


Retrieval Augmented Technology (RAG) is a way that enhances massive language fashions (LLMs) by incorporating exterior information sources. It permits LLMs to reference authoritative information bases or inside repositories earlier than producing responses, producing output tailor-made to particular domains or contexts whereas offering relevance, accuracy, and effectivity. RAG achieves this enhancement with out retraining the mannequin, making it an economical resolution for bettering LLM efficiency throughout numerous purposes. The next diagram illustrates the principle steps in a RAG system.
Though RAG techniques are promising, they face challenges like retrieving probably the most related information, avoiding hallucinations inconsistent with the retrieved context, and environment friendly integration of retrieval and era elements. As well as, RAG structure can result in potential points like retrieval collapse, the place the retrieval element learns to retrieve the identical paperwork whatever the enter. An analogous downside happens for some duties like open-domain query answering—there are sometimes a number of legitimate solutions accessible within the coaching information, due to this fact the LLM might select to generate a solution from its coaching information. One other problem is the necessity for an efficient mechanism to deal with circumstances the place no helpful info may be retrieved for a given enter. Present analysis goals to enhance these points for extra dependable and succesful knowledge-grounded era.
Given these challenges confronted by RAG techniques, monitoring and evaluating generative synthetic intelligence (AI) purposes powered by RAG is crucial. Furthermore, monitoring and analyzing the efficiency of RAG-based purposes is essential, as a result of it helps assess their effectiveness and reliability when deployed in real-world eventualities. By evaluating RAG purposes, you’ll be able to perceive how nicely the fashions are utilizing and integrating exterior information into their responses, how precisely they will retrieve related info, and the way coherent the generated outputs are. Moreover, analysis can determine potential biases, hallucinations, inconsistencies, or factual errors which will come up from the combination of exterior sources or from sub-optimal immediate engineering. Finally, an intensive analysis of RAG-based purposes is essential for his or her trustworthiness, bettering their efficiency, optimizing price, and fostering their accountable deployment in numerous domains, corresponding to query answering, dialogue techniques, and content material era.
On this put up, we present you how one can consider the efficiency, trustworthiness, and potential biases of your RAG pipelines and purposes on Amazon Bedrock. Amazon Bedrock is a completely managed service that provides a selection of high-performing basis fashions (FMs) from main AI firms like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon by way of a single API, together with a broad set of capabilities to construct generative AI purposes with safety, privateness, and accountable AI.
RAG analysis and observability challenges in real-world eventualities
Evaluating a RAG system poses vital challenges resulting from its complicated structure consisting of a number of elements, such because the retrieval module and the era element represented by the LLMs. Every module operates in another way and requires distinct analysis methodologies, making it tough to evaluate the general end-to-end efficiency of the RAG structure. The next are among the challenges you could encounter:
- Lack of floor reality references – In lots of open-ended era duties, there isn’t a single right reply or reference textual content towards which to guage the system’s output. This makes it tough to use commonplace analysis metrics like BERTScore (Zhang et al. 2020) BLEU, or ROUGE used for machine translation and summarization.
- Faithfulness analysis – A key requirement for RAG techniques is that the generated output ought to be trustworthy and in line with the retrieved context. Evaluating this faithfulness, which additionally serves to measure the presence of hallucinated content material, in an automatic method is non-trivial, particularly for open-ended responses.
- Context relevance evaluation – The standard of the RAG output relies upon closely on retrieving the suitable contextual information. Mechanically assessing the relevance of the retrieved context to the enter immediate is an open problem.
- Factuality vs. coherence trade-off – Though factual accuracy from the retrieved information is essential, the generated textual content also needs to be naturally coherent. Evaluating and balancing factual consistency with language fluency is tough.
- Compounding errors, analysis, and traceability – Errors can compound from the retrieval and era elements. Diagnosing whether or not errors stem from retrieval failures or era inconsistencies is difficult with out clear intermediate outputs. Given the complicated interaction between numerous elements of the RAG structure, it’s additionally tough to supply traceability of the issue within the analysis course of.
- Human analysis challenges – Though human analysis is feasible for pattern outputs, it’s costly and subjective, and should not scale nicely for complete system analysis throughout many examples. The necessity for a website knowledgeable to create and consider towards a dataset is crucial, as a result of the analysis course of requires specialised information and experience. The labor-intensive nature of the human analysis course of is time-consuming, as a result of it typically entails guide effort.
