


There are actually two tales packaged in the latest MLPerf Coaching 4.0 outcomes, launched in the present day. The primary, in fact, is the outcomes. Nvidia (presently king of accelerated computing) wins once more, sweeping all 9 “occasions” (workflows) because it have been. Its lead stays formidable. Story quantity two, maybe extra essential, is MLPerf itself. It has matured by way of years to change into a much more helpful broad software to guage competing ML-centric programs and working environments.
![]() Backside line, as a handicapping software for GPUs and their like, MLPerf is maybe lower than first supposed as a result of there are few contenders, however fairly helpful as a software for potential patrons to guage programs and for builders to evaluate rival programs. MLPerf has more and more changing into an ordinary merchandise on their checklists. (We’ll skip the v. slight confusion from mixing MLPerf’s father or mother entity’s identify, MLCommons, with MLPerf, the identify of the portfolio of benchmark suites).
Backside line, as a handicapping software for GPUs and their like, MLPerf is maybe lower than first supposed as a result of there are few contenders, however fairly helpful as a software for potential patrons to guage programs and for builders to evaluate rival programs. MLPerf has more and more changing into an ordinary merchandise on their checklists. (We’ll skip the v. slight confusion from mixing MLPerf’s father or mother entity’s identify, MLCommons, with MLPerf, the identify of the portfolio of benchmark suites).
The newest MLPerf Coaching train provides two new benchmarks — LoRA fine-tuning of LLama 2 70B and GNN (graph neural community) — and energy metrics (non-compulsory) have been additionally added to coaching. There have been greater than 205 efficiency outcomes from 17 submitting organizations: ASUSTeK, Dell, Fujitsu, Giga Computing, Google, HPE, Intel (Habana Labs), Juniper Networks, Lenovo, NVIDIA, NVIDIA + CoreWeave, Oracle, Quanta Cloud Know-how, Crimson Hat + Supermicro, Supermicro, Sustainable Steel Cloud (SMC), and tiny corp.



Whereas Nvidia GPUs once more dominated, Intel’s Habana Gaudi2 accelerator, Google TPU v-5P, and AMD’s Radeon RX 7900 XTX GPU (first-time participant) all had robust showings.
As proven above, MLCommons has steadily grown its portfolio of benchmarks. Coaching, launched in 2018, was the primary and is usually thought to be probably the most computationally intense. David Kanter emphasised the enhancing efficiency of coaching submission, crediting the MLPerf workout routines with serving to drive positive aspects.
“[MLPerf], by bringing the entire group collectively, focuses us on what’s essential. And this can be a slide that exhibits the advantages. [It] is an illustration of Moore’s regulation — that’s the yellow line on the backside. On the what x axis is time, and on the y axis is relative efficiency. That is normalized efficiency for the most effective outcomes on every benchmark in MLPerf, and the way it improves over time,” mentioned Kanter at a media/analyst pre-briefing.
“What you’ll be able to see (slide under) is that in lots of instances we’re delivering 5 or 10x higher efficiency than Moore’s regulation. That implies that not solely are we profiting from higher silicon, however we’re getting higher architectures, higher algorithms, higher scaling, all of these items come collectively to present us dramatically higher efficiency over time. In case you look again within the rear view mirror, since we began, it’s about 50x higher, barely extra, however even should you have a look at relative to the final cycle, a few of our benchmarks acquired practically 2x higher efficiency, specifically Secure Diffusion. In order that’s fairly spectacular in six months.”



Including graph neural community and advantageous tuning to the coaching train have been pure steps. Ritika Borkar and Hiwot Kassa, MLPerf Coaching working group co-chairs, walked by way of the brand new workflows.
Borkar mentioned, “There’s a big class of knowledge on the earth which could be represented within the type of graphs — a group of nodes and edges connecting the totally different nodes. For instance, social networks, molecules, database, and log pages, and GNN, or graph neural networks, is the category of networks which can be used to encapsulate info from such graph structured information, and in consequence, you see GNNs in a variety of economic purposes, comparable to recommender programs or adverts fraud detection or drug discovery or doing graph answering or data graphs.
“An instance famous right here is Alibaba Taobao advice system, which relies on a GNN community; it makes use of person conduct graph to which is of the magnitude of billions of vertices and edges. In order you’ll be able to think about, when it’s a must to when a system has to work with graphs of this massive magnitude, there are attention-grabbing efficiency traits that which can be demanded from the system. And on that spirit, we needed to incorporate this type of problem within the developer benchmark go well with.”

