


Introduction
Probably the most common purposes of giant language fashions (LLMs) is to reply questions on customized datasets. LLMs like ChatGPT and Bard are glorious communicators. They’ll reply virtually something that they’ve been educated on. That is additionally one of many greatest bottlenecks for LLMs. They’ll solely reply the questions they’ve seen throughout mannequin coaching. The language fashions have a cap on the data in regards to the world. For instance, Chatgpt has been educated on knowledge obtainable till 2021. Additionally, there isn’t a means GPT can study your personal recordsdata. So, how can we make the mannequin conscious of the data it doesn’t possess but? The reply is a Retrieval Augmented Technology Pipeline. On this article, we are going to study in regards to the RAG (Retrieval Augmented Technology) pipeline and construct one utilizing the LLama Index.
Studying Goals
- Discover what Retrieval Augmented Technology (RAG) is and after we ought to use it.
- Perceive totally different parts of RAG briefly.
- Be taught in regards to the Llama Index and learn how to use it to construct a easy RAG pipeline for PDFs.
- Perceive what embeddings and vector databases are and learn how to use Llama Index’s inbuilt modules to construct data bases from PDFs.
- Uncover the real-world use instances of RAG-based purposes.
This text was printed as part of the Information Science Blogathon.
What’s RAG?
LLMs are probably the most environment friendly and highly effective NLP fashions to this date. We’ve got seen the potential of LLMs in translation, essay writing, and normal question-answering. However with regards to domain-specific question-answering, they endure from hallucinations. Moreover, in a domain-specific QA app, just a few paperwork comprise related context per question. So, we’d like a unified system that streamlines doc extraction to reply technology and all of the processes between them. This course of is named Retrieval Augmented Technology.
Be taught Extra: Retrieval-Augmented Technology (RAG) in AI
So, let’s perceive why RAG is only for constructing real-world domain-specific QA apps.
Why Ought to One Use RAG?
There are 3 ways an LLM can study new knowledge.
- Coaching: A big mesh of neural networks is educated over trillions of tokens with billions of parameters to create Massive Language Fashions. The parameters of a deep studying mannequin are the coefficients or weights that maintain all the knowledge concerning the actual mannequin. To coach a mannequin like GPT-4 prices tons of of hundreds of thousands of {dollars}. This manner is past anybody’s capability. We can’t re-train such a humongous mannequin on new knowledge. This isn’t possible.
- Fantastic-tuning: An alternative choice is to fine-tune a mannequin on present knowledge. Fantastic-tuning entails utilizing a pre-trained mannequin as a place to begin throughout coaching. We use the data of the pre-trained mannequin to coach a brand new mannequin on totally different knowledge units. Albeit it is extremely potent, it’s costly when it comes to money and time. Except there’s a particular requirement, fine-tuning doesn’t make sense.
- Prompting: Prompting is the strategy the place we match new info throughout the context window of an LLM and make it reply the queries from the knowledge given within the immediate. It is probably not as efficient as data realized throughout coaching or fine-tuning, however it’s enough for a lot of real-life use instances, corresponding to doc Q&A.
Prompting for solutions from textual content paperwork is efficient, however these paperwork are sometimes a lot bigger than the context home windows of Massive Language Fashions (LLMs), posing a problem. Retrieval Augmented Technology (RAG) pipelines handle this by processing, storing, and retrieving related doc sections, permitting LLMs to reply queries effectively. So, let’s talk about the essential parts of an RAG pipeline.
What Are The RAG Elements?
In a typical RAG course of, we have now just a few parts.
- Textual content Splitter: Splits paperwork to accommodate context home windows of LLMs.
- Embedding Mannequin: The deep studying mannequin used to get embeddings of paperwork.
- Vector Shops: The databases the place doc embeddings are saved and queried together with their metadata.
- LLM: The Massive Language Mannequin accountable for producing solutions from queries.
- Utility Capabilities: This entails further utility features corresponding to Webretriver and doc parsers that assist in retrieving and pre-processing recordsdata.