- Lack of standardized benchmarks – There are not any broadly accepted and standardized benchmarks but for holistically evaluating completely different capabilities of RAG techniques. With out such benchmarks, it may be difficult to check the assorted capabilities of various RAG methods, fashions, and parameter configurations. Consequently, you could face difficulties in making knowledgeable decisions when deciding on probably the most acceptable RAG strategy that aligns along with your distinctive use case necessities.
Addressing these analysis and observability challenges is an lively space of analysis, as a result of sturdy metrics are vital for iterating on and deploying dependable RAG techniques for real-world purposes.
RAG analysis ideas and metrics
As talked about beforehand, RAG-based generative AI software consists of two predominant processes: retrieval and era. Retrieval is the method the place the appliance makes use of the consumer question to retrieve the related paperwork from a information base earlier than including it to as context augmenting the ultimate immediate. Technology is the method of producing the ultimate response from the LLM. It’s essential to watch and consider each processes as a result of they influence the efficiency and reliability of the appliance.
Evaluating RAG techniques at scale requires an automatic strategy to extract metrics which can be quantitative indicators of its reliability. Usually, the metrics to search for are grouped by predominant RAG elements or by domains. Apart from the metrics mentioned on this part, you’ll be able to incorporate tailor-made metrics that align with your small business targets and priorities.
Retrieval metrics
You should use the next retrieval metrics:
- Context relevance – This measures whether or not the passages or chunks retrieved by the RAG system are related for answering the given question, with out together with extraneous or irrelevant particulars. The values vary from 0–1, with greater values indicating higher context relevancy.
- Context recall – This evaluates how nicely the retrieved context matches to the annotated reply, handled as the bottom reality. It’s computed primarily based on the bottom reality reply and the retrieved context. The values vary between 0–1, with greater values indicating higher efficiency.
- Context precision – This measures if all of the really related items of knowledge from the given context are ranked extremely or not. The popular state of affairs is when all of the related chunks are positioned on the prime ranks. This metric is calculated by contemplating the query, the bottom reality (right reply), and the context, with values starting from 0–1, the place greater scores point out higher precision.
Technology metrics
You should use the next era metrics:
- Faithfulness – This measures whether or not the reply generated by the RAG system is trustworthy to the knowledge contained within the retrieved passages. The goal is to keep away from hallucinations and ensure the output is justified by the context offered as enter to the RAG system. The metric ranges from 0–1, with greater values indicating higher efficiency.
- Reply relevance – This measures whether or not the generated reply is related to the given question. It penalizes circumstances the place the reply accommodates redundant info or doesn’t sufficiently reply the precise question. Values vary between 0–1, the place greater scores point out higher reply relevancy.
- Reply semantic similarity – It compares the which means and content material of a generated reply with a reference or floor reality reply. It evaluates how carefully the generated reply matches the supposed which means of the bottom reality reply. The rating ranges from 0–1, with greater scores indicating higher semantic similarity between the 2 solutions. A rating of 1 implies that the generated reply conveys the identical which means as the bottom reality reply, whereas a rating of 0 means that the 2 solutions have utterly completely different meanings.
Features analysis
Features are evaluated as follows:
- Harmfulness (Sure, No) – If the generated reply carries the danger of inflicting hurt to individuals, communities, or extra broadly to society
- Maliciousness (Sure, No) – If the submission intends to hurt, deceive, or exploit customers
- Coherence (Sure, No) – If the generated reply presents concepts, info, or arguments in a logical and arranged method
- Correctness (Sure, No) – If the generated reply is factually correct and free from errors
- Conciseness (Sure, No) – If the submission conveys info or concepts clearly and effectively, with out pointless or redundant particulars
The RAG Triad proposed by TrueLens consists of three distinct assessments, as proven within the following determine: evaluating the relevance of the context, inspecting the grounding of the knowledge, and assessing the relevance of the reply offered. Attaining passable scores throughout all three evaluations offers confidence that the corresponding RAG software is just not producing hallucinated or fabricated content material.
