Introduction
The provision of data is significant in in the present day’s data-driven atmosphere. For a lot of makes use of, resembling aggressive evaluation, market analysis, and primary information assortment for evaluation, effectively extracting information from web sites is essential. Custom-based handbook information assortment strategies could be time-consuming and unproductive. Nonetheless, on-line scraping offers an automatic technique for quickly and successfully gathering information from web sites. This text will introduce you to Selenium, essentially the most potent and adaptable internet scraping expertise out there.
What’s Net Scraping?
Net scraping entails the automated extraction of knowledge from web sites. It encompasses fetching the net web page, parsing its contents, and extracting the specified data. This course of might vary from easy duties like extracting product costs from an e-commerce web site to extra complicated operations like scraping dynamic content material from internet functions.
Historically, internet scraping was carried out utilizing libraries like BeautifulSoup in Python, which parse the HTML content material of internet pages. Nonetheless, this strategy has limitations, particularly when coping with dynamic content material loaded through JavaScript. That is the place Selenium shines.
Introducing Selenium
Selenium is a strong automation software primarily used for testing internet functions. Nonetheless, its capabilities lengthen past testing to incorporate internet scraping. In contrast to conventional scraping libraries, Selenium interacts with internet pages in the identical means a person would, enabling it to deal with dynamic content material successfully.
Within the digital panorama, the place web sites aren’t simply static pages however dynamic platforms, testing and interacting with internet functions pose distinctive challenges. That is the place Selenium, an open-source automation testing software, emerges as a game-changer. Past its testing capabilities, this library has turn into synonymous with internet scraping. It has empowered builders and information lovers to extract precious data from the huge expanse of the web.
At its core, Selenium is a set of instruments and libraries designed to automate internet browsers throughout totally different platforms. Initially developed by Jason Huggins in 2004 as an inner software at ThoughtWorks, Selenium has advanced into a sturdy ecosystem, providing numerous functionalities to fulfill the varied wants of internet builders and testers.
Key Elements of Selenium
Selenium contains a number of key elements, every serving a selected objective within the internet automation course of:
- Selenium WebDriver: WebDriver is the cornerstone of Selenium, offering a programming interface to work together with internet browsers. It permits customers to simulate person interactions resembling clicking buttons, coming into textual content, and navigating by way of internet pages programmatically.
- Selenium IDE: IDE, brief for Built-in Growth Setting, provides a browser extension for Firefox and Chrome that facilitates record-and-playback testing. Whereas primarily used for fast prototyping and exploratory testing, Selenium IDE serves as an entry level for freshmen to acquaint themselves with Selenium’s capabilities.
- Selenium Grid: Selenium Grid allows parallel execution of checks throughout a number of browsers and platforms, making it ideally suited for large-scale take a look at automation initiatives. By distributing take a look at execution, Selenium Grid considerably reduces the general take a look at execution time, enhancing effectivity and scalability.
Getting Began with Selenium
Earlier than diving into Selenium, you might want to arrange your improvement atmosphere.
Putting in Selenium
Selenium is primarily a Python library, so guarantee you will have Python put in in your system. You may set up Selenium utilizing pip, Python’s bundle supervisor, by working the next command in your terminal:
pip set up seleniumMoreover, you’ll want to put in a WebDriver for the browser you plan to automate. WebDriver acts as a bridge between your Selenium scripts and the net browser. You may obtain WebDriver executables for fashionable browsers like Chrome, Firefox, and Edge from their respective web sites or bundle managers.
Setting Up Your First Selenium Venture
With Selenium put in, you’re able to create your first challenge. Open your most popular code editor and create a brand new Python script (e.g., my_first_selenium_script.py). On this script, you’ll write the code to automate browser interactions.
Writing Your First Selenium Script
Let’s begin with a easy Selenium script to open an online web page in a browser. Beneath is an instance script utilizing Python:
from selenium import webdriver# Initialize the WebDriver (substitute 'path_to_driver' with the trail to your WebDriver executable)
driver = webdriver.Chrome('path_to_driver')# Open an online web page
driver.get('https://www.instance.com')# Shut the browser window
driver.stop()Finding Parts with Selenium
Selenium provides two major strategies for finding components:
- find_element: Finds the primary aspect matching the desired standards.
