


The combination of language fashions into organic analysis represents a big problem because of the inherent variations between pure language and organic sequences. Organic knowledge, resembling DNA, RNA, and protein sequences, are essentially totally different from pure language textual content, but they share sequential traits that make them amenable to comparable processing methods. The first problem lies in successfully adapting language fashions, initially developed for pure language processing (NLP), to deal with the complexities of organic sequences. Addressing this problem is essential for enabling extra correct predictions in fields resembling protein construction prediction, gene expression evaluation, and the identification of molecular interactions. Efficiently overcoming these hurdles has the potential to revolutionize varied domains inside biology, significantly in areas requiring the evaluation of enormous and sophisticated datasets.
Present strategies for analyzing organic sequences rely closely on conventional sequence alignment methods and machine studying approaches. Sequence alignment instruments like BLAST and Clustal are generally used however usually wrestle with the computational complexity and scalability required for giant datasets. These strategies are additional restricted by their incapacity to seize the deeper structural and useful relationships inside sequences. Machine studying methods, together with random forests and assist vector machines, supply some enhancements however are constrained by the necessity for manually engineered options and their lack of generalizability throughout numerous organic contexts. These limitations considerably cut back the effectiveness and applicability of those strategies, significantly in real-time organic analysis the place effectivity and accuracy are paramount.
To handle these limitations, Stanford researchers suggest utilizing language fashions, significantly these based mostly on the transformer structure, in organic analysis. This revolutionary strategy leverages the power of language fashions to course of large-scale, heterogeneous datasets and to uncover complicated patterns inside sequential knowledge. Pre-trained language fashions, resembling ESM-2 for protein sequences and Geneformer for single-cell knowledge, might be fine-tuned for particular organic duties, providing a versatile and scalable resolution that addresses the shortcomings of conventional strategies. By harnessing the ability of those fashions, the strategy gives a big development within the evaluation of organic sequences, enabling extra correct and environment friendly predictions in essential areas of analysis.