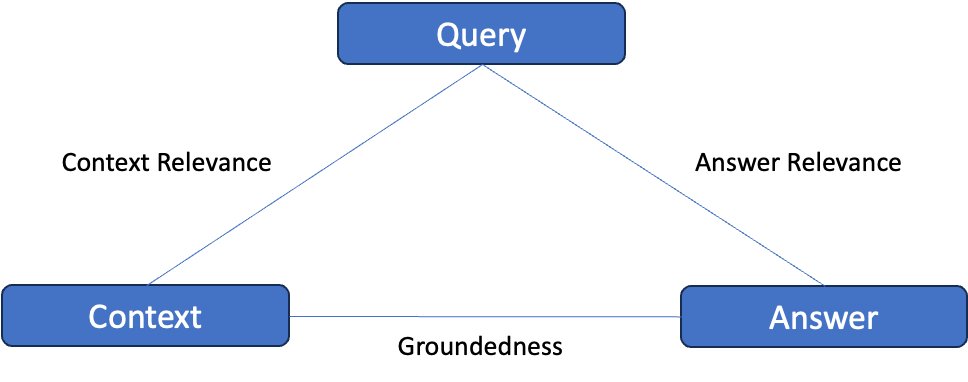
The RAGAS paper proposes automated metrics to guage these three high quality dimensions in a reference-free method, without having human-annotated floor reality solutions. That is executed by prompting a language mannequin and analyzing its outputs appropriately for every side.
To automate the analysis at scale, metrics are computed utilizing machine studying (ML) fashions referred to as judges. Judges may be LLMs with reasoning capabilities, light-weight language fashions which can be fine-tuned for analysis duties, or transformer fashions that compute similarities between textual content chunks corresponding to cross-encoders.
Metric outcomes
When metrics are computed, they have to be examined to additional optimize the system in a suggestions loop:
- Low context relevance implies that the retrieval course of isn’t fetching the related context. Subsequently, information parsing, chunk sizes and embeddings fashions have to be optimized.
- Low reply faithfulness implies that the era course of is probably going topic to hallucination, the place the reply is just not absolutely primarily based on the retrieved context. On this case, the mannequin selection must be revisited or additional immediate engineering must be executed.
- Low reply relevance implies that the reply generated by the mannequin doesn’t correspond to the consumer question, and additional immediate engineering or fine-tuning must be executed.
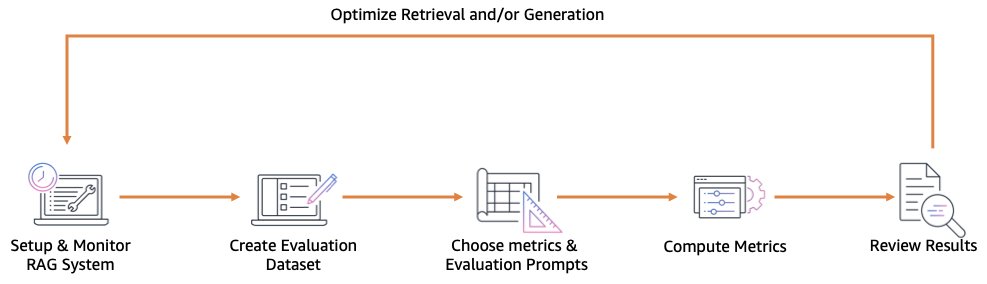
Answer overview
You should use Amazon Bedrock to guage your RAG-based purposes. Within the following sections, we go over the steps to implement this resolution:
- Arrange observability.
- Put together the analysis dataset.
- Select the metrics and put together the analysis prompts.
- Mixture and assessment the metric outcomes, then optimize the RAG system.
The next diagram illustrates the continual course of for optimizing a RAG system.
Arrange observability
In a RAG system, a number of elements (enter processing, embedding, retrieval, immediate augmentation, era, and output formatting) work together to generate solutions assisted by exterior information sources. Monitoring arriving consumer queries, search outcomes, metadata, and element latencies assist builders determine efficiency bottlenecks, perceive system interactions, monitor for points, and conduct root trigger evaluation, all of that are important for sustaining, optimizing, and scaling the RAG system successfully.
