


Massive language fashions (LLMs) with their broad information, can generate human-like textual content on nearly any subject. Nonetheless, their coaching on large datasets additionally limits their usefulness for specialised duties. With out continued studying, these fashions stay oblivious to new information and traits that emerge after their preliminary coaching. Moreover, the price to coach new LLMs can show prohibitive for a lot of enterprise settings. Nonetheless, it’s potential to cross-reference a mannequin reply with the unique specialised content material, thereby avoiding the necessity to practice a brand new LLM mannequin, utilizing Retrieval-Augmented Era (RAG).
RAG empowers LLMs by giving them the power to retrieve and incorporate exterior information. As a substitute of relying solely on their pre-trained information, RAG permits fashions to drag information from paperwork, databases, and extra. The mannequin then skillfully integrates this exterior data into its generated textual content. By sourcing context-relevant information, the mannequin can present knowledgeable, up-to-date responses tailor-made to your use case. The information augmentation additionally reduces the probability of hallucinations and inaccurate or nonsensical textual content. With RAG, basis fashions change into adaptable consultants that evolve as your information base grows.
In the present day, we’re excited to unveil three generative AI demos, licensed below MIT-0 license:
- Amazon Kendra with foundational LLM – Makes use of the deep search capabilities of Amazon Kendra mixed with the expansive information of LLMs. This integration gives exact and context-aware solutions to advanced queries by drawing from a various vary of sources.
- Embeddings mannequin with foundational LLM – Merges the ability of embeddings—a way to seize semantic meanings of phrases and phrases—with the huge information base of LLMs. This synergy permits extra correct subject modeling, content material advice, and semantic search capabilities.
- Basis Fashions Pharma Advert Generator – A specialised software tailor-made for the pharmaceutical trade. Harnessing the generative capabilities of foundational fashions, this device creates convincing and compliant pharmaceutical ads, making certain content material adheres to trade requirements and rules.
These demos might be seamlessly deployed in your AWS account, providing foundational insights and steering on using AWS companies to create a state-of-the-art LLM generative AI query and reply bot and content material era.
On this submit, we discover how RAG mixed with Amazon Kendra or customized embeddings can overcome these challenges and supply refined responses to pure language queries.
Answer overview
By adopting this answer, you’ll be able to achieve the next advantages:
- Improved data entry – RAG permits fashions to drag in data from huge exterior sources, which might be particularly helpful when the pre-trained mannequin’s information is outdated or incomplete.
- Scalability – As a substitute of coaching a mannequin on all accessible information, RAG permits fashions to retrieve related data on the fly. Because of this as new information turns into accessible, it may be added to the retrieval database while not having to retrain the whole mannequin.
- Reminiscence effectivity – LLMs require important reminiscence to retailer parameters. With RAG, the mannequin might be smaller as a result of it doesn’t must memorize all particulars; it may retrieve them when wanted.
- Dynamic information replace – In contrast to typical fashions with a set information endpoint, RAG’s exterior database can endure common updates, granting the mannequin entry to up-to-date data. The retrieval perform might be fine-tuned for distinct duties. For instance, a medical diagnostic job can supply information from medical journals, making certain the mannequin garners skilled and pertinent insights.
- Bias mitigation – The flexibility to attract from a well-curated database gives the potential to attenuate biases by making certain balanced and neutral exterior sources.
Earlier than diving into the combination of Amazon Kendra with foundational LLMs, it’s essential to equip your self with the mandatory instruments and system necessities. Having the precise setup in place is step one in direction of a seamless deployment of the demos.
Stipulations
It’s essential to have the next conditions:
Though it’s potential to arrange and deploy the infrastructure detailed on this tutorial out of your native pc, AWS Cloud9 gives a handy various. Pre-equipped with instruments like AWS CLI, AWS CDK, and Docker, AWS Cloud9 can perform as your deployment workstation. To make use of this service, merely arrange the surroundings by way of the AWS Cloud9 console.
With the conditions out of the way in which, let’s dive into the options and capabilities of Amazon Kendra with foundational LLMs.
