


Synthetic intelligence’s massive language fashions (LLMs) have turn out to be important instruments as a result of their capability to course of and generate human-like textual content, enabling them to carry out varied duties. These fashions rely closely on high-quality instruction datasets for fine-tuning, which boosts their capability to know and comply with complicated directions. The success of LLMs in varied purposes, from chatbots to information evaluation, hinges on the range and high quality of the instruction information they’re skilled with.
Entry to high-quality, numerous instruction datasets mandatory for aligning LLMs is one in all many challenges for the sector. Though some fashions like Llama-3 have open weights, the related alignment information usually stays proprietary, limiting broader analysis and growth efforts. Developing large-scale instruction datasets is labor-intensive and expensive, making reaching the required scale and variety tough. This limitation hinders the development of LLM capabilities and their utility in numerous, real-world eventualities.
Present strategies for producing instruction datasets fall into two classes: human-curated information and artificial information produced by LLMs. Human-curated datasets, whereas exact, could possibly be extra scalable as a result of excessive prices and time required for handbook information era and curation. Then again, artificial information era strategies contain utilizing LLMs to provide directions based mostly on preliminary seed questions and immediate engineering. Nonetheless, these strategies usually want extra range because the dataset dimension will increase, because the generated directions are typically too just like the seed questions.
Researchers from the College of Washington and Allen Institute for AI launched a novel methodology known as MAGPIE. MAGPIE leverages the auto-regressive nature of aligned LLMs to generate high-quality instruction information at scale. This methodology includes prompting the LLM with solely predefined templates, permitting the mannequin to create consumer queries and their corresponding responses autonomously. This method eliminates the necessity for handbook immediate engineering and seed questions, guaranteeing a various and in depth instruction dataset.
The MAGPIE methodology consists of two fundamental steps:
- Instruction era
- Response era
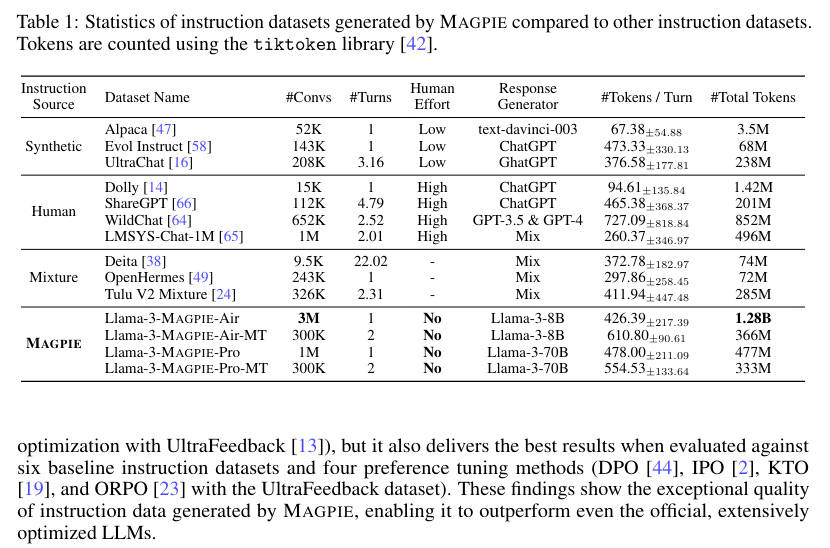
Within the instruction era step, predefined templates are enter into an aligned LLM, reminiscent of Llama-3-8B-Instruct. The mannequin then generates numerous consumer queries based mostly on these templates. Within the response era step, these queries immediate the LLM once more to provide corresponding responses, leading to full instruction-response pairs. This automated course of is environment friendly, requiring no human intervention and using 206 and 614 GPU hours to generate the MAGPIE-Air and MAGPIE-Professional datasets.
Researchers utilized the MAGPIE methodology to create two instruction datasets, MAGPIE-Air and MAGPIE-Professional, generated utilizing Llama-3-8B-Instruct and Llama-3-70B-Instruct fashions, respectively. These datasets embody single-turn and multi-turn directions, with MAGPIE-Air-MT and MAGPIE-Professional-MT containing sequences of multi-turn directions and responses. The generated datasets have been then filtered to pick out high-quality cases, leading to MAGPIE-Air-300K-Filtered and MAGPIE-Professional-300K-Filtered datasets.
The efficiency of fashions fine-tuned with MAGPIE datasets was in contrast in opposition to these skilled with different public instruction datasets, reminiscent of ShareGPT, WildChat, Evol Instruct, UltraChat, and OpenHermes. The outcomes indicated that fashions fine-tuned with MAGPIE information carried out comparably to the official Llama-3-8B-Instruct mannequin, which was skilled utilizing over 10 million information factors. As an illustration, the fashions fine-tuned with MAGPIE datasets achieved a win charge (WR) of 29.47% in opposition to GPT-4-Turbo (1106) on the AlpacaEval 2 benchmark and surpassed the official mannequin on varied alignment benchmarks, together with Area-Onerous and WildBench.

In conclusion, the introduction of the MAGPIE methodology represents a big development within the scalable era of high-quality instruction datasets for LLM alignment. By automating the information era course of and eliminating the necessity for immediate engineering and seed questions, MAGPIE ensures a various and in depth dataset, enabling LLMs to carry out higher on varied duties. The effectivity and effectiveness of MAGPIE make it a beneficial device for researchers and builders trying to improve the capabilities of LLMs.
Try the Paper, Challenge, and Fashions. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 44k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.

/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