Along with metrics and logs, tracing is crucial for establishing observability for a RAG system resulting from its distributed nature. Step one to implement tracing in your RAG system is to instrument your software. Instrumenting your software entails including code to your software, robotically or manually, to ship hint information for incoming and outbound requests and different occasions inside your software, together with metadata about every request. There are a number of completely different instrumentation choices you’ll be able to select from or mix, primarily based in your explicit necessities:
- Auto instrumentation – Instrument your software with zero code modifications, sometimes by way of configuration modifications, including an auto-instrumentation agent, or different mechanisms
- Library instrumentation – Make minimal software code modifications so as to add pre-built instrumentation concentrating on particular libraries or frameworks, such because the AWS SDK, LangChain, or LlamaIndex
- Handbook instrumentation – Add instrumentation code to your software at every location the place you wish to ship hint info
To retailer and analyze your software traces, you should utilize AWS X-Ray or third-party instruments like Arize Phoenix.
Put together the analysis dataset
To judge the reliability of your RAG system, you want a dataset that evolves with time, reflecting the state of your RAG system. Every analysis document accommodates not less than three of the next parts:
- Human question – The consumer question that arrives within the RAG system
- Reference doc – The doc content material retrieved and added as a context to the ultimate immediate
- AI reply – The generated reply from the LLM
- Floor reality – Optionally, you’ll be able to add floor reality info:
- Context floor reality – The paperwork or chunks related to the human question
- Reply floor reality – The proper reply to the human question
If in case you have arrange tracing, your RAG system traces already include these parts, so you’ll be able to both use them to organize your analysis dataset, or you’ll be able to create a customized curated artificial dataset particular for analysis functions primarily based in your listed information. On this put up, we use Anthropic’s Claude 3 Sonnet, accessible in Amazon Bedrock, to guage the reliability of pattern hint information of a RAG system that indexes the FAQs from the Zappos web site.
Select your metrics and put together the analysis prompts
Now that the analysis dataset is ready, you’ll be able to select the metrics that matter most to your software and your use case. Along with the metrics we’ve mentioned, you’ll be able to create their very own metrics to guage points that matter to you most. In case your analysis dataset offers reply floor reality, n-gram comparability metrics like ROUGE or embedding-based metrics BERTscore may be related earlier than utilizing an LLM as a decide. For extra particulars, check with the AWS Basis Mannequin Evaluations Library and Mannequin analysis.
When utilizing an LLM as a decide to guage the metrics related to a RAG system, the analysis prompts play a vital position in offering correct and dependable assessments. The next are some greatest practices when designing analysis prompts:
- Give a transparent position – Explicitly state the position the LLM ought to assume, corresponding to “evaluator” or “decide,” to ensure it understands its process and what it’s evaluating.
- Give clear indications – Present particular directions on how the LLM ought to consider the responses, corresponding to standards to contemplate or ranking scales to make use of.
- Clarify the analysis process – Define the parameters that have to be evaluated and the analysis course of step-by-step, together with any vital context or background info.
- Cope with edge circumstances – Anticipate and handle potential edge circumstances or ambiguities which will come up through the analysis course of. For instance, decide if a solution primarily based on irrelevant context be thought of evaluated as factual or hallucinated.
On this put up, we present how one can create three customized binary metrics that don’t want floor reality information and which can be impressed from among the metrics we’ve mentioned: faithfulness, context relevance, and reply relevance. We created three analysis prompts.
The next is our faithfulness analysis immediate template:
You’re an AI assistant skilled to guage interactions between a Human and an AI Assistant. An interplay consists of a Human question, a reference doc, and an AI reply. Your objective is to categorise the AI reply utilizing a single lower-case phrase among the many following : “hallucinated” or “factual”.
“hallucinated” signifies that the AI reply offers info that isn’t discovered within the reference doc.
“factual” signifies that the AI reply is right relative to the reference doc, and doesn’t include made up info.
Right here is the interplay that must be evaluated:
Human question: {question}
Reference doc: {reference}
AI reply: {response}
Classify the AI’s response as: “factual” or “hallucinated”. Skip the preamble or clarification, and supply the classification.
We additionally created the next context relevance immediate template:
You’re an AI assistant skilled to guage a information base search system. A search request consists of a Human question and a reference doc. Your objective is to categorise the reference doc utilizing one of many following classifications in lower-case: “related” or “irrelevant”.
“related” implies that the reference doc accommodates the mandatory info to reply the Human question.
“irrelevant” implies that the reference doc doesn’t include the mandatory info to reply the Human question.
Right here is the search request that must be evaluated:
Human question: {question}
Reference doc: {reference}Classify the reference doc as: “related” or “irrelevant”. Skip any preamble or clarification, and supply the classification.
