

We discover novel video illustration studying strategies which are geared up with long-form reasoning functionality. That is Half III offering a sneak peek into our newest and biggest explorations for “long-form” selfish video illustration studying. See Half I on video as a graph and is Half II on sparse video-text transformers.
The primary two blogs on this sequence described how completely different architectural motifs starting from graph neural networks to sparse transformers addressed the challenges of “long-form” video illustration studying. We confirmed how express graph based mostly strategies can mixture 5-10X bigger temporal context, however they have been two-stage strategies. Subsequent, we explored how we are able to make reminiscence and compute environment friendly end-to-end learnable fashions based mostly on transformers and mixture over 2X bigger temporal context.
On this weblog, I’ll take you to our newest and biggest explorations, particularly for selfish video understanding. As you’ll be able to think about, an selfish or first-person video (captured often by head-mounted cameras) is almost definitely coming from an always-ON digicam, that means the movies are actually actually lengthy, with a number of irrelevant visible info, specifically when the digicam wearer transfer their heads. And, this occurs a number of instances with head mounted cameras. A correct evaluation of such first-person movies can allow an in depth understanding of how people work together with the atmosphere, how they manipulate objects, and, finally, what are their objectives and intentions. Typical functions of selfish imaginative and prescient programs require algorithms in a position to characterize and course of video over temporal spans that final within the order of minutes or hours. Examples of such functions are motion anticipation, video summarization, and episodic reminiscence retrieval.

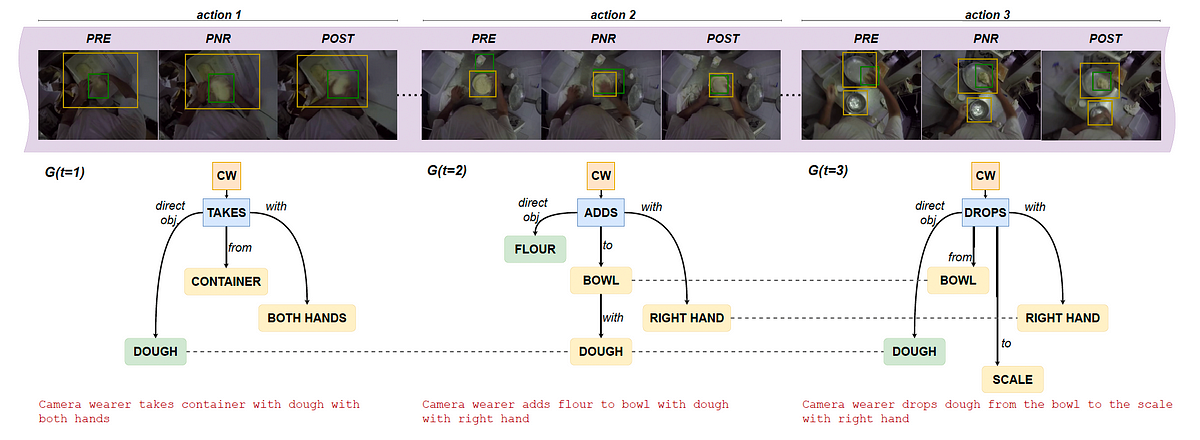
We current Selfish Motion Scene Graphs (EASGs), a brand new illustration for long-form understanding of selfish movies. EASGs prolong commonplace manually-annotated representations of selfish movies, equivalent to verb-noun motion labels, by offering a temporally evolving graph-based description of the actions carried out by the digicam wearer. The outline additionally consists of interacted objects, their relationships, and the way actions unfold in time. By means of a novel annotation process, we prolong the Ego4D dataset including manually labeled Selfish Motion Scene Graphs which supply a wealthy set of annotations for long-from selfish video understanding.
EASGs present annotations for a video clip within the type of a dynamic graph. We formalize an EASG as a time-varying directed graph G(t) = (V (t), E(t)), the place V (t) is the set of nodes at time t and E(t) is the set of edges between such nodes (Determine 2). Every temporal realization of the graph G(t) corresponds to an selfish motion spanning over a set of three frames outlined as in [Ego4D]: the precondition (PRE), the purpose of no return (PNR) and the postcondition (POST) frames. The graph G(t) is therefore successfully related to a few frames: F(t) = {PREₜ, PNRₜ, POSTₜ}, as proven in determine 1 under.
Selfish scene graph era:
Determine 2 exhibits an instance of an annotated graph in particulars.

We get hold of an preliminary EASG leveraging current annotations from Ego4D, with initialization and refinement process. e.g. we start with including the digicam wearer node, verb node and and the default motion edge from digicam wearer node to the verb node. The annotation pipeline is proven in determine 3 under.

Subsequent, we do the graph refinement by way of inputs from 3 annotators. The validation stage aggregates the information obtained from three annotators and ensures the standard of the ultimate annotations as proven under.

the labels offered within the annotation stage.
As it may be famous, the EASG dataset is exclusive in its labels. And, within the desk under you’ll be able to see how this new dataset compares with different video datasets with visible relations, by way of labels and measurement.

After the creation of this distinctive dataset, we are going to now describe completely different duties which are evaluated on this dataset. The primary set of duties is about producing motion scene graphs which stems from the picture scene graph era literature. In different phrases we goal to study EASG representations in a supervised manner and measure its efficiency in commonplace Recall metrics utilized in scene graph literature. We devise baselines and examine the EASG era efficiency of various baselines on this dataset.