- find_elements: Finds all components matching the desired standards, returning a listing.
These strategies are important for navigating by way of an online web page and extracting desired data effectively.
Attributes Accessible for Finding Parts
Selenium’s By class offers numerous attributes for finding components on a web page. These attributes embody ID, Title, XPath, Hyperlink Textual content, Partial Hyperlink Textual content, Tag Title, Class Title, and CSS Selector.
Every attribute serves a selected objective and could be utilized based mostly on the distinctive traits of the weather being focused.
Finding Parts by Particular Attributes
Let’s discover some widespread methods for finding components utilizing particular attributes:
- ID: Ultimate for finding components with a novel identifier.
- Title: Helpful when components are recognized by their identify attribute.
- XPath: A robust language for finding nodes in an XML doc, XPath is flexible and might goal components based mostly on numerous standards.
- Hyperlink Textual content and Partial Hyperlink Textual content: Efficient for finding hyperlinks based mostly on their seen textual content.
- Tag Title: Helpful for concentrating on components based mostly on their HTML tag.
- Class Title: Locates components based mostly on their class attribute.
- CSS Selector: Employs CSS selector syntax to find components, providing flexibility and precision.
Primary Scraping with Selenium
Let’s take into account a easy instance of scraping the titles of articles from a information web site.
# Open the webpage
driver.get("https://instance.com/information")
# Discover all article titles
titles = driver.find_elements_by_xpath("//h2[@class="article-title"]")
# Extract and print the titles
for title in titles:
print(title.textual content)On this instance, we first navigate to the specified webpage utilizing driver.get(). Then, we use find_elements_by_xpath() to find all HTML components containing article titles. Lastly, we extract the textual content of every title utilizing the .textual content attribute.
Dealing with Dynamic Content material
One of many key benefits of Selenium is its potential to deal with web sites with dynamic content material. This contains content material loaded through JavaScript or content material that seems solely after person interactions (e.g., clicking a button).
# Click on on a button to load extra content material
load_more_button = driver.find_element_by_xpath("//button[@id='load-more']")
load_more_button.click on()
# Anticipate the brand new content material to load
driver.implicitly_wait(10) # Anticipate 10 seconds for the content material to load
# Scraping the newly loaded content material
new_titles = driver.find_elements_by_xpath("//h2[@class="article-title"]")
for title in new_titles:
print(title.textual content)Right here, we simulate clicking a “Load Extra” button utilizing click on(). We then look forward to the brand new content material to load utilizing implicitly_wait(), making certain that the scraper waits for a specified period of time earlier than continuing.
Instance: Scraping Wikipedia
On this instance, I’ll show easy methods to scrape data associated to “Information Science” from Wikipedia utilizing Selenium, a strong software for internet scraping and automation. We’ll stroll by way of the method of navigating to the Wikipedia web page, finding particular components resembling paragraphs and hyperlinks, and extracting related content material. You may scrape another web sites after studying this text by making use of totally different methods.
Earlier than scraping, let’s start by inspecting the webpage. Proper-click on the paragraph you want to scrape, and a context menu will seem.
