Giant Language Fashions (LLMs) have revolutionized Pure Language Processing (NLP), notably in Query Answering (QA). Nonetheless, hallucination stays a big impediment as LLMs might generate factually inaccurate or ungrounded responses. Research reveal that even state-of-the-art fashions like GPT-4 wrestle with precisely answering questions involving altering info or much less common entities. Overcoming hallucinations is essential for creating dependable QA methods. Retrieval-Augmented Era (RAG) has emerged as a promising method to handle LLMs’ data deficiencies, but it surely faces challenges like choosing related info, decreasing latency, and synthesizing info for complicated queries.
Researchers from Meta Actuality Labs, FAIR, Meta, HKUST, and HKUST (GZ) proposed a benchmark known as CRAG (Complete benchmark for RAG), which goals to include 5 important options: realism, richness, insightfulness, reliability, and longevity. It accommodates 4,409 numerous QA pairs from 5 domains, together with easy fact-based and 7 forms of complicated questions. CRAG covers various entity reputation and temporal spans to allow insights. The questions are manually verified and paraphrased for realism and reliability. Additionally, CRAG gives mock APIs simulating retrieval from net pages (by way of Courageous Search API) and mock data graphs with 2.6 million entities, reflecting reasonable noise. The benchmark affords three duties to judge the online retrieval, structured querying, and summarisation capabilities of RAG options.

A RAG QA system entails three duties designed to judge the totally different capabilities of the methods. All duties share the identical set of (query, reply) pairs however differ within the exterior knowledge accessible for retrieval to enhance reply era. Job 1 (Retrieval Summarization) gives as much as 5 doubtlessly related net pages per query to check the reply era functionality. Job 2 (KG and Net Retrieval Augmentation) additional gives mock APIs to entry structured knowledge from data graphs (KGs), inspecting the system’s means to question structured sources and synthesize info. Job 3 is much like Job 2, however gives 50 net pages as an alternative of 5 as retrieval candidates, testing the system’s means to rank and make the most of a bigger set of doubtless noisy however extra complete info.
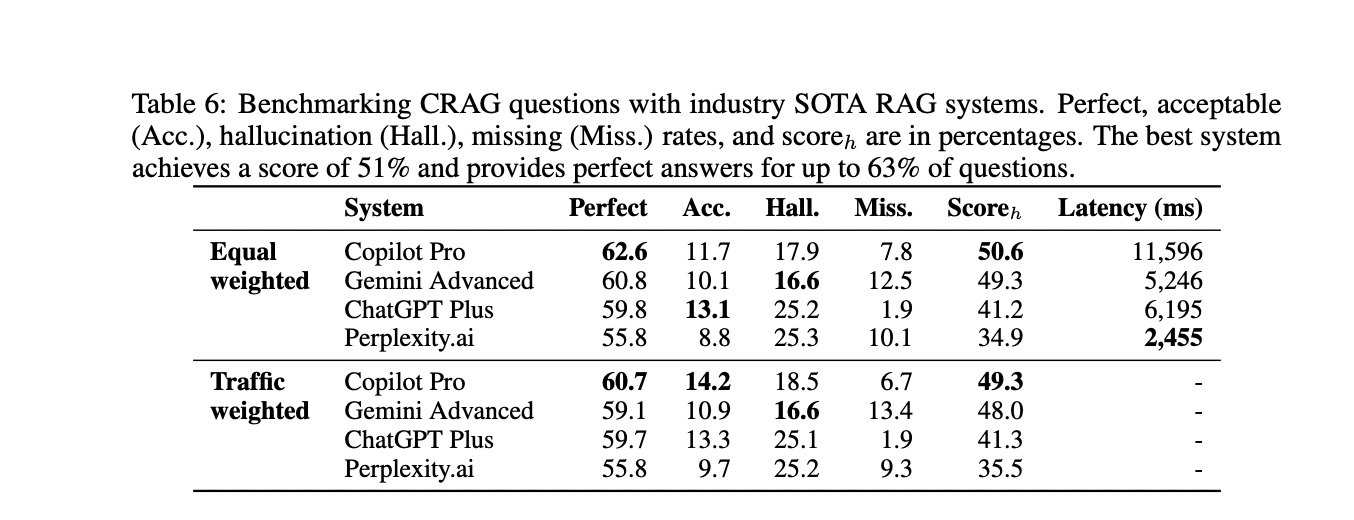
The outcomes and comparisons show the effectiveness of the proposed CRAG benchmark. Whereas superior language fashions like GPT-4 obtain solely round 34% accuracy on CRAG, incorporating simple RAG improves accuracy to 44%. Nonetheless, even state-of-the-art trade RAG options reply solely 63% of questions with out hallucination, fighting info of upper dynamism, decrease reputation, or larger complexity. These evaluations spotlight that CRAG has an acceptable degree of problem and permits insights from its numerous knowledge. The evaluations additionally underscore the analysis gaps in direction of creating absolutely reliable question-answering methods, making CRAG a beneficial benchmark for driving additional progress on this discipline.
On this research, the researchers introduce CRAG, a complete benchmark that goals to propel analysis in RAG for question-answering methods. Via rigorous empirical evaluations, CRAG exposes shortcomings in current RAG options and affords beneficial insights for future enhancements. The benchmark’s creators plan to constantly improve and develop CRAG to incorporate multi-lingual questions, multi-modal inputs, multi-turn conversations, and extra. This ongoing improvement ensures CRAG stays on the vanguard of driving RAG analysis, adapting to rising challenges, and evolving to handle new analysis wants on this quickly progressing discipline. The benchmark gives a sturdy basis for advancing dependable, grounded language era capabilities.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Neglect to affix our 44k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.