


Reinforcement studying (RL) brokers epitomize synthetic intelligence by embodying adaptive prowess, navigating intricate information landscapes by way of iterative trial and error, and dynamically assimilating environmental insights to autonomously evolve and optimize their decision-making capabilities. Growing generalist RL brokers that may carry out various duties in advanced environments is a difficult process that requires quite a few reward features. Nonetheless, researchers are investigating methods to beat this impediment.
Researchers from Google DeepMind discover utilizing off-the-shelf vision-language fashions (VLMs), particularly the CLIP household, to derive rewards for coaching RL brokers able to various language targets. Demonstrating in two visible domains, the analysis reveals a scaling development the place bigger VLMs result in extra correct rewards, enhancing RL agent capabilities. It additionally discusses changing the reward perform right into a binary type by way of chance thresholding. Experiments deal with VLM reward maximization and scaling affect, suggesting improved VLM high quality might allow coaching generalist RL brokers in wealthy visible environments with out task-specific finetuning.
The analysis addresses the problem of making versatile RL brokers able to various targets in advanced environments. Conventional RL depends on specific reward features, posing challenges in defining various targets. The research explores leveraging VLMs, notably CLIP, as an answer. VLMs, like CLIP, skilled on in depth image-text information, provide promising efficiency in varied visible duties and might function efficient reward perform turbines. The analysis investigates utilizing off-the-shelf VLMs for correct reward derivation, specializing in language targets in visible contexts, aiming to streamline RL agent coaching.
The research makes use of contrastive VLMs like CLIP to generate text-based reward fashions for reinforcement studying brokers. It establishes a reward mannequin comprising picture and textual content encoders, producing binary rewards indicating objective achievement. Working in {a partially} noticed Markov Resolution Course of, the premium is computed by way of a VLM primarily based on scanned pictures and language-based targets. The research employs pre-trained CLIP fashions in experiments throughout Playhouse and AndroidEnv, exploring encoder architectures reminiscent of Normalizer-Free Networks, Swin, and BERT for language encoding in duties like Discover, Raise, and Choose and Place.
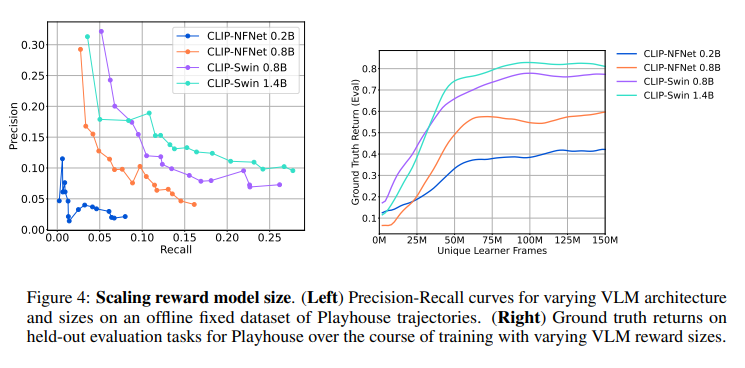
The strategy highlights off-the-shelf VLMs, particularly CLIP, as reward sources for RL brokers. It demonstrates deriving rewards for various language targets from CLIP, coaching RL brokers throughout Playhouse and AndroidEnv domains. Bigger VLMs yield extra correct rewards, enhancing agent capabilities. Scaling VLM measurement typically improves efficiency. It additionally explores immediate engineering’s affect on VLM reward efficiency, though the sources don’t present particular outcomes.
To conclude, the analysis could be summarized within the following factors:
- The research proposes a technique to acquire sparse binary rewards for reinforcement studying brokers utilizing pre-trained CLIP embeddings for visible achievement of language targets.
- Off-the-shelf VLMs, reminiscent of CLIP, could be rewarded sources with out environment-specific finetuning.
- The strategy is demonstrated in Playhouse and AndroidEnv domains.
- Bigger VLMs result in extra correct rewards and extra succesful RL brokers.
- Maximizing VLM rewards enhances floor fact rewards, and scaling VLM measurement positively impacts efficiency.
- The research examines the position of immediate engineering in VLM reward efficiency.
- The potential of VLMs for coaching versatile RL brokers in various language targets inside visible environments is highlighted.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to hitch our 34k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and E mail E-newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Should you like our work, you’ll love our e-newsletter..
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is enthusiastic about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.



/cdn.vox-cdn.com/uploads/chorus_asset/file/25547597/Screen_Shot_2024_07_26_at_3.55.30_PM.png)