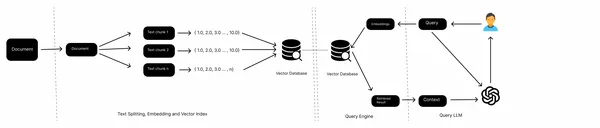
The above image is of a typical RAG course of. We’ve got paperwork (PDFs, Net Pages, Docs), a device to separate giant textual content into smaller chunks, embedding fashions to get vector illustration of textual content chunks, Vector shops as data bases, and an LLM to get solutions from textual content chunks.
What’s the Llama Index?
The Llama Index (GPTIndex) is a framework written in Python to construct LLM purposes. It’s a easy, versatile knowledge framework connecting customized knowledge sources to giant language fashions. It offers applicable instruments to help knowledge ingestion from numerous sources, vector databases for knowledge indexing, and question interfaces for querying giant paperwork. In brief, Llama Index is a one-stop store for constructing retrieval augmented technology purposes. It permits simple integration with different purposes like Langchain, Flask, Docker, and so on. Take a look at the official GitHub repository for extra: https://github.com/run-llama/llama_index.
Additionally Learn: Tips on how to use LlamaIndex?
Now that we find out about RAG and Llama Index. So, let’s construct our RAG pipeline to course of PDF paperwork and talk about particular person ideas as we proceed.
Set-up Dev Setting
The primary rule of constructing any Python venture is to create a Digital atmosphere. As soon as you might be finished, set up the next libraries.
llama-index
openai
tiktokenNow, import the next features.
import os
from llama_index import ServiceContext, LLMPredictor, OpenAIEmbedding, PromptHelper
from llama_index.llms import OpenAI
from llama_index.text_splitter import TokenTextSplitter
from llama_index.node_parser import SimpleNodeParser
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index import set_global_service_contextNow, set the Open AI API key.
import os
os.environ['OPENAI_API_KEY'] = "YOUR API KEY"Load Paperwork
As we all know, LLMs don’t possess up to date data of the world nor data about your inner paperwork. To assist LLMs, we have to feed them with related info from data sources. These data sources may be structured knowledge corresponding to CSV, Spreadsheets, or SQL tables, unstructured knowledge corresponding to texts, Phrase Docs, Google Docs, PDFs, or PPTs, and semi-structured knowledge corresponding to Notion, Slack, Salesforce, and so on.
On this article, we are going to use PDFs. Llama Index features a class SimpleDirectoryReader, which may learn saved paperwork from a specified listing. It robotically selects a parser based mostly on file extension.
paperwork = SimpleDirectoryReader(input_dir="knowledge").load_data()You’ll be able to have your customized implementation of a PDF reader utilizing packages like PyMuPDF or PyPDF2.
Creating Textual content Chunks
Usually, the info extracted from data sources are prolonged, exceeding the context window of LLMs. If we ship texts longer than the context window, the Chatgpt API will shrink the info, leaving out essential info. One strategy to resolve that is textual content chunking. In textual content chunking, longer texts are divided into smaller chunks based mostly on separators.
Textual content chunking has different advantages in addition to making it attainable to suit texts into a big language mannequin’s context window.
- Smaller textual content chunks end in higher embedding accuracy, subsequently enhancing retrieval accuracy.
- Exact context: Narrowing down info will assist in getting higher info.
The Llama index has built-in instruments for chunking texts. So, that is how we will do it.
text_splitter = TokenTextSplitter(
separator=" ",
chunk_size=1024,
chunk_overlap=20,
backup_separators=["n"],
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)
node_parser = SimpleNodeParser.from_defaults(
text_splitter = TokenTextSplitter )
)SimpleNodeParser creates nodes out of textual content chunks, and the textual content chunks are created utilizing Llama Index’s TokenTextSplitter. We are able to use a SentenceSplitter as effectively.
text_splitter = SentenceSplitter(
separator=" ",
chunk_size=1024,
chunk_overlap=20,
paragraph_separator="nnn",
secondary_chunking_regex="[^,.;。]+[,.;。]?",
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)Constructing Information Bases
The texts extracted from the data sources have to be saved someplace. However in RAG-based purposes, we’d like the embeddings of the info. These embeddings are floating level numbers representing knowledge in a high-dimensional vector area. To retailer and function on them, we’d like vector databases. Vector Databases are purpose-built knowledge shops for storing and querying vectors.
On this part, we are going to perceive embeddings and vector databases and implement them utilizing the Llama Index for our RAG pipeline.