Amazon Kendra with foundational LLM
Amazon Kendra is a sophisticated enterprise search service enhanced by machine studying (ML) that gives out-of-the-box semantic search capabilities. Using pure language processing (NLP), Amazon Kendra comprehends each the content material of paperwork and the underlying intent of consumer queries, positioning it as a content material retrieval device for RAG based mostly options. By utilizing the high-accuracy search content material from Kendra as a RAG payload, you will get higher LLM responses. The usage of Amazon Kendra on this answer additionally permits customized search by filtering responses in keeping with the end-user content material entry permissions.
The next diagram reveals the structure of a generative AI software utilizing the RAG strategy.
Paperwork are processed and listed by Amazon Kendra by way of the Amazon Easy Storage Service (Amazon S3) connector. Buyer requests and contextual information from Amazon Kendra are directed to an Amazon Bedrock basis mannequin. The demo enables you to select between Amazon’s Titan, AI21’s Jurassic, and Anthropic’s Claude fashions supported by Amazon Bedrock. The dialog historical past is saved in Amazon DynamoDB, providing added context for the LLM to generate responses.
We now have supplied this demo within the GitHub repo. Consult with the deployment directions inside the readme file for deploying it into your AWS account.
The next steps define the method when a consumer interacts with the generative AI app:
- The consumer logs in to the online app authenticated by Amazon Cognito.
- The consumer uploads a number of paperwork into Amazon S3.
- The consumer runs an Amazon Kendra sync job to ingest S3 paperwork into the Amazon Kendra index.
- The consumer’s query is routed by way of a safe WebSocket API hosted on Amazon API Gateway backed by a AWS Lambda perform.
- The Lambda perform, empowered by the LangChain framework—a flexible device designed for creating functions pushed by AI language fashions—connects to the Amazon Bedrock endpoint to rephrase the consumer’s query based mostly on chat historical past. After rephrasing, the query is forwarded to Amazon Kendra utilizing the Retrieve API. In response, the Amazon Kendra index shows search outcomes, offering excerpts from pertinent paperwork sourced from the enterprise’s ingested information.
- The consumer’s query together with the information retrieved from the index are despatched as a context within the LLM immediate. The response from the LLM is saved as chat historical past inside DynamoDB.
- Lastly, the response from the LLM is shipped again to the consumer.
Doc indexing workflow
The next is the process for processing and indexing paperwork:
- Customers submit paperwork by way of the consumer interface (UI).
- Paperwork are transferred to an S3 bucket using the AWS Amplify API.
- Amazon Kendra indexes new paperwork within the S3 bucket by way of the Amazon Kendra S3 connector.
Advantages
The next checklist highlights some great benefits of this answer:
- Enterprise-level retrieval – Amazon Kendra is designed for enterprise search, making it appropriate for organizations with huge quantities of structured and unstructured information.
- Semantic understanding – The ML capabilities of Amazon Kendra be certain that retrieval is predicated on deep semantic understanding and never simply key phrase matches.
- Scalability – Amazon Kendra can deal with large-scale information sources and gives fast and related search outcomes.
- Flexibility – The foundational mannequin can generate solutions based mostly on a variety of contexts, making certain the system stays versatile.
- Integration capabilities – Amazon Kendra might be built-in with varied AWS companies and information sources, making it adaptable for various organizational wants.
Embeddings mannequin with foundational LLM
An embedding is a numerical vector that represents the core essence of various information varieties, together with textual content, photos, audio, and paperwork. This illustration not solely captures the information’s intrinsic that means, but additionally adapts it for a variety of sensible functions. Embedding fashions, a department of ML, remodel advanced information, comparable to phrases or phrases, into steady vector areas. These vectors inherently grasp the semantic connections between information, enabling deeper and extra insightful comparisons.
RAG seamlessly combines the strengths of foundational fashions, like transformers, with the precision of embeddings to sift by way of huge databases for pertinent data. Upon receiving a question, the system makes use of embeddings to determine and extract related sections from an in depth physique of information. The foundational mannequin then formulates a contextually exact response based mostly on this extracted data. This good synergy between information retrieval and response era permits the system to supply thorough solutions, drawing from the huge information saved in expansive databases.
