


Introduction
A game-changing innovation has arrived in AI’s fast-evolving panorama, reshaping how machines have interaction with human language. Enter Retrieval Augmented Era (RAG), a fusion of retrieval and technology fashions in NLP. RAG isn’t only a tech buzzword; it’s revolutionizing human-machine communication. Be a part of us as we uncover the secrets and techniques of RAG, discover its functions, and its profound AI impression. RAG is on the forefront of NLP, seamlessly merging retrieval and technology for a transformative AI method, enhancing how machines grasp and work together with human language.
Studying Targets
- Grasp the foundational ideas of retrieval-based and generation-based fashions in Pure Language Processing (NLP), together with their functions, variations, and similarities.
- Analyze the restrictions of pure retrieval or technology fashions in NLP, exploring real-world examples.
- Acknowledge the significance of bridging retrieval and technology fashions in NLP, understanding the situations the place this integration is important.
- Dive into the Retrieval Augmented Era (RAG) structure and perceive its parts.
- Develop sensible expertise in implementing RAG, together with producing embeddings and understanding the transparency and accuracy points.
This text was printed as part of the Information Science Blogathon.
Understanding Retrieval and Era
Let’s delve into the understanding of retrieval-based and generation-based fashions and the important thing variations and similarities between these approaches in pure language processing.

Retrieval-Based mostly Fashions in NLP
Retrieval-based fashions in NLP are designed to pick out an acceptable response from a predefined set of responses based mostly on the enter question. These fashions examine the enter textual content (a query or question) with a database of predefined responses. The system identifies probably the most appropriate response by measuring the similarity between the enter and saved responses utilizing methods like cosine similarity or different semantic matching strategies. Retrieval-based fashions are environment friendly for duties like question-answering, the place the responses are sometimes fact-based and available in a structured kind.
Era-Based mostly Fashions in NLP
Era-based fashions, then again, create responses from scratch. These fashions use complicated algorithms, typically based mostly on neural networks, to generate human-like textual content. In contrast to retrieval-based fashions, generation-based fashions don’t depend on predefined responses. As an alternative, they be taught to generate responses by predicting the subsequent phrase or sequence of phrases based mostly on the context supplied by the enter. This capacity to generate novel, contextually acceptable responses makes generation-based fashions extremely versatile and appropriate for artistic writing, machine translation, and dialogue methods the place responses have to be numerous and contextually wealthy.
Key Variations and Similarities
| Retrieval-Based mostly Fashions | Era-Based mostly Fashions | |
| Information Dependence | Rely closely on the provision of predefined responses within the dataset. | Don’t require predefined responses; they generate responses based mostly on discovered patterns. |
| Response Selection | Restricted to the set of responses accessible within the database, which can lead to repetitive or generic solutions. | Can produce numerous and contextually wealthy responses, resulting in extra participating and inventive interactions. |
| Contextual Understanding | Give attention to matching the enter question with present responses, missing a deep understanding of the context. | Seize nuanced context and might generate responses tailor-made to the precise enter, enhancing the standard of interactions. |
| Coaching Complexity | Typically extra easy to coach, as they contain matching enter patterns with predefined responses. | A extra complicated coaching course of typically requires massive datasets and complicated neural community architectures. |
In abstract, retrieval-based fashions excel in duties the place predefined responses can be found, and pace is essential, whereas generation-based fashions shine in duties requiring creativity, context consciousness, and the technology of numerous and authentic content material. Combining these approaches in fashions like RAG offers a balanced resolution, leveraging the strengths of each strategies to boost the general efficiency of NLP methods.
Limitations of Purely Retrieval or Era Fashions
Within the dynamic world of synthetic intelligence, the place conversations between people and machines have gotten more and more subtle, two predominant fashions have taken the stage: retrieval-based and generation-based fashions. Whereas these fashions have their very own deserves, they don’t seem to be with out their limitations.
Restricted Context Understanding
The Retrieval Fashions depend on pre-existing responses, typically missing the power to grasp the context of the dialog deeply. The Era Fashions, although able to producing contextually related responses, may lack entry to particular, factual info that retrieval fashions can present.