With regard to advantageous tuning LLMs, Kassa mentioned, “We will divide the state of coaching LLM, at a excessive degree, into two states. One is free coaching, the place LLMs are skilled on giant unlabeled information for normal function language understanding. This will take days to months to coach and is computationally intensive. [The] GPT-3 benchmark and MLPerf coaching exhibits this part, so we have now that half already lined. The subsequent part is okay tuning, [which] is the place we’re taking pre skilled mannequin and we’re coaching it with particular job, particular labeled information units to reinforce its accuracy on particular duties, like, textual content summarization on particular matters. In advantageous tuning, we’re utilizing much less compute or reminiscence useful resource [and] we have now much less value for coaching. It’s changing into broadly accessible and utilized in giant vary of AI customers, and including it to MLPerf is essential and well timed proper now.
“When choosing advantageous tuning methods we thought-about various methods, and we chosen parameter environment friendly advantageous tuning, which is a advantageous tuning method that trains or tunes solely a subset of the general mannequin parameters (PEFT); this considerably decreased coaching time and computational effectivity in comparison with the standard advantageous tuning methods that tunes all parameters. And from the PEFT technique, we chosen LoRA (low-rank adaption) that permits coaching of dense layers by way of rank decomposition matrix whereas sustaining the pre-trained weights frozen. This method considerably decreased {hardware} requirement, reminiscence utilization, storage whereas nonetheless being performant in comparison with a completely advantageous tuned fashions,” she mentioned.


Inclusion of the ability metric in coaching was additionally new and now broadly used but, however given present considerations round power use by AI know-how and datacenters usually, its significance appears more likely to develop.

As all the time digging out significant outcomes from MLPerf coaching a painstaking effort in that system configurations fluctuate broadly and as does efficiency throughout the totally different workflows. Really, creating a better strategy to accomplish this may be a helpful addition to MLPerf presentation arsenal, although maybe unlikely as MLCommons is unlikely to need to highlight higher performers and antagonize lesser performers. Nonetheless, it’s maybe a worthwhile objective. Right here’s a hyperlink to the Coaching 4.0 outcomes.
Per regular observe, MLCommons invitations members to submit temporary statements supposed to highlight options that enhance efficiency on the MLPerf benchmarks. So do that effectively whereas others are not more than advertising and marketing data. These statements are appended to this text and value scanning.
Nvidia was once more the dominant winner by way of accelerator efficiency. That is an previous chorus. Intel (Habana, Gaudi2), AMD, and Google all had entries. Intel’s Gaudi3 is anticipated to obtainable within the fall and the corporate mentioned it plans to enter it within the fall MLPerf Inference benchmark.
Listed here are temporary excerpts from three submitted statements:
Intel — “Coaching and fine-tuning outcomes present aggressive Intel Gaudi accelerator efficiency at each ends of the coaching and fine-tuning spectrum. The v4.0 benchmark options time-to-train (TTT) of a consultant 1% slice of the GPT-3 mannequin, a precious measurement for assessing coaching efficiency on a really giant 175B parameter mannequin. Intel submitted outcomes for GPT-3 coaching for time-to-train on 1024 Intel Gaudi accelerators, the biggest cluster outcome to be submitted by Intel thus far, with TTT of 66.9 minutes, demonstrating robust Gaudi 2 scaling efficiency on ultra-large LLMs.
“The benchmark additionally encompasses a new coaching measurement: fine-tuning a Llama 2 mannequin with 70B parameters. Effective-tuning LLMs is a typical job for a lot of prospects and AI practitioners, making it a spotlight related benchmark for on a regular basis purposes. Intel’s submission achieved a time-to-train of 78.1 minutes utilizing 8 Intel Gaudi 2 accelerators. The submission leverages Zero-3 from DeepSpeed for optimizing reminiscence effectivity and scaling throughout giant mannequin coaching, in addition to Flash-Consideration-2 to speed up consideration mechanisms.”
Juniper Networks — “For MLPerf Coaching v4.0, Juniper submitted benchmarks for BERT, DLRM, and Llama2-70B with LoRA advantageous tuning on a Juniper AI Cluster consisting of Nvidia A100 and H100 GPUs utilizing Juniper’s AI Optimized Ethernet cloth because the accelerator interconnect. For BERT, we optimized pre-training duties utilizing a Wikipedia dataset, evaluating efficiency with MLM accuracy. Our DLRM submission utilized the Criteo dataset and HugeCTR for environment friendly dealing with of sparse and dense options, with AUC because the analysis metric, attaining distinctive