


Have you ever ever questioned how present AI methods, like these powering chatbots and language fashions, can comprehend and generate pure language so successfully? The reply lies of their capacity to memorize and mix data fragments, a course of that has lengthy eluded conventional machine studying methods. This paper explores a novel method referred to as “Reminiscence Mosaics,” which goals to make clear this intricate course of and probably pave the best way for extra clear and disentangled AI methods.
Whereas transformer-based fashions have undoubtedly revolutionized pure language processing, their internal workings stay largely opaque, akin to a black field. Researchers have lengthy sought strategies to disentangle and perceive how these fashions course of and mix info. Reminiscence Mosaics, a studying system structure with a number of associative recollections working collectively to carry out prediction duties, presents a promising resolution.
Associative recollections, the core elements of Reminiscence Mosaics, retailer and retrieve key-value pairs. Right here’s how they work:
- Formally, associative reminiscence is a tool that shops key-value pairs (okay1, v1), (okay2, v2), …, (okayn, vn), the place keys and values are vectors in Rd.
- Given a question key okay, the retrieval course of estimates the conditional likelihood distribution P(V|Okay) based mostly on the saved pairs and returns the conditional expectation E(V|Okay=okay) as the anticipated worth.
- This conditional expectation may be computed utilizing Gaussian kernel smoothing, drawing parallels to classical consideration mechanisms.
- Nonetheless, Reminiscence Mosaics differ from transformers in notable methods, reminiscent of missing place encoding, not distinguishing between keys and queries, and explicitly representing the prediction targets by means of worth extraction features.
Throughout coaching, the important thing and worth extraction features are optimized, permitting every associative reminiscence unit to concentrate on memorizing related features of the enter knowledge effectively.
The true energy of Reminiscence Mosaics lies in its capacity to realize “predictive disentanglement.” This course of entails breaking down the general prediction job into smaller, unbiased subtasks, that are then assigned to particular person associative reminiscence items.
For instance this idea, take into account the instance utilized by the researchers: Think about three moons orbiting a distant planet. Whereas astronomers might not absolutely perceive celestial mechanics, they’ll observe periodic motions and purpose to foretell future moon positions. One astronomer proposes compiling a single desk containing the day by day positions of all three moons, assuming that if the present configuration matches a earlier statement, the long run positions will comply with the identical sample. One other astronomer suggests creating three separate tables, one for every moon, arguing that the long run place of every moon may be independently predicted based mostly on its present place and previous observations.