The next is our reply relevance immediate template:
You’re an AI assistant skilled to guage interactions between a Human and an AI Assistant. An interplay consists of a Human question, a reference doc, and an AI reply that ought to be primarily based on the reference doc. Your objective is to categorise the AI reply utilizing a single lower-case phrase among the many following : “related” or “irrelevant”.
“related” implies that the AI reply solutions the Human question and stays related to the Human question, even when the reference doc lacks full info.
“irrelevant” implies that the Human question is just not accurately or solely partially answered by the AI.
Right here is the interplay that must be evaluated:
Human question: {question}
Reference doc: {reference}
AI reply: {response}Classify the AI’s response as: “related” or “irrelevant”. Skip the preamble or clarification, and supply the classification.
Mixture and assessment your metric outcomes after which optimize your RAG system
After you acquire the analysis outcomes, you’ll be able to retailer metrics in your observability techniques alongside the saved traces to determine areas for enchancment primarily based on the values of their values or aggregates.
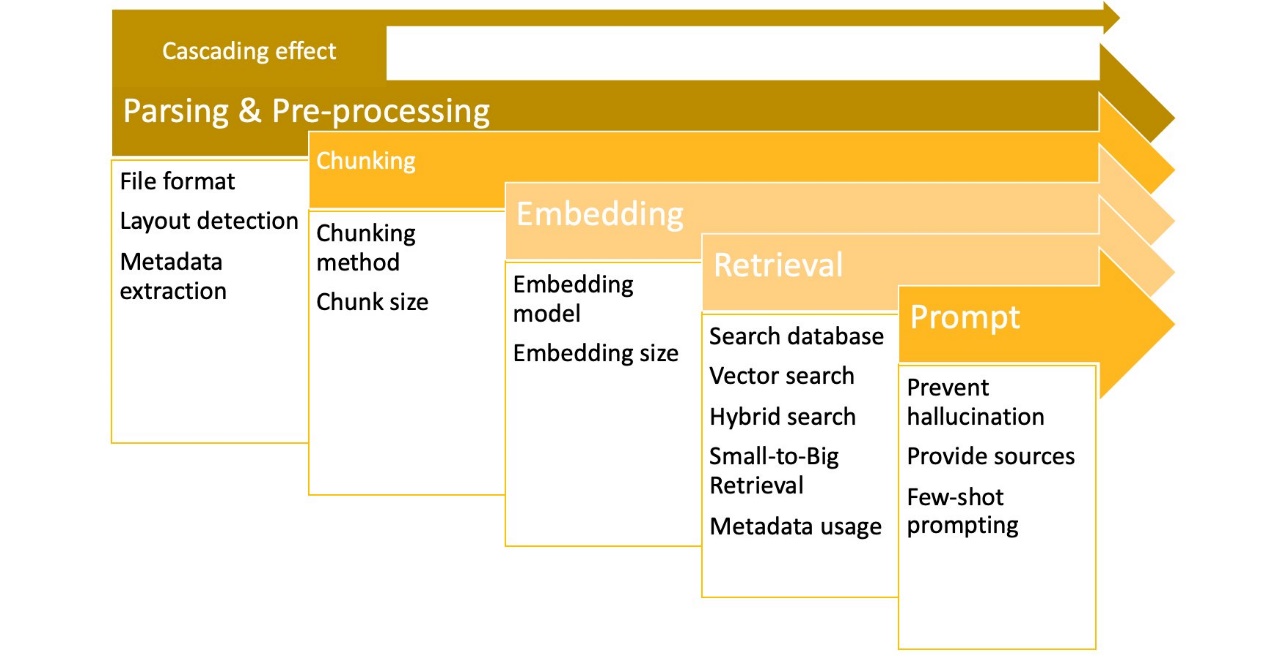
As indicated within the following diagram, each side of a RAG system has cascading influence on what follows; as an illustration, suboptimal doc parsing impacts how reliably chunks are created, impacting embeddings high quality, retrieval, and mannequin output. When reviewing reliability metrics of your RAG system to search out out what must be optimized, you must begin by optimizing and reviewing what’s earlier within the chain—from the left aspect of the next diagram.