Within the architectural structure, based mostly on their UI choice, customers are guided to both the Amazon Bedrock or Amazon SageMaker JumpStart basis fashions. Paperwork endure processing, and vector embeddings are produced by the embeddings mannequin. These embeddings are then listed utilizing FAISS to allow environment friendly semantic search. Dialog histories are preserved in DynamoDB, enriching the context for the LLM to craft responses.
The next diagram illustrates the answer structure and workflow.

We now have supplied this demo within the GitHub repo. Consult with the deployment directions inside the readme file for deploying it into your AWS account.
Embeddings mannequin
The obligations of the embeddings mannequin are as follows:
- This mannequin is accountable for changing textual content (like paperwork or passages) into dense vector representations, generally referred to as embeddings.
- These embeddings seize the semantic that means of the textual content, permitting for environment friendly and semantically significant comparisons between totally different items of textual content.
- The embeddings mannequin might be educated on the identical huge corpus because the foundational mannequin or might be specialised for particular domains.
Q&A workflow
The next steps describe the workflow of the query answering over paperwork:
- The consumer logs in to the online app authenticated by Amazon Cognito.
- The consumer uploads a number of paperwork to Amazon S3.
- Upon doc switch, an S3 occasion notification triggers a Lambda perform, which then calls the SageMaker embedding mannequin endpoint to generate embeddings for the brand new doc. The embeddings mannequin converts the query right into a dense vector illustration (embedding). The ensuing vector file is securely saved inside the S3 bucket.
- The FAISS retriever compares this query embedding with the embeddings of all paperwork or passages within the database to seek out essentially the most related passages.
- The passages, together with the consumer’s query, are supplied as context to the foundational mannequin. The Lambda perform makes use of the LangChain library and connects to the Amazon Bedrock or SageMaker JumpStart endpoint with a context-stuffed question.
- The response from the LLM is saved in DynamoDB together with the consumer’s question, the timestamp, a novel identifier, and different arbitrary identifiers for the merchandise comparable to query class. Storing the query and reply as discrete gadgets permits the Lambda perform to simply recreate a consumer’s dialog historical past based mostly on the time when questions have been requested.
- Lastly, the response is shipped again to the consumer by way of a HTTPs request by way of the API Gateway WebSocket API integration response.
Advantages
The next checklist describe the advantages of this answer:
- Semantic understanding – The embeddings mannequin ensures that the retriever selects passages based mostly on deep semantic understanding, not simply key phrase matches.
- Scalability – Embeddings permit for environment friendly similarity comparisons, making it possible to go looking by way of huge databases of paperwork rapidly.
- Flexibility – The foundational mannequin can generate solutions based mostly on a variety of contexts, making certain the system stays versatile.
- Area adaptability – The embeddings mannequin might be educated or fine-tuned for particular domains, permitting the system to be tailored for varied functions.