Embeddings
We are able to perceive embeddings from a easy grocery store instance. In a grocery store, you’ll all the time discover apples and oranges in the identical nook. To discover a cleaning soap, you’ll have to transfer farther from the fruits part in the direction of the every day attire part, however you’ll simply discover perfumes in the identical part inside just a few step’s distance.
That is how embeddings work. Two semantically associated texts will probably be in proximity within the vector area, whereas dissimilar texts are distant. Embeddings have a unprecedented capacity to map analogies between totally different knowledge factors. Right here is an easy illustration of the identical.
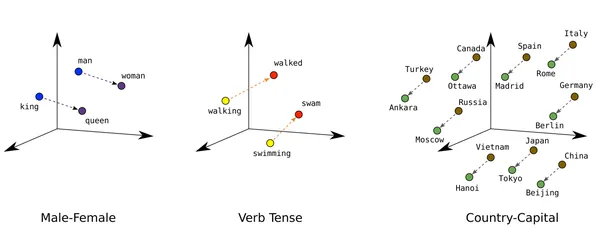
So, why do we’d like embeddings?
Embeddings generated from succesful deep-learning fashions can effectively seize the semantic which means of textual content chunks. When a consumer sends a textual content question, we convert it to embeddings utilizing the identical mannequin, examine the distances of the textual content embeddings saved within the vector database, and retrieve the closest “n” textual content chunks. These chunks are probably the most semantically related chunks to the queried textual content.
For embedding fashions, we’d like not do something particular. Llama Index has a customized implementation of common embedding fashions, corresponding to OpeanAI’s Ada, Cohere, Sentence transformers, and so on.
To customise the embedding mannequin, we have to use ServiceContext and PromptHelper.
llm = OpenAI(mannequin="gpt-3.5-turbo", temperature=0, max_tokens=256)
embed_model = OpenAIEmbedding()
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None
)
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser,
prompt_helper=prompt_helper
)Vector Database
Vector Databases are purpose-built for storing and organizing embeddings and related metadata to supply most querying effectivity. They supply semantic retrieval of information, which helps increase LLMs with new info. That is the way it works.
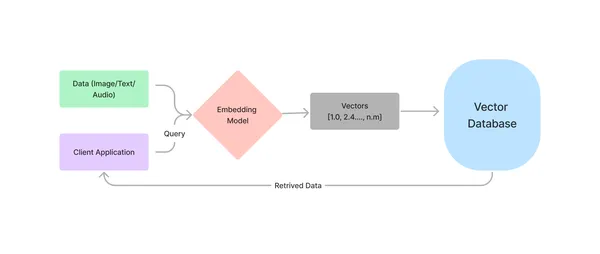
Now, you should be asking, Why can’t we use the normal databases? Technically, we will use a database like SQLite or MySQL to retailer vectors and linearly examine the embeddings of the question textual content with all others. However the issue is, you might need guessed, the linear search with O(n) time complexity. Whereas a GPU-augmented machine can deal with just a few thousand knowledge factors completely high-quality, it’ll fail miserably when processing tons of of hundreds of thousands of embeddings in any real-world utility.
So, how can we resolve this? The reply is indexing embeddings utilizing totally different ANN algorithms corresponding to HNSW. The HNSW is a graph-based algorithm that may effectively deal with billions of embeddings. The common question complexity of HNSW is O(log n).
Aside from HNSW, there are just a few different indexing methods, corresponding to Product quantization, Scalar quantization, and Inverted file indexing. Nonetheless, HNSW is used because the default indexing algorithm for many of the vector databases.
We realized about embeddings and vector shops. Now, we are going to implement them in our code. We are going to use the Llama Index’s default vector retailer. It’s an in-memory vector database. You could go along with different vector shops corresponding to Chroma, Weaviate, Qdrant, Milvus, and so on.
index = VectorStoreIndex.from_documents(
paperwork,
service_context = service_context
)An index is created utilizing the paperwork from our listing and the defaults from the service context we outlined earlier.