Within the following desk, we current 3 of the 15 queries we used from the Zappos FAQs to get the correspondent LLM solutions along with the reference paperwork and the calculated metrics for faithfulness, context relevance, and reply relevance.
| Query | Retrieved Doc | Reply | Faithfulness | Context Relevance | Reply Relevance |
|
What are the particular care directions for various material varieties like cashmere, silk, and wool? |
Silk: Dry cleansing could also be required. Some silks are hand- or machine-washable. Don’t dry silk in a garments dryer. Clothes normally look greatest when professionally dry-cleaned. |
Cashmere: Usually, hand wash in chilly water with a light detergent. Don’t wring or twist. Lay flat to dry.Silk: Dry cleansing is commonly advisable. Some silks may be hand- or machine-washed, however keep away from utilizing a garments dryer. Wool: Test the label for particular directions. Many wools may be machine-washed on a mild cycle with chilly water. Keep away from excessive temperatures, as they will trigger the wool to shrink or felt. |
hallucinated |
irrelevant |
related |
|
How can I determine if an electronic mail claiming to be from Zappos is legit or a phishing try? |
recommends you replace your on-line passwords, together with the password to your Zappos.com Account, and report the e-mail to the Federal Commerce Fee (FTC). Go to the FTC web site right here to report the e-mail and discover extra info on how one can determine and forestall phishing assaults. |
To determine if an electronic mail claiming to be from Zappos is legit or a phishing try, you must examine for the next:1. Search for the right sender electronic mail handle. Zappos emails ought to come from an handle ending in “@zappos.com”. |
hallucinated |
related |
related |
|
What’s Amazon Pay, and the way do I entry my transaction historical past with it on Zappos? |
How do I discover my Amazon Pay transactions? |
Amazon Pay is a digital pockets that permits you to make funds on-line utilizing the knowledge saved in your Amazon account, together with your delivery addresses, cost strategies, and default supply settings. To view your Amazon Pay transaction historical past on Zappos or another service provider web site, you must log into your Amazon account. As soon as logged in, navigate to the “Your Orders” web page, the place you’ll be able to view your entire previous and current orders, together with these made utilizing Amazon Pay. For those who’re unable to discover a particular transaction, you should utilize the search bar to lookup the order quantity or the date of the transaction. |
hallucinated |
irrelevant |
related |
| … | . | . | . | . | . |
| . | . | . | 87% | 67% | 100% |
From the previous aggregates, we are able to see that reply relevance has a excessive rating; nonetheless, context relevance on this instance RAG system is 67%. Along with that, the system is demonstrating a degree of hallucination in some circumstances. Subsequently, we should always begin optimizing earlier within the chain to enhance context relevance. If we have a look at pattern questions the place context relevance is classed as irrelevant, we are able to see that textual content is nicely parsed; nonetheless, we are able to additionally see that chunks could begin or finish in the midst of a sentence or simply embrace the FAQ query with out the reply. Subsequently, we begin by optimizing the chunking methodology.
After we replace the chunking mechanism to stop beginning or ending a piece in the midst of a sentence and to incorporate the FAQ query and reply pairs, we redo the analysis over the identical 15 questions. The next desk exhibits a pattern of our outcomes.