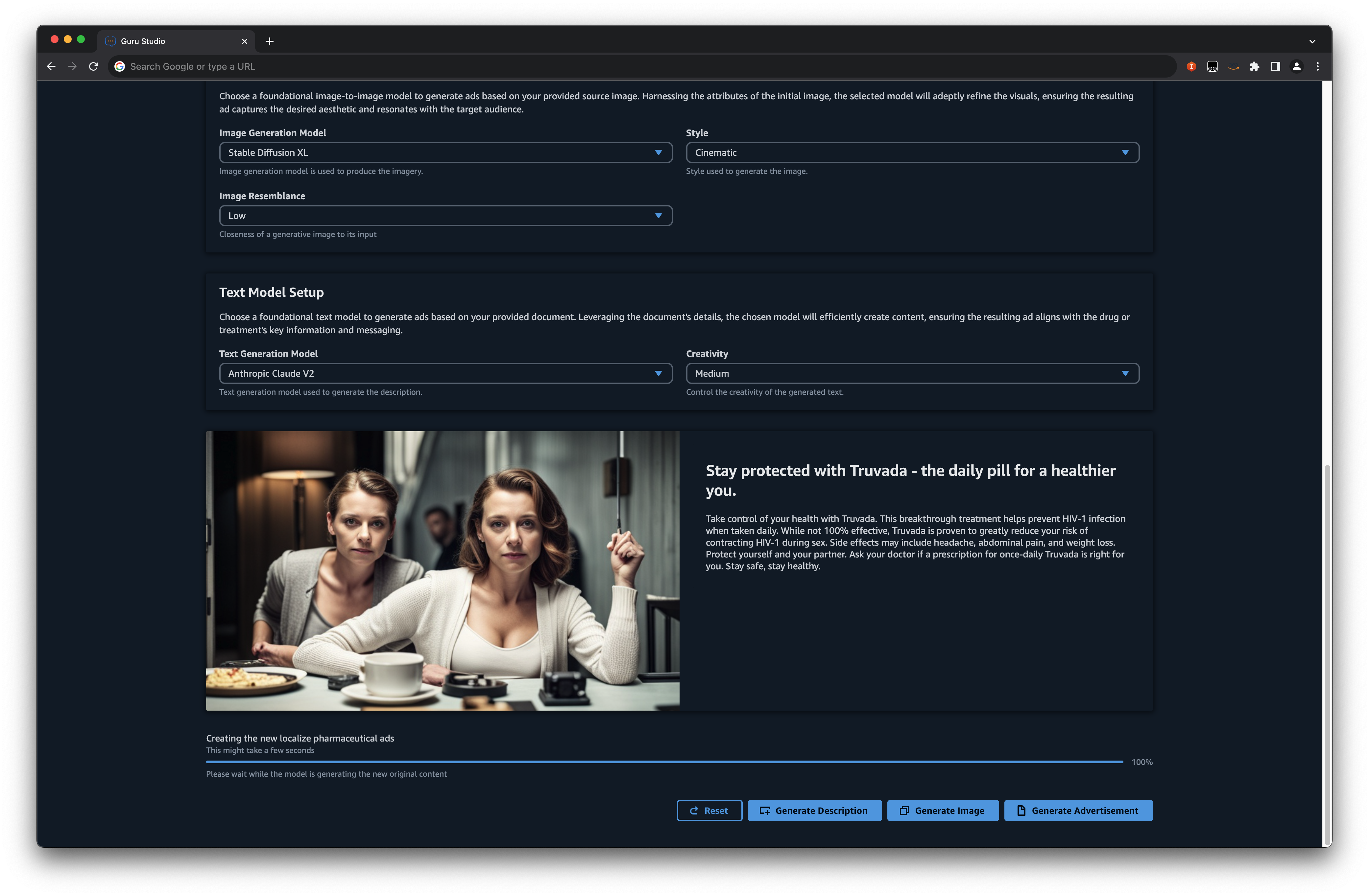
Basis Fashions Pharma Advert Generator
In immediately’s fast-paced pharmaceutical trade, environment friendly and localized promoting is extra essential than ever. That is the place an progressive answer comes into play, utilizing the ability of generative AI to craft localized pharma advertisements from supply photos and PDFs. Past merely rushing up the advert era course of, this strategy streamlines the Medical Authorized Evaluation (MLR) course of. MLR is a rigorous evaluation mechanism by which medical, authorized, and regulatory groups meticulously consider promotional supplies to ensure their accuracy, scientific backing, and regulatory compliance. Conventional content material creation strategies might be cumbersome, usually requiring guide changes and in depth critiques to make sure alignment with regional compliance and relevance. Nonetheless, with the arrival of generative AI, we will now automate the crafting of advertisements that actually resonate with native audiences, all whereas upholding stringent requirements and tips.
The next diagram illustrates the answer structure.

Within the architectural structure, based mostly on their chosen mannequin and advert preferences, customers are seamlessly guided to the Amazon Bedrock basis fashions. This streamlined strategy ensures that new advertisements are generated exactly in keeping with the specified configuration. As a part of the method, paperwork are effectively dealt with by Amazon Textract, with the resultant textual content securely saved in DynamoDB. A standout characteristic is the modular design for picture and textual content era, granting you the pliability to independently regenerate any part as required.