Repetitive and Generic Responses
As a consequence of a hard and fast set of responses, the Retrieval Mannequin can develop into repetitive, providing related solutions to totally different queries. With no well-defined dataset, technology fashions may generate generic or nonsensical responses, particularly if the coaching knowledge doesn’t cowl a variety of situations.
Dealing with Ambiguity
Ambiguous queries typically end in suboptimal or incorrect responses since Retrieval Fashions lack the power to disambiguate the context successfully. Coping with ambiguous queries requires a nuanced understanding of the context for Era Fashions, which could be difficult for technology fashions to realize with out intensive coaching knowledge.
Actual-World Examples Showcasing the Limitations of Conventional NLP Strategies
As know-how advances and our expectations develop, these strategies are beginning to present their limitations in dealing with the complexities of real-world conversations. Let’s delve into some real-world examples illuminating the challenges conventional NLP strategies face.
| Buyer Assist Chatbots | Language Translation | Medical Prognosis Methods | Academic Chatbots |
| Retrieval-based chatbots can provide predefined responses for frequent queries however wrestle when confronted with distinctive or complicated points, resulting in annoyed prospects. | Era-based translation fashions may translate phrases individually, ignoring the context of your entire sentence. This may result in inaccurate translations, particularly for idiomatic expressions. | Retrieval fashions may lack the power to include the most recent medical analysis and developments, resulting in outdated or inaccurate info. | Era fashions may wrestle with producing step-by-step explanations for complicated ideas, hindering the training expertise for college students. |
| A buyer asks a particular technical query outdoors the chatbot’s predefined responses, leading to a generic and unhelpful reply. | Translating the phrase “kick the bucket” into one other language word-for-word won’t convey its idiomatic that means, leading to confusion for the reader. | A affected person’s signs may match an outdated database entry, inflicting the system to recommend incorrect diagnoses or therapies. | When a pupil asks a chatbot to clarify a posh mathematical theorem, the generated response may lack readability or fail to cowl all mandatory steps, inflicting confusion. |
Understanding these limitations is essential for creating superior NLP fashions like RAG, which intention to beat these challenges by integrating the strengths of each retrieval and technology approaches. RAG’s capacity to retrieve particular info whereas producing contextually acceptable responses addresses most of the shortcomings of conventional NLP strategies, paving the way in which for more practical and fascinating human-computer interactions.
What’s the Want for Bridging Retrieval and Era?
Think about a world the place conversations with chatbots usually are not solely contextually wealthy but in addition personalised to particular person wants. RAG makes this imaginative and prescient a actuality by combining retrieval and technology methodologies. In interactive dialogues, context is vital.
RAG ensures that responses are related but in addition numerous and fascinating, enhancing the consumer expertise in situations like customer support interactions or digital assistant functions. It facilitates personalised responses, tailoring info to particular person customers’ wants, and permits dynamic info retrieval, making certain the most recent knowledge is comprehensively offered.
Purposes that Profit from Bridging Retrieval and Era
- Take into account academic platforms seamlessly mixing factual info from a information base with custom-tailored explanations generated in real-time.
- Visualize content material creation instruments crafting numerous narratives by retrieving related knowledge and producing artistic content material.
- Envision medical analysis methods offering exact recommendation by integrating affected person historical past (retrieval) with contextually correct diagnostic reviews (technology).
- Authorized session chatbots translate complicated authorized jargon into comprehensible language, combining retrieval of authorized knowledge with clear, understandable explanations.
- Interactive storytelling platforms and video video games come alive with predefined story components and dynamically generated narratives based mostly on consumer interactions, enhancing immersion and engagement.
Bridging the Hole with RAG
RAG’s capacity to stability correct info retrieval with artistic, contextually acceptable technology transforms varied fields. On the planet of RAG, chatbots present not simply solutions however significant, tailor-made interactions. Academic experiences develop into dynamic and personalised. Content material creation turns into an artwork, mixing info with creativity. Medical consultations flip exact and empathetic. Authorized recommendation turns into accessible and comprehensible. Interactive tales and video games evolve into immersive adventures.
