 35’ by MIT Know-how Assessment, a testomony to his groundbreaking contributions to the sphere. This dedication extends past accolades and into each challenge he undertakes, showcasing a relentless dedication to excellence and innovation.
Diwakar Bansal is an AWS Senior Specialist targeted on enterprise growth and go-to-market for Gen AI and Machine Studying accelerated computing companies. Beforehand, Diwakar has led product definition, international enterprise growth, and advertising and marketing of expertise merchandise for IoT, Edge Computing, and Autonomous Driving specializing in bringing AI and Machine Studying to those domains.


/cdn.vox-cdn.com/uploads/chorus_asset/file/23932925/acastro_STK108__03.jpg)