This analogy highlights the essence of predictive disentanglement. By permitting every reminiscence unit to deal with a particular subtask (predicting the place of a single moon), the general prediction drawback turns into extra effectively solvable than memorizing all three moons’ mixed positions concurrently.
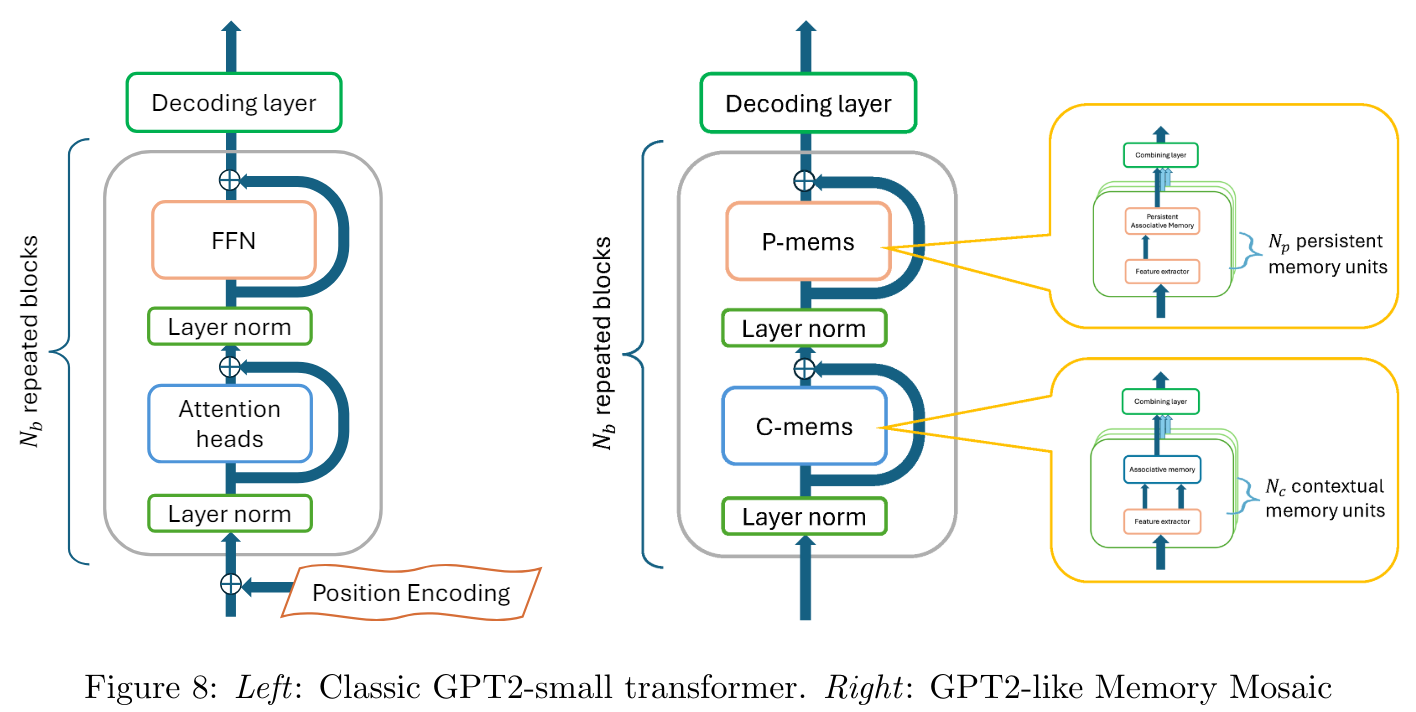
Constructing upon this precept, Reminiscence Mosaics employs a hierarchical construction with layered recollections. Whereas some reminiscence items function at a contextual degree, memorizing and predicting based mostly on the quick enter sequence, others function persistent recollections, retaining data distilled from the coaching course of itself.
This structure, known as Reminiscence Mosaics carefully resembles transformers in its general construction. Nonetheless, it replaces the eye heads and feed-forward networks with contextual and protracted reminiscence items (proven in Determine 8), respectively. The important thing and worth extraction features, together with the mix methods, are realized throughout coaching, enabling the community to disentangle and reassemble data fragments as wanted.
The researchers rigorously evaluated Reminiscence Mosaics’ efficiency, pitting it in opposition to conventional transformer architectures and different state-of-the-art fashions. The outcomes are encouraging:
- On language modeling duties, reminiscent of producing continuations for prompts designed to check factual, logical, and narrative consistency, Reminiscence Mosaics carried out comparably to or higher than transformers.
- When examined on out-of-distribution knowledge, like predicting textual content from Easy English Wikipedia articles, Reminiscence Mosaics exhibited superior in-context studying skills, outperforming transformers after observing sufficient context to determine the distribution shift.
- On the RegBench benchmark, which assesses a mannequin’s capacity to study synthetic languages outlined by probabilistic finite automata, Reminiscence Mosaics considerably outperformed transformers, recurrent neural networks, and state-space fashions throughout a variety of coaching set sizes.
- Reminiscence Mosaics’ consideration patterns revealed a notably flat distribution, suggesting a extra balanced consideration of contextual info in comparison with transformers’ tendency to fixate on particular positions or overlook distant tokens.
Whereas additional analysis is required to scale these findings to bigger fashions, the implications are profound. Reminiscence Mosaics provide a clear and interpretable method to compositional studying methods, shedding mild on the intricate course of of information fragmentation and recombination that underpins language understanding and era.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 42k+ ML SubReddit
Vineet Kumar is a consulting intern at MarktechPost. He’s presently pursuing his BS from the Indian Institute of Expertise(IIT), Kanpur. He’s a Machine Studying fanatic. He’s obsessed with analysis and the most recent developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.


/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