Structure of RAG
Within the intricate design of Retrieval-Augmented Era (RAG) methods, a rigorously choreographed two-step course of unfolds to generate responses that aren’t simply informative but in addition deeply participating. Let’s unravel this course of, the place retrieval and technology seamlessly collaborate to craft significant interactions.

Retrieval Section
On the coronary heart of RAG’s performance lies the retrieval section. On this stage, the system delves into huge databases or collections of paperwork, meticulously trying to find probably the most pertinent info and passages associated to the consumer’s question. Whether or not it’s scouring listed webpages for normal inquiries or consulting managed manuals and articles for particular domains like buyer assist, RAG expertly extracts related snippets of exterior information. These morsels of data are then seamlessly built-in with the consumer’s authentic enter, enriching the context of the dialog.
Era Section
With the augmented context, the system gracefully transitions to the technology section. The language mannequin springs into motion, meticulously analyzing the expanded immediate. It ingeniously references each the retrieved exterior info and its internally skilled patterns. This dual-reference system permits the mannequin to craft responses which can be correct and stream naturally, mimicking human dialog. The result’s an insightful and contextually related reply that seamlessly integrates the retrieved knowledge with the system’s inherent linguistic finesse.
The ultimate response, born from this collaborative dance of retrieval and technology, can optionally function hyperlinks to the sources from which the knowledge was retrieved. This enhances the response’s credibility and permits customers to discover the origin of the supplied info, fostering belief and understanding.
In essence, RAG methods mix the facility of trying to find info and the artwork of artistic language use to provide you correct and fascinating responses, making your interactions with know-how really feel extra like conversations with educated mates.
How does RAG Work?
RAG enriches consumer enter with context from exterior knowledge sources like paperwork or databases.
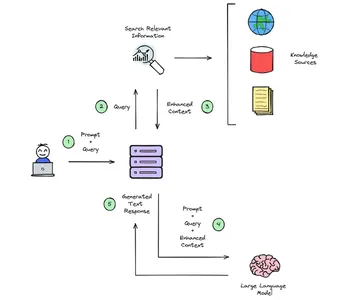
Initially, consumer queries and data are known as Vector Embeddings, translated into numerical worth embedding language fashions. These embeddings are organized in a vector retailer, the place a seek for relevance is carried out by evaluating consumer question embeddings. The pertinent context discovered is added to the unique consumer immediate, enhancing the general context. The foundational language mannequin then makes use of this enriched context to craft a textual content response. Moreover, a definite course of could be established to replace the knowledge within the vector retailer individually, making certain fixed updates.
Retrieval Element
Step one in RAG is retrieval. Utilizing specialised algorithms or APIs, RAG fetches related info from a dataset or information base. Right here’s a fundamental instance of how retrieval could be executed utilizing an API.
import requests
def retrieve_information(question):
api_endpoint = "https://instance.com/api"
response = requests.get(api_endpoint, params={"question": question})
knowledge = response.json()
return knowledge
Augmentation Element
As soon as the knowledge is retrieved, Rag augments it to boost context. Augmentation can contain methods reminiscent of entity recognition, sentiment evaluation, and even easy textual content manipulations. Right here’s a vital textual content augmentation instance utilizing the NLTK library:
import nltk
def augment_text(textual content):
tokens = nltk.word_tokenize(textual content)
augmented_tokens = [token.upper() for token in tokens]
augmented_text = " ".be part of(augmented_tokens)
return augmented_text
Era Element
The ultimate step entails producing pure language responses based mostly on the retrieved and augmented info. That is usually executed utilizing pre-trained language fashions. Right here’s an instance utilizing the Transformers library from Hugging Face:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
def generate_text(immediate):
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
mannequin = GPT2LMHeadModel.from_pretrained("gpt2")
inputs = tokenizer.encode(immediate, return_tensors="pt")
outputs = mannequin.generate(inputs, max_length=100, num_return_sequences=1)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return generated_text
What are the Parts of RAG?
Within the intricate realm of Retrieval-Augmented Era (RAG) methods, a rigorously orchestrated symphony of parts is important for his or her efficient implementation. Let’s break down these core components that kind the spine of a strong RAG structure, seamlessly integrating retrieval and technology for a transformative conversational expertise.