We now have supplied this demo within the GitHub repo. Consult with the deployment directions inside the readme file for deploying it into your AWS account.
Content material era workflow
The next steps define the method for content material era:
- The consumer chooses their doc, supply picture, advert placement, language, and picture type.
- Safe entry to the online software is ensured by way of Amazon Cognito authentication.
- The online software’s entrance finish is hosted by way of Amplify.
- A WebSocket API, managed by API Gateway, facilitates consumer requests. These requests are authenticated by way of AWS Id and Entry Administration (IAM).
- Integration with Amazon Bedrock contains the next steps:
- A Lambda perform employs the LangChain library to connect with the Amazon Bedrock endpoint utilizing a context-rich question.
- The text-to-text foundational mannequin crafts a contextually acceptable advert based mostly on the given context and settings.
- The text-to-image foundational mannequin creates a tailor-made picture, influenced by the supply picture, chosen type, and site.
- The consumer receives the response by way of an HTTPS request by way of the built-in API Gateway WebSocket API.
Doc and picture processing workflow
The next is the process for processing paperwork and pictures:
- The consumer uploads belongings by way of the required UI.
- The Amplify API transfers the paperwork to an S3 bucket.
- After the asset is transferred to Amazon S3, one of many following actions takes place:
- If it’s a doc, a Lambda perform makes use of Amazon Textract to course of and extract textual content for advert era.
- If it’s a picture, the Lambda perform converts it to base64 format, appropriate for the Steady Diffusion mannequin to create a brand new picture from the supply.
- The extracted textual content or base64 picture string is securely saved in DynamoDB.
Advantages
The next checklist describes the advantages of this answer:
- Effectivity – The usage of generative AI considerably accelerates the advert era course of, eliminating the necessity for guide changes.
- Compliance adherence – The answer ensures that generated advertisements adhere to particular steering and rules, such because the FDA’s tips for advertising and marketing.
- Value-effective – By automating the creation of tailor-made advertisements, corporations can considerably cut back prices related to advert manufacturing and revisions.
- Streamlined MLR course of – The answer simplifies the MLR course of, decreasing friction factors and making certain smoother critiques.
- Localized resonance – Generative AI produces advertisements that resonate with native audiences, making certain relevance and influence in numerous areas.
- Standardization – The answer maintains vital requirements and tips, making certain consistency throughout all generated advertisements.
- Scalability – The AI-driven strategy can deal with huge databases of supply photos and PDFs, making it possible for large-scale advert era.
- Diminished guide intervention – The automation reduces the necessity for human intervention, minimizing errors and making certain consistency.
You possibly can deploy the infrastructure on this tutorial out of your native pc or you should use AWS Cloud9 as your deployment workstation. AWS Cloud9 comes pre-loaded with the AWS CLI, AWS CDK, and Docker. Should you go for AWS Cloud9, create the surroundings from the AWS Cloud9 console.
Clear up
To keep away from pointless price, clear up all of the infrastructure created by way of the AWS CloudFormation console or by operating the next command in your workstation:
Moreover, keep in mind to cease any SageMaker endpoints you initiated by way of the SageMaker console. Bear in mind, deleting an Amazon Kendra index doesn’t take away the unique paperwork out of your storage.
Conclusion
Generative AI, epitomized by LLMs, heralds a paradigm shift in how we entry and generate data. These fashions, whereas highly effective, are sometimes restricted by the confines of their coaching information. RAG addresses this problem, making certain that the huge information inside these fashions is persistently infused with related, present insights.
Our RAG-based demos present a tangible testomony to this. They showcase the seamless synergy between Amazon Kendra, vector embeddings, and LLMs, making a system the place data isn’t solely huge but additionally correct and well timed. As you dive into these demos, you’ll discover firsthand the transformational potential of merging pre-trained information with the dynamic capabilities of RAG, leading to outputs which can be each reliable and tailor-made to enterprise content material.