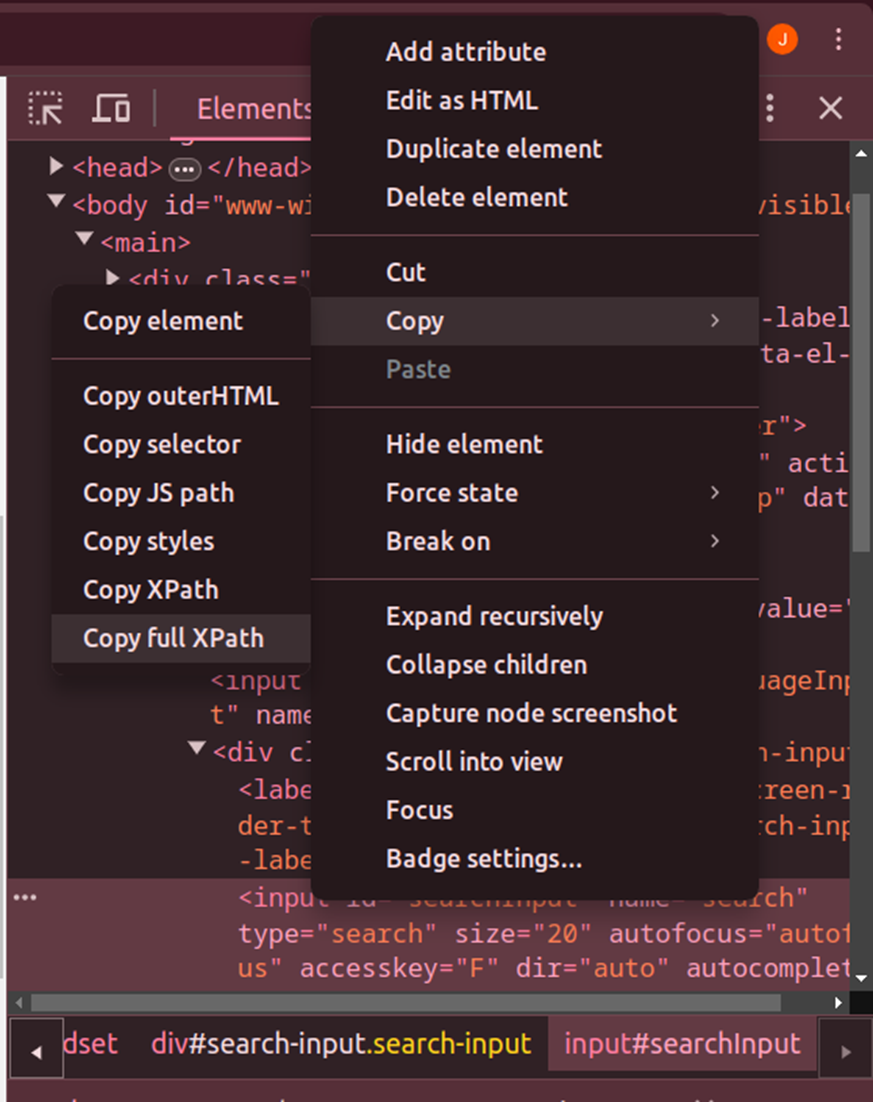
Click on proper once more on the context menu to seek out the Copy choices. Then choose ‘Copy full XPath’, ‘Copy XPath’, or another obtainable choices to entry the HTML doc. That is how we will likely be utilizing XPATH.
Step 1: Import the Obligatory Libraries
from selenium import webdriver
from selenium.webdriver.chrome.choices import Choices
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.widespread.by import ByStep 2: Initialize the WebDriver for Chrome
Now, let’s initialize the WebDriver for Chrome with customized choices and repair configuration.
Obtain the Chrome WebDriver by clicking on this hyperlink: https://chromedriver.chromium.org/downloads
Confirm the compatibility of your Chrome and WebDriver variations.
For various browsers, you may obtain the WebDriver from these hyperlinks:
chrome_options = Choices()
chrome_service = Service('/residence/jaanvi/calldetailfolder/chromedriver-linux64/chromedriver')
driver=webdriver.Chrome(service=chrome_service, choices = chrome_options) Step 3: Start the Web site Scraping Course of
1. Let’s open the Wikipedia web site.
driver.get('https://www.wikipedia.org/')2. Now search utilizing the search field . You may get the XPATH by doing proper click on and click on on examine and duplicate the Xpath.
Kind = driver.find_element(By.XPATH,
"/html/physique/primary/div[2]/kind/fieldset/div/enter")
Kind.send_keys('Information Science')3. Now let’s click on on the search button.