Language Mannequin
A pre-trained language mannequin, such because the famend GPT-3, is central to any RAG setup. These fashions are the cornerstone, possessing unparalleled language comprehension and synthesis skills. They’re the engines that energy participating and coherent conversational dialogues.
Vector Retailer
The vector retailer is on the coronary heart of the retrieval course of, a database preserving doc embeddings. These embeddings function distinctive signatures, quickly figuring out pertinent contextual info. Consider it as an unlimited repository permitting fast and environment friendly searches for related knowledge.
Retriever Module
The retriever module acts because the gatekeeper, leveraging the vector retailer for semantic matching. Utilizing superior neural retrieval methods, this part effectively sifts by way of paperwork and passages to reinforce prompts. Its prowess lies in its capacity to establish probably the most related info swiftly.
Embedder
To populate the vector retailer, an embedder performs a pivotal position. This part encodes supply paperwork into vector representations that the retriever comprehends. Fashions like BERT are tailored for this job, remodeling textual info into summary vector varieties for environment friendly processing.
Doc Ingestion
Behind the scenes, strong pipelines come into play. They ingest and preprocess supply paperwork, breaking them into manageable chunks or passages. These processed snippets are fed to the embedder, making certain the knowledge is structured and optimized for environment friendly lookup.
By harmonizing these core parts, RAG methods empower language fashions to delve into intensive information repositories. Via this intricate interaction, these methods rework mere interactions into profound exchanges of data and creativity, revolutionizing the panorama of human-computer communication.
RAG for Massive Language Fashions
Within the huge panorama of Synthetic Intelligence, a revolutionary method has emerged, remodeling how machines talk and perceive human language. Retrieval Augmented Era, or RAG, isn’t just one other acronym within the tech world; it’s a game-changing framework that marries the brilliance of huge language fashions (LLMs) with the wealth of real-world information, enhancing the accuracy and transparency of AI interactions.
Textual content is produced by pre-trained language fashions utilizing patterns discovered of their coaching knowledge. RAG enhances its capabilities by bynenting info incessantly and acquiring up to date information. As an alternative of relying solely on encoded patterns, this bases the language mannequin’s predictions on precise knowledge.
Implementing RAG: Code Demonstration
Within the earlier sections of our journey by way of RAG (Retrieval-Augmented Era) in NLP, we delved into the speculation behind this revolutionary method. Now, it’s time to roll up our sleeves and get our fingers soiled with some code.
Setting the Stage: Libraries and Instruments
We’ll use the Hugging Face Transformers library, a treasure trove of pre-trained fashions and NLP instruments. Should you haven’t put in it but, you are able to do so by way of pip:
pip set up transformers
pip set up torch
Step 1: Importing the Libraries
Let’s begin by importing the required libraries. We’ll import the pipeline module from transformers to simply entry pre-trained fashions and textual content technology.
from transformers import pipeline
Step 2: Setting Up the RAG Mannequin
Now, let’s arrange our RAG mannequin. We’ll use the pipeline perform with the text2text-generation job to provoke an RAG mannequin.
rag_pipeline = pipeline("text2text-generation", mannequin="fb/rag-token-base",
retriever="fb/rag-token-base")
This code makes use of the Fb RAG mannequin, which mixes a retriever and a generator in a single highly effective package deal.
Step 3: Integrating Retrieval Strategies
One of the crucial thrilling points of RAG is its capacity to carry out retrieval earlier than technology. To show this, let’s arrange a pattern context and question for our RAG mannequin to retrieve related info.
context = "Albert Einstein was a German-born theoretical physicist who
developed the speculation of relativity, one of many two pillars of contemporary physics."
question = "What's the idea of relativity?"Step 4: Producing Textual content with RAG
Let’s make the most of our RAG mannequin to generate textual content based mostly on the supplied context and question.
generated_text = rag_pipeline(question, context=context)[0]['generated_text']
print("Generated Textual content:")
print(generated_text)
Retrieval Augmented Era (RAG) acts like a fact-checker and a storyteller, making certain that when AI responds to your questions, it’s not simply making issues up. Right here’s the way it works:
Offering Actual-World Context
Think about you ask a query, and as a substitute of guessing a solution, RAG checks real-world sources for correct info. This ensures that what it tells you is predicated on precise information, making the responses reliable and dependable.
Citing Sources for Verification
RAG doesn’t simply provide you with a solution; it additionally tells you the place it discovered the knowledge. It’s like supplying you with a bibliography for an essay. This fashion, you’ll be able to double-check the info, making certain that the knowledge is correct and comes from credible sources.
Stopping False Info
RAG doesn’t make issues up. It avoids creating tales or offering false info by counting on verified info. This ensures that the responses are truthful and don’t result in misunderstandings.
Conserving Info Present
Consider RAG as gaining access to a continuously up to date library. It ensures its info is all the time up-to-date, avoiding outdated or irrelevant particulars. This fashion, you all the time get the most recent and most related solutions to your questions.
Producing Embeddings for RAGs
With regards to equipping RAG with the fitting information, producing embeddings is the important thing. These embeddings, or compact numerical representations of textual content, are important for RAG to grasp and reply precisely. Right here’s how this course of works:
Encoding Exterior Paperwork
Think about these exterior paperwork as books in an unlimited library. RAG interprets these paperwork into numerical vectors utilizing specialised fashions like BERT to make sense of them. These vectors seize the that means of the textual content in a means that the mannequin can perceive. It’s like translating total books right into a language the pc can comprehend.
Pretrained Language Fashions
RAG employs highly effective language fashions like BERT or RoBERTa. These fashions are pre-trained to grasp the nuances of human language. By inputting a doc into these fashions, RAG creates a singular numerical illustration for every doc. As an example, if the doc is about Paris, these fashions encode the essence of that info right into a vector.
Tailoring Embeddings for Particular Subjects
RAG fine-tunes these language fashions on particular subjects to make these embeddings much more exact. Think about tweaking a radio station to get a clearer reception. By coaching BERT on paperwork associated to particular topics, like journey guides, RAG ensures that the embeddings are tailor-made particularly for the subjects it can cope with, reminiscent of holidays or travel-related queries.
Customized Autoencoder Mannequin
RAG can even prepare a {custom} autoencoder mannequin, a specialised translator. This mannequin learns to translate total paperwork into numerical vectors by understanding the distinctive patterns inside the textual content. It’s like instructing a pc to learn and summarize the content material in its language, making the knowledge accessible for the AI to course of.
Easy Aggregation Capabilities
RAG can use methods like TF-IDF weighted averaging for a extra easy method. This technique calculates numerical values for every phrase in a doc, contemplating their significance, after which combines them to kind a vector. It’s akin to summarizing a ebook utilizing its most vital key phrases, making certain a fast and environment friendly approach to characterize the doc numerically.
Selecting the right embedding technique is dependent upon the kind of paperwork, the knowledge’s complexity, and the RAG system’s particular wants. Usually, language mannequin encoding and fine-tuning strategies are favored, making certain that RAG is provided with high-quality, contextually wealthy doc representations for efficient retrieval and technology.
Customizing Retrieval Strategies: Enhancing Precision
As seasoned adventurers, we all know that one measurement doesn’t match all in NLP. Customizing our retrieval strategies is akin to sharpening our swords for battle. With RAG, we will select particular retrievers tailor-made to our wants. As an example, integrating the BM25 retriever permits us to boost the precision and relevance of the retrieved paperwork. Right here’s a glimpse of the way it’s executed:
from transformers import RagRetriever, RagTokenizer, pipeline
retriever = RagRetriever.from_pretrained("fb/rag-token-base", retriever="bm25")
tokenizer = RagTokenizer.from_pretrained("fb/rag-token-base")
generator = pipeline('text-generation', mannequin="fb/rag-token-base")
# Put together your context and question
context = "Albert Einstein was a German-born theoretical physicist who
developed the speculation of relativity, one of many two pillars of contemporary physics."
question = "What's the idea of relativity?"