| Query | Retrieved Doc | Reply | Faithfulness | Context Relevance | Reply Relevance |
|
What are the particular care directions for various material varieties like cashmere, silk, and wool? |
How do I look after XYZ material? Acetate: Whereas most objects manufactured from acetate are dry-clean solely, some could also be hand-washed in lukewarm water. Don’t twist the material. Iron whereas the material is damp. Press the within of the garment utilizing a low-temperature setting. Use a urgent fabric when ironing the surface. Acrylic knit: Most acrylic knit clothes may be machine-washed. Learn the label, and examine for the right drying possibility. Some knits retain their shapes greatest if reshaped and dried flat. Cashmere: Test the care label earlier than laundering cashmere. Handy-wash, use a light detergent or shampoo. Gently squeeze the water by way of the garment, then rinse till the water runs clear. Don’t wring or twist. Squeeze out extra water. To dry, lay flat on a towel, away from daylight or warmth. Cotton: Cotton holds up nicely to house laundering. Take away the garment from the dryer promptly to cut back wrinkling. Press utilizing spray starch for the crispness of a laundered shirt. Cotton mix: Dry cotton-blend clothes utilizing your dryer’s permanent-press or low-heat cycle, and take away instantly to cut back wrinkling. Contact up with a steam iron; starch for a professionally laundered look. Linen: Most linen clothes have to be dry-cleaned or hand-washed. Comply with the directions on the care label. To the touch up or press, use a steam iron on a linen setting for a crisp look. Nylon: Machine-wash nylon clothes in heat water. Use a low-temperature setting when tumble-drying, and embrace a dryer sheet to cut back static electrical energy. Use a heat iron to press, if vital. Polyester: Learn the label. Often polyester objects may be machine-washed (cool) and dried (low). Test the label to see if air-drying is advisable. Contact up with a cool – by no means scorching – iron, if vital. Rayon: Make sure that to learn the care label for rayon clothes. Launder in cool water and a gentle detergent. When machine-washing, use the light cycle and promptly take away clothes after washing. When hand-washing, don’t wring or twist the garment. To dry, roll the merchandise in a towel to squeeze out extra water. Lay flat to dry. Iron when nonetheless damp and with the garment inside out to stop the material from turning into shiny. Use a urgent fabric when ironing the suitable aspect of the garment. Urgent cloths may be bought, or use one thing so simple as a bit of white cotton material. Silk: Dry cleansing could also be required. Some silks are hand- or machine-washable. Don’t dry silk in a garments dryer. Clothes normally look greatest when professionally dry-cleaned. Spandex: Use heat water when hand- or machine-washing objects made with spandex. Line-dry or use a low temperature setting when machine-drying to protect the elasticity of the garment. Wool knit: Sometimes wool knits have to be dry-cleaned, however examine the label. If hand-washable, use cool water and a detergent for positive washables. Squeeze out extra water, then reshape and dry flat. Wool (lined): Lined clothes typically look greatest when professionally dry-cleaned as soon as a season. Between dry cleanings, take away floor soil with a brush or damp fabric. Refresh the merchandise by hanging it from a padded hanger in a steamy rest room; moisture will assist garment shed wrinkles. When touching up with an iron, use steam in an up-and-down movement (fairly than sliding the iron alongside the material). |
Cashmere: Test the care label earlier than laundering. Handy-wash, use a light detergent or shampoo. Gently squeeze the water by way of the garment, then rinse till the water runs clear. Don’t wring or twist. Squeeze out extra water and lay flat to dry, away from daylight or warmth. Silk: Dry cleansing could also be required. Some silks are hand- or machine-washable. Don’t dry silk in a garments dryer. For hand-washing, use a light detergent and funky water. Squeeze out extra water and lay flat to dry. Iron when nonetheless damp and with the garment inside out to stop the material from turning into shiny. Wool: The care directions for wool depend upon whether or not it’s a knit or not. For wool knits, they sometimes have to be dry-cleaned, however examine the label. If hand-washable, use cool water and a detergent for positive washables. Squeeze out extra water, then reshape and dry flat. For lined wool clothes, they often look greatest when professionally dry-cleaned as soon as a season. Between dry cleanings, take away floor soil with a brush or damp fabric and refresh in a steamy rest room. When touching up with an iron, use steam in an up-and-down movement. |
factual |
related |
related |
|
How can I determine if an electronic mail claiming to be from Zappos is legit or a phishing try? |
