


In massive language fashions (LLMs), the problem of maintaining data up-to-date is critical. As information evolves, these fashions should adapt to incorporate the most recent data. Nevertheless, updating LLMs historically includes retraining, which is resource-intensive. Another strategy, mannequin enhancing, provides a approach to replace the information inside these fashions extra effectively. This strategy has garnered rising curiosity on account of its potential for making particular, focused adjustments to a mannequin’s information base with out the necessity for full retraining.
The first problem addressed on this analysis is fake or outdated data inside LLMs, resulting in inaccuracies or hallucinations of their outputs. With real-world information’s huge and dynamic nature, LLMs like GPT-3.5 should be repeatedly up to date to take care of their accuracy and relevance. Nevertheless, standard strategies for updating these fashions are resource-intensive and threat dropping the overall skills acquired throughout their preliminary coaching.
Present strategies of mannequin enhancing are broadly categorized into meta-learning and locate-then-edit approaches. Whereas these strategies have proven effectiveness in numerous eventualities, they have a tendency to focus excessively on enhancing efficiency, typically on the expense of the mannequin’s normal skills. The research highlights the crucial must protect these skills throughout enhancing. The analysis emphasizes that enhancing the factual accuracy of LLMs ought to keep their effectiveness throughout a various vary of duties.
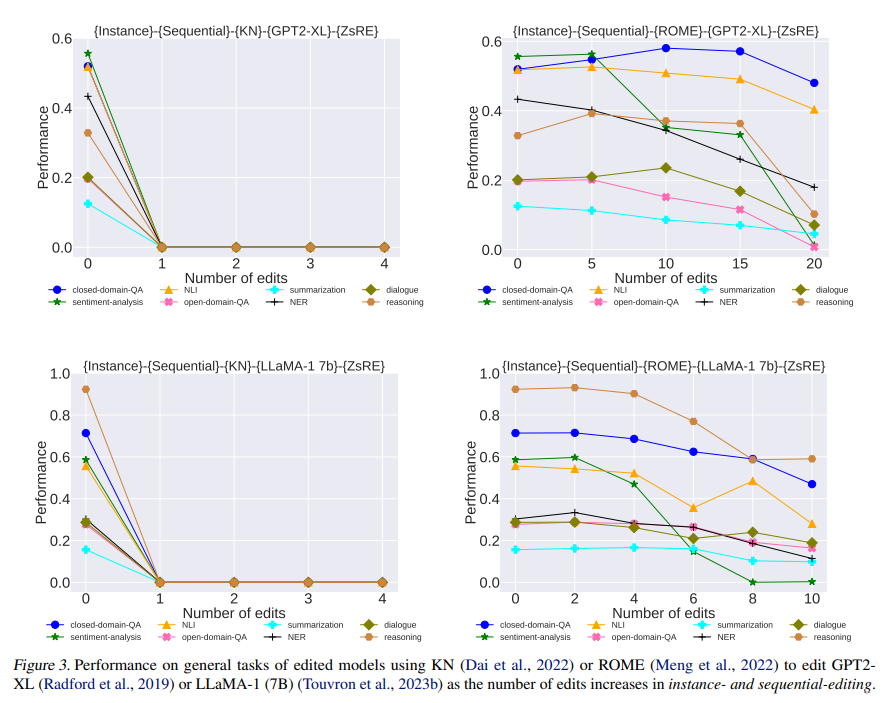
A group of researchers from the College of California Los Angeles and the College of Science and Expertise of China systematically evaluated the unwanted side effects of 4 common enhancing strategies on two different-sized LLMs throughout eight consultant activity classes. These strategies embrace Data Neurons (KN), Mannequin Enhancing Networks (MEND), ROME, and MEMIT. The duties cowl reasoning, pure language inference, open and closed-domain query answering, dialogue, summarization, named entity recognition, and sentiment evaluation. The findings reveal that whereas mannequin enhancing can enhance factual accuracy, it considerably impairs the overall skills of LLMs. This means a considerable problem for the sustainable improvement of LLMs, suggesting that the pursuit of correct enhancements should be balanced with the necessity to keep total mannequin effectiveness.
The research explores the affect of occasion and sequential enhancing, in addition to the impact of batch dimension on enhancing efficiency. In instance and sequential enhancing, even a single focused adjustment to LLMs leads to notable fluctuations and usually a downward development in efficiency throughout numerous duties. This implies that present LLMs, significantly bigger fashions like LLaMA-1 (7B), are usually not strong to weight updates and that slight perturbations can considerably have an effect on their efficiency.
In batch enhancing, the place a number of items of information are up to date concurrently, the research discovered that efficiency typically degrades because the batch dimension will increase. This underscores the challenges in scaling up mannequin enhancing and highlights the necessity for extra analysis on designing scalable enhancing strategies that may deal with a number of edits effectively.
In conclusion, the research requires a renewed concentrate on mannequin enhancing. It emphasizes the significance of devising strategies that not solely improve factual accuracy but in addition protect and enhance the overall skills of LLMs. It additionally means that future analysis ought to focus on strengthening LLMs’ robustness to weight updates, innovating new enhancing paradigms, and designing complete analysis methodologies to evaluate the effectiveness and robustness of enhancing strategies precisely. This strategy will make sure the sustainable improvement of LLMs, making them extra dependable and versatile for real-world purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our Telegram Channel
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.