Though generative AI powered by LLMs opens up a brand new approach of gaining data insights, these insights have to be reliable and confined to enterprise content material utilizing the RAG strategy. These RAG-based demos allow you to be outfitted with insights which can be correct and updated. The standard of those insights depends on semantic relevance, which is enabled by utilizing Amazon Kendra and vector embeddings.
Should you’re able to additional discover and harness the ability of generative AI, listed here are your subsequent steps:
- Interact with our demos – The hands-on expertise is invaluable. Discover the functionalities, perceive the integrations, and familiarize your self with the interface.
- Deepen your information – Benefit from the sources accessible. AWS gives in-depth documentation, tutorials, and group assist to help in your AI journey.
- Provoke a pilot undertaking – Think about beginning with a small-scale implementation of generative AI in your enterprise. This may present insights into the system’s practicality and adaptableness inside your particular context.
For extra details about generative AI functions on AWS, confer with the next:
Bear in mind, the panorama of AI is continually evolving. Keep up to date, stay curious, and at all times be able to adapt and innovate.
About The Authors
 Jin Tan Ruan is a Prototyping Developer inside the AWS Industries Prototyping and Buyer Engineering (PACE) workforce, specializing in NLP and generative AI. With a background in software program improvement and 9 AWS certifications, Jin brings a wealth of expertise to help AWS prospects in materializing their AI/ML and generative AI visions utilizing the AWS platform. He holds a grasp’s diploma in Pc Science & Software program Engineering from the College of Syracuse. Outdoors of labor, Jin enjoys enjoying video video games and immersing himself within the thrilling world of horror films.
Jin Tan Ruan is a Prototyping Developer inside the AWS Industries Prototyping and Buyer Engineering (PACE) workforce, specializing in NLP and generative AI. With a background in software program improvement and 9 AWS certifications, Jin brings a wealth of expertise to help AWS prospects in materializing their AI/ML and generative AI visions utilizing the AWS platform. He holds a grasp’s diploma in Pc Science & Software program Engineering from the College of Syracuse. Outdoors of labor, Jin enjoys enjoying video video games and immersing himself within the thrilling world of horror films.
 Aravind Kodandaramaiah is a Senior Prototyping full stack answer builder inside the AWS Industries Prototyping and Buyer Engineering (PACE) workforce. He focuses on serving to AWS prospects flip progressive concepts into options with measurable and pleasant outcomes. He’s passionate a couple of vary of subjects, together with cloud safety, DevOps, and AI/ML, and might be often discovered tinkering with these applied sciences.
Aravind Kodandaramaiah is a Senior Prototyping full stack answer builder inside the AWS Industries Prototyping and Buyer Engineering (PACE) workforce. He focuses on serving to AWS prospects flip progressive concepts into options with measurable and pleasant outcomes. He’s passionate a couple of vary of subjects, together with cloud safety, DevOps, and AI/ML, and might be often discovered tinkering with these applied sciences.
 Arjun Shakdher is a Developer on the AWS Industries Prototyping (PACE) workforce who’s captivated with mixing expertise into the material of life. Holding a grasp’s diploma from Purdue College, Arjun’s present function revolves round architecting and constructing cutting-edge prototypes that span an array of domains, presently prominently that includes the realms of AI/ML and IoT. When not immersed in code and digital landscapes, you’ll discover Arjun indulging on the planet of espresso, exploring the intricate mechanics of horology, or reveling within the artistry of vehicles.
Arjun Shakdher is a Developer on the AWS Industries Prototyping (PACE) workforce who’s captivated with mixing expertise into the material of life. Holding a grasp’s diploma from Purdue College, Arjun’s present function revolves round architecting and constructing cutting-edge prototypes that span an array of domains, presently prominently that includes the realms of AI/ML and IoT. When not immersed in code and digital landscapes, you’ll discover Arjun indulging on the planet of espresso, exploring the intricate mechanics of horology, or reveling within the artistry of vehicles.



/cdn.vox-cdn.com/uploads/chorus_asset/file/23932925/acastro_STK108__03.jpg)