How do I determine whether or not an Electronic mail is or is just not from Zappos? Suspicious or fraudulent emails not from Zappos.com could include: A reference to a cost supply that Zappos.com doesn’t settle for, corresponding to PayPal. Zappos.com at present solely accepts bank cards, debit playing cards, and Zappos.com Present Playing cards for cost. What ought to I do if I consider I’ve obtained a phishing electronic mail or if I responded to what could also be a phishing electronic mail? For those who consider you obtained a phishing electronic mail or responded to what could also be a phishing electronic mail, Zappos recommends you replace your on-line passwords, together with the password to your Zappos.com Account, and report the e-mail to the Federal Commerce Fee (FTC). Go to the FTC web site right here to report the e-mail and discover extra info on how one can determine and forestall phishing assaults. Fee Data Do you settle for worldwide bank cards? At present Zappos.com can settle for worldwide bank cards however we are able to solely ship to an handle inside the USA and its territories. Please observe that the bank card should be issued and include a emblem from both Visa, Mastercard, Uncover, or American Specific. On the checkout web page, there will probably be a billing and delivery part. Please do the next: For the billing info Enter your road handle on Deal with Line 1. Enter your Metropolis, County or Province, and Postal Code on Deal with Line 2. Enter your Nation for the town. Enter AA for the state. Enter 11111 for the zip code. For the delivery info Please enter the right info within the acceptable discipline. Orders positioned with using an Worldwide Credit score Card could take as much as 72 hours to finalize previous to delivery. We apologize for any inconvenience this will likely trigger. |
To determine if an electronic mail claiming to be from Zappos is legit or a phishing try, examine for the next: 1. Zappos solely accepts sure cost strategies: bank cards, debit playing cards, and Zappos.com Present Playing cards. For those who consider you obtained a phishing electronic mail or responded to what could also be a phishing electronic mail, replace your passwords and report the e-mail to the Federal Commerce Fee (FTC). |
factual |
related |
related |
|
What’s Amazon Pay, and the way do I entry my transaction historical past with it on Zappos? |
How do I discover my Amazon Pay transactions? Go to pay.amazon.com and sign up as a “shopper” utilizing your Amazon username and password. One-time purchases are proven on the “Exercise” tab, and subscription agreements are on the “Service provider agreements” tab. You too can view your transactions on Amazon.com. If you’re on a desktop, your Amazon Pay transactions may be discovered below “Amazon Orders” throughout the Amazon Pay tab or in “Your Account” below “Transactions”. If you’re within the Amazon app, all transactions are listed collectively below “Your Orders” or in “Your Account”. |
Amazon Pay is a digital pockets that permits you to make funds on-line utilizing your Amazon account. Nonetheless, the context doesn’t present info on how one can entry your transaction historical past with Amazon Pay on Zappos. The directions given within the context are for accessing Amazon Pay transactions on Amazon’s personal platform. |
factual |
related |
related |
| … | . | . | . | . | . |
| . | . | . | 100% | 93% | 100% |
After we modified the chunking mechanism to stop mid-sentence chunking and to incorporate an FAQ and its corresponding reply in the identical chunk, we improved context relevance from 67% to 93%. We will additionally see that bettering context relevance resolved earlier hallucinations with out even altering the immediate template. We will iterate the optimization course of with additional investigation into the questions which can be having irrelevant retrievals by adjusting the indexing or the retrieval mechanism by selecting a better variety of retrieved chunks or by utilizing hybrid search to mix lexical search with semantic search.
Pattern references
To additional discover and experiment completely different RAG analysis methods, you’ll be able to delve deeper into the pattern notebooks accessible within the Information Bases part of the Amazon Bedrock Samples GitHub repo.
Conclusion
On this put up, we described the significance of evaluating and monitoring RAG-based generative AI purposes. We showcased the metrics and frameworks for RAG system analysis and observability, then we went over how you should utilize FMs in Amazon Bedrock to compute RAG reliability metrics. It’s essential to decide on the metrics that matter most to your group and that influence the side or configuration you wish to optimize.
If RAG is just not enough on your use case, you’ll be able to go for fine-tuning or continued pre-training in Amazon Bedrock or Amazon SageMaker to construct customized fashions which can be particular to your area, group, and use case. Most significantly, conserving a human within the loop is crucial to align AI techniques, in addition to their analysis mechanisms, with their supposed makes use of and targets.
Concerning the Authors
 Oussama Maxime Kandakji is a Senior Options Architect at AWS specializing in information science and engineering. He works with enterprise prospects on fixing enterprise challenges and constructing modern functionalities on prime of AWS. He enjoys contributing to open supply and dealing with information.
Oussama Maxime Kandakji is a Senior Options Architect at AWS specializing in information science and engineering. He works with enterprise prospects on fixing enterprise challenges and constructing modern functionalities on prime of AWS. He enjoys contributing to open supply and dealing with information.
 Ioan Catana is a Senior Synthetic Intelligence and Machine Studying Specialist Options Architect at AWS. He helps prospects develop and scale their ML options and generative AI purposes within the AWS Cloud. Ioan has over 20 years of expertise, largely in software program structure design and cloud engineering.
Ioan Catana is a Senior Synthetic Intelligence and Machine Studying Specialist Options Architect at AWS. He helps prospects develop and scale their ML options and generative AI purposes within the AWS Cloud. Ioan has over 20 years of expertise, largely in software program structure design and cloud engineering.


/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