The proposed methodology depends on the transformer structure, which is especially efficient for processing sequential knowledge. The researchers have utilized varied pre-trained fashions, together with ESM-2, a protein language mannequin skilled on over 250 million protein sequences, and Geneformer, a single-cell language mannequin skilled on 30 million single-cell transcriptomes. These fashions make use of masked language modeling, the place components of the sequence are hidden, and the mannequin is skilled to foretell the lacking components. This coaching allows the mannequin to be taught the underlying patterns and relationships inside the sequences, making it attainable to foretell outcomes resembling protein stability, gene expression ranges, and variant results. The fashions might be additional fine-tuned for particular duties, resembling integrating multi-modal knowledge that features gene expression, chromatin accessibility, and protein abundance.
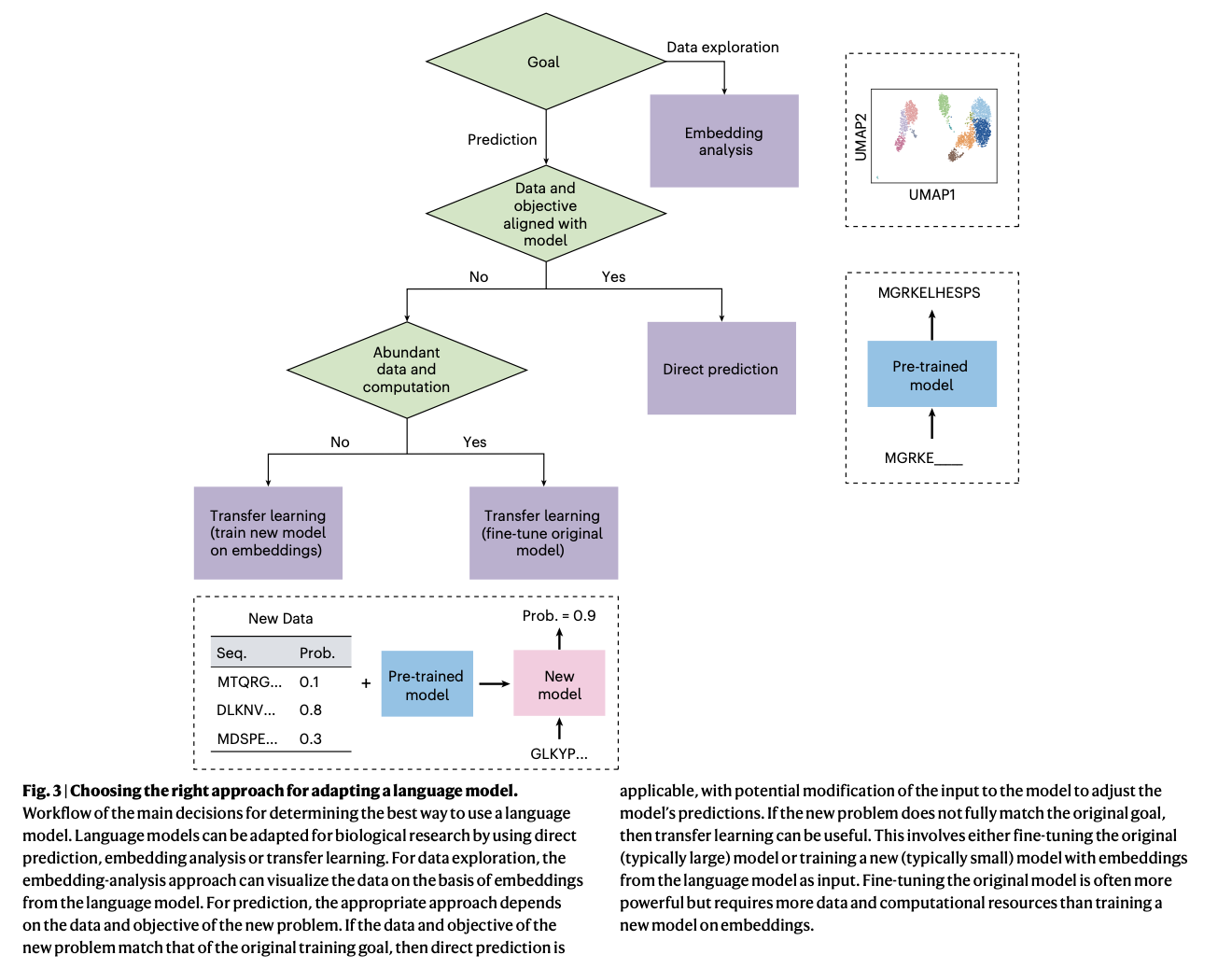
The proposed language fashions demonstrated substantial enhancements throughout varied organic duties. For protein sequence evaluation, the mannequin achieved larger accuracy in predicting protein stability and evolutionary constraints, considerably outperforming current strategies. In single-cell knowledge evaluation, the mannequin successfully predicted cell sorts and gene expression patterns with enhanced precision, providing superior efficiency in figuring out refined organic variations. These outcomes underscore the fashions’ potential to rework organic analysis by offering correct, scalable, and environment friendly instruments for analyzing complicated organic knowledge, thereby advancing the capabilities of computational biology.
In conclusion, this proposed methodology presents a big contribution to AI-driven organic analysis by successfully adapting language fashions for the evaluation of organic sequences. The strategy addresses a essential problem within the subject by leveraging the strengths of transformer-based fashions to beat the constraints of conventional strategies. The usage of fashions like ESM-2 and Geneformer gives a scalable and correct resolution for a variety of organic duties, with the potential to revolutionize fields resembling genomics, proteomics, and customized medication by enhancing the effectivity and accuracy of organic knowledge evaluation.
Take a look at the Paper and Colab Tutorial. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Overlook to hitch our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.


/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