input_dict = tokenizer(context, question, return_tensors="pt")
retrieved_docs = retriever(input_dict["input_ids"])
generated_text = generator(retrieved_docs["context_input_ids"])[0]["generated_text"]
print("Generated Textual content:")
print(generated_text)
High quality-Tuning for Mastery: Elevating RAG with Your Information
In our quest for NLP supremacy, we might have a specialised contact. High quality-tuning a pre-trained RAG mannequin with our dataset can yield distinctive outcomes. Think about crafting a blade completely; each curve and angle is designed for precision. Right here’s a glimpse into the world of fine-tuning:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration, RagConfig
from transformers import TextDataset, DataCollatorForLanguageModeling, Coach, TrainingArguments
# Load and preprocess your dataset
dataset = TextDataset(tokenizer=tokenizer, file_path="path_to_your_dataset.txt")
# Outline coaching arguments
training_args = TrainingArguments(
output_dir="./output",
num_train_epochs=3,
per_device_train_batch_size=4,
save_steps=500,
save_total_limit=2
)
# Initialize and prepare the mannequin
model_config = RagConfig.from_pretrained("fb/rag-token-base")
mannequin = RagSequenceForGeneration.from_pretrained("fb/rag-token-base",
config=model_config)
coach = Coach(
mannequin=mannequin,
args=training_args,
data_collator=data_collator,
train_dataset=dataset
)
coach.prepare()
Superior RAG Configurations
Venturing additional, we uncover the secrets and techniques of superior RAG configurations. Each adjustment impacts the result. Altering parameters like max_input_length and max_output_length can considerably alter the generated textual content.
Conclusion
Within the ever-evolving panorama of synthetic intelligence, Retrieval Augmented Era (RAG) is a testomony to the facility of integrating information and language. As we’ve explored, RAG represents a groundbreaking method that marries the depth of exterior information retrieval with the finesse of language technology. It ensures that once you work together with AI, you’re not simply receiving responses based mostly on discovered patterns however participating in conversations rooted in real-world info and context.
This technique combines LLM textual content technology with the power to retrieve or search. It combines an LLM that generates solutions utilizing the information from related doc snippets retrieved from a big corpus and the retriever system. RAG basically aids the mannequin’s capacity to “lookup” exterior info and improve its responses.
Key Takeaways
- Integrating retrieval-based and generation-based fashions, as exemplified by applied sciences like RAG, amplifies the effectiveness of AI conversations, making certain responses grounded in real-world information for accuracy and contextuality.
- Acknowledging the restrictions of conventional NLP fashions fuels innovation, integrating retrieval and technology methods to beat challenges like ambiguity and foster extra significant and nuanced interactions.
- Bridging the hole between retrieval and technology not solely refines AI’s technical points but in addition enhances the human expertise, creating dependable, correct, and deeply contextual responses and reworking conversations into intuitive and empathetic exchanges.
Ceaselessly Requested Questions
A1: Retrieval-based fashions retrieve pre-existing info, whereas generation-based fashions create responses from scratch. Retrieval fashions pull knowledge from present sources, whereas technology fashions assemble responses utilizing discovered patterns.
A2: A limitation of pure retrieval fashions is their incapacity to deal with ambiguous queries successfully, resulting in contextually inappropriate responses. Then again, pure technology fashions may generate artistic however inaccurate responses, particularly when the enter is complicated or nuanced.
A3: Retrieval Augmented Era (RAG) integrates the precision of retrieval fashions and the creativity of technology fashions. It enhances the accuracy and contextuality of AI-generated responses by combining related exterior context with discovered patterns, thus bridging the hole between pure retrieval and technology strategies.
A4: RAG promotes transparency by grounding responses in real-world information, offering clear visibility into the sources used for every prediction. It prevents LLM hallucinations by making certain that responses are factually correct, lowering the probability of producing false or deceptive info.
A5: Embeddings for RAG are created by encoding exterior paperwork into numerical representations, enabling semantic similarity searches. Strategies like language mannequin encoding and fine-tuning tailor these embeddings for particular domains, enhancing the mannequin’s understanding of exterior context and making certain contextually wealthy and correct responses.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Writer’s discretion.


/cdn.vox-cdn.com/uploads/chorus_asset/file/25520051/NASCAR_EV_car.jpg)