Lengthy-from understanding duties with EASG:
We present the potential of the EASG illustration within the downstream duties of motion anticipation and exercise summarization. Each duties require to carry out long-form reasoning over the selfish video, processing lengthy video sequences spanning over completely different time-steps. Following current outcomes exhibiting the flexibleness of Massive Language Fashions (LLMs) as symbolic reasoning machines, we carry out these experiments with LLMs accessed by way of the OpenAI API. The experiments goal to look at the expressive energy of the EASG illustration and its usefulness for downstream functions. We present that EASG affords an expressive manner of modeling long-form actions, as compared with the gold-standard verb-noun motion encoding, extensively adopted in selfish video neighborhood.
Motion anticipation with EASGs:
For the motion anticipation activity, we use the GPT3 text-davinci-003 mannequin. We immediate the mannequin to foretell the longer term motion from a sequence of size T ∈ {5, 20}. We examine two sorts of representations — EASG and sequences of verb-noun pairs. Under desk exhibits the outcomes of this experiment.

Even quick EASG sequences (T =5) are inclined to outperform lengthy V-N sequences (T = 20), highlighting the upper illustration energy of EASG, when in comparison with commonplace verb-noun representations. EASG representations obtain the perfect outcomes for lengthy sequences (T = 20).
Lengthy-form exercise summarization with EASGs:
We choose a subset of 147 Ego4D-EASG clips containing human-annotated summaries describing the actions carried out inside the clip in 1–2 sentences from Ego4D. We assemble three sorts of enter sequences: sequences of graphs S-EASG = [G(1), G(2), …, G(Tmax)], sequences of verb-noun pairs svn = [s-vn(1), s-vn(2), …, s-vn(Tmax)], and sequences of authentic Ego4D narrations, matched with the EASG sequence. This final enter is reported for reference, as we count on summarization from narrations to carry the perfect efficiency, given the pure bias of language fashions in direction of this illustration.
Outcomes reported within the under desk point out robust enchancment in CIDEr rating over the sequence of verb-noun inputs, exhibiting that fashions which course of EASG inputs capturing detailed object motion relationships, will generate extra particular, informative sentences that align effectively with reference descriptions.

We imagine that these contributions mark a step ahead in long-form selfish video understanding.
Highlights:
- We introduce Selfish Motion Scene Graphs, a novel illustration for long-form understanding of selfish movies;
- We prolong Ego4D with manually annotated EASG labels, that are gathered by way of a novel annotation process;
- We suggest a EASG era baseline and supply preliminary baseline outcomes;
- We current experiments that spotlight the effectiveness of the EASG illustration for long-form selfish video understanding. We are going to launch the dataset and the code to copy information annotation and the
experiments; - We are going to current this work at CVPR 2024, subsequent month.
In recent times, selfish video-language pre-training (VLP) has been adopted considerably in academia and in trade. A line of works equivalent to EgoVLP, EgoVLPv2 study transferable spatial-temporal representations from large-scale video-text datasets. Just lately, LaViLa confirmed that VLP can profit from the dense narrations generated by Massive Language Fashions (LLMs). Nevertheless, all such strategies do hit the reminiscence and compute bottleneck whereas processing video sequences, every consisting of a small variety of frames (e.g. 8 or 16 body fashions), resulting in restricted temporal context aggregation functionality. Quite the opposite, our mannequin, referred to as LAVITI, is supplied with long-form reasoning functionality (1,000 frames vs 16 frames) and isn’t restricted to a small variety of enter frames.
On this ongoing work, we devised a novel method to studying language, video, and temporal representations in long-form movies by way of contrastive studying. In contrast to current strategies, this new method goals to align language, video, and temporal options by extracting significant moments in untrimmed movies by formulating it as a direct set prediction downside. LAVITI outperforms current state-of-the-art strategies by a major margin on selfish motion recognition, but is trainable on reminiscence and compute-bound programs. Our methodology will be skilled on the Ego4D dataset with solely 8 NVIDIA RTX-3090 GPUs in a day.

As our mannequin is able to long-form video understanding with express temporal alignment, the Ego4D Pure Language Question (NLQ) activity is a pure match with the pre-training targets. We are able to straight predict intervals that are aligned with language question given a video; due to this fact, LAVITI can
carry out the NLQ activity underneath the zero-shot setting (with out modifications of the structure and re-training on NLQ annotations).
Within the close to future, we plan on assessing its potential to study improved representations for episodic reminiscence duties together with NLQ and Second Question (MQ). To summarize, we’re leveraging current basis fashions (primarily “short-term”) for creating “long-form” reasoning module aiming at 20X-50X bigger context aggregation.
Highlights:
We devised thrilling new methods for selfish video understanding. Our contributions are manifold.
- Pre-training goal aligns language, video, and temporal options collectively by extracting significant moments in untrimmed movies;
- formulating the video, language and temporal alignment as a direct set prediction downside;
- enabling long-form reasoning over probably 1000’s of frames of a video in a memory-compute environment friendly manner;
- demonstrating the efficacy of LAVITI by its superior efficiency on CharadesEgo motion recognition;
- Enabling zero-shot pure language question (NLQ) activity without having to coach extra subnetworks or NLQ annotations.
Be careful for extra thrilling outcomes with this new paradigm of “long-form” video illustration studying!





/cdn.vox-cdn.com/uploads/chorus_asset/file/25547597/Screen_Shot_2024_07_26_at_3.55.30_PM.png)