Search=driver.find_element(By.XPATH,
"/html/physique/primary/div[2]/kind/fieldset/button/i")
Search.click on()4. Let’s extract the only paragraph.
single_para=driver.find_element(By.XPATH,
"/html/physique/div[2]/div/div[3]/primary/div[3]/div[3]/div[1]/p[2]")
print(single_para.textual content)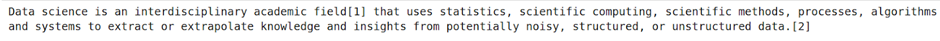
5. Now let’s extract all of the paragraphs utilizing the ID.
para=driver.find_element(By.ID,"mw-content-text")
print(para.textual content)
6. Navigating by way of the desk of contents.
navigating= driver.find_element(By.XPATH,
"/html/physique/div[2]/div/div[2]/div[2]/nav/div/div/ul/li[4]/a/div")
navigating.click on()7. Accessing the content material utilizing the desk of contents.
opening_link=driver.find_elements(By.XPATH,
"/html/physique/div[2]/div/div[3]/primary/div[3]/div[3]/div[1]/p[17]/a[2]")8. Opening a selected hyperlink from the desk of contents.
opening_link = driver.find_elements(By.XPATH,
"/html/physique/div[2]/div/div[3]/primary/div[3]/div[3]/div[1]/p[17]/a[2]")
opening_link.click on()9. Finding and clicking hyperlinks by textual content.
continue_link = driver.find_element(By.LINK_TEXT, 'information visualization')
continue_link.click on()10. May find utilizing Partial_LINK_TEXT.
continue_link = driver.find_element(By.PARTIAL_LINK_TEXT, 'donut ')
continue_link.click on()11. Finding content material by CSS Selector and printing its textual content.
content material = driver.find_element(By.CSS_SELECTOR,
'#mw-content-text > div.mw-content-ltr.mw-parser-output > desk > tbody')
content material.textual content
On this instance, we harnessed Selenium’s capabilities to scrape Wikipedia for Information Science data. Selenium, recognized primarily for internet software testing, proved invaluable in effectively extracting information from internet pages. By means of Selenium, we navigated complicated internet buildings, using strategies like XPath, ID, and CSS Selector for aspect location. This flexibility facilitated dynamic interplay with internet components resembling paragraphs and hyperlinks. By extracting focused content material, together with paragraphs and hyperlinks, we gathered pertinent Information Science data from Wikipedia. This extracted information could be additional analyzed and processed to serve numerous functions, showcasing Selenium’s prowess in internet scraping endeavors.
Conclusion
Selenium provides a strong and versatile answer for internet scraping, particularly when coping with dynamic content material. By mimicking person interactions, it allows the scraping of even essentially the most complicated internet pages. Nonetheless, it’s important to make use of it responsibly and cling to web site phrases of service and authorized rules. With the fitting strategy, it may be a precious software for extracting precious information from the net. Whether or not you’re an information scientist, a enterprise analyst, or a curious particular person, mastering internet scraping with Selenium opens up a world of potentialities for accessing and using internet information successfully.
Steadily Requested Questions
A. Selenium is an open-source automation software primarily used for testing internet functions. Its major use is to automate internet browsers for testing functions, however additionally it is extensively utilized for internet scraping.
A. Selenium contains a number of key elements, together with WebDriver, Selenium IDE, and Selenium Grid. WebDriver is the cornerstone, offering a programming interface for browser automation. Selenium IDE provides a record-and-playback performance, whereas Selenium Grid allows parallel execution of checks throughout a number of browsers and platforms.
A. Selenium helps a number of programming languages, together with Python, Java, C#, Ruby, and JavaScript. Customers can select their most popular language based mostly on their familiarity and challenge necessities.
A. Selenium could be put in utilizing bundle managers like pip for Python. Moreover, customers have to obtain and configure WebDriver executables for the browsers they intend to automate.
A. Selenium offers numerous strategies for finding components on an online web page, together with find_element, find_elements, and strategies based mostly on attributes like ID, XPath, CSS Selector, and so on.
A. Sure, Selenium can be utilized for large-scale internet scraping initiatives, particularly when mixed with Selenium Grid for parallel execution throughout a number of browsers and platforms. Nonetheless, customers ought to be conscious of web site phrases of service and authorized concerns when conducting large-scale scraping.