Question Index
The ultimate step is to question from the index and get a response from the LLM. Llama Index offers a question engine for querying and a chat engine for a chat-like dialog. The distinction between the 2 is the chat engine preserves the historical past of the dialog, and the question engine doesn’t.
query_engine = index.as_query_engine(service_context=service_context)
response = query_engine.question("What's HNSW?")
print(response)
GitHub repository for photos and Code: sunilkumardash9/llama_rag
Full code:
from llama_index import ServiceContext, LLMPredictor, OpenAIEmbedding, PromptHelper
from llama_index.llms import OpenAI
from llama_index.text_splitter import TokenTextSplitter
from llama_index.node_parser import SimpleNodeParser
import tiktoken
llm = OpenAI(mannequin="gpt-3.5-turbo", temperature=0, max_tokens=256)
embed_model = OpenAIEmbedding()
text_splitter = TokenTextSplitter(
separator=" ",
chunk_size=1024,
chunk_overlap=20,
backup_separators=["n"],
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)
node_parser = SimpleNodeParser.from_defaults(
text_splitter=text_splitter
)
prompt_helper = PromptHelper(
context_window=4096,
num_output=256,
chunk_overlap_ratio=0.1,
chunk_size_limit=None
)
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser,
prompt_helper=prompt_helper
)
paperwork = SimpleDirectoryReader(input_dir="knowledge").load_data()
index = VectorStoreIndex.from_documents(
paperwork,
service_context = service_context
)
index.storage_context.persist()
query_engine = index.as_query_engine(service_context=service_context)
response = query_engine.question("What's HNSW?")
print(response)Actual-Life Use Instances
A RAG-based utility may be useful in lots of real-life use instances.
- Tutorial Analysis: Researchers usually take care of quite a few analysis papers and articles in PDF format. A RAG pipeline might assist them extract related info, create bibliographies, and arrange their references effectively.
- Regulation Corporations: Regulation companies usually take care of quite a few authorized paperwork. A RAG-enabled Q&A chatbot can streamline the doc retrieval course of. This can save numerous time from losing.
- Instructional Establishments: Academics and educators can extract content material from academic assets to create personalized studying supplies or to arrange course content material. College students can take away relevant info from giant PDFs inside a fraction of the time.
- Administration: Authorities and Personal administrative departments usually take care of giant quantities of paperwork, purposes, and experiences. Using a RAG chatbot can streamline mundane doc retrieval processes.
- Buyer Care: A RAG-enabled Q&A chatbot with an present data base can be utilized to reply buyer queries.
Conclusion
As we have now seen, RAG streamlines retrieval technology. It helps querying the correct context out of heaps of paperwork inside a fraction of the time. Prompting with the proper context of the question is what prompts the LLMs to generate solutions. The extra contexts basically floor the LLM to maintain the solutions to the context solely. This prohibits the LLM from hallucinating whereas conserving its superior phrasing and writing capacity.
Key Takeaways
- The perfect strategy to make LLMs study private paperwork and scale back hallucinations is to enhance the LLMs with retrieved paperwork from data bases.
- RAG stands for Retrieval Augmented Technology. RAG is used to enhance LLM with info from data bases from customized paperwork.
- Embeddings are numerical representations of textual content knowledge in high-dimensional vector area. Embeddings seize the semantic which means of texts.
- Customers make use of Vector Databases as data bases, using numerous indexing algorithms to arrange high-dimensional vectors, enabling quick and strong querying capacity.
- Llama Index offers in-built instruments and strategies to construct production-grade RAG-based purposes.
Steadily Requested Questions
Ans. Lama Index is a Python framework that gives the important instruments to enhance your LLM purposes with exterior knowledge.
Ans. A data base is a database that shops info, together with embeddings and their metadata, from totally different sources.
Ans. Llama Index is an open-source framework for constructing LLM-based purposes. It offers knowledge ingestion instruments, indexing instruments, and a question interface to construct production-grade RAG purposes.
Ans. A RAG pipeline retrieves paperwork from exterior knowledge shops, processes them to retailer them in a data base, and offers instruments to question them.
Ans. Llama Index explicitly designs search and retrieval purposes, whereas Langchain gives flexibility for creating customized AI brokers.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Writer’s discretion.
/cdn.vox-cdn.com/uploads/chorus_asset/file/25038694/HT051_NEST_THERMOSTAT_CVIRGINIA.jpg)




/cdn.vox-cdn.com/uploads/chorus_asset/file/25547838/YAKZA_3840_2160_A_Elogo.jpg)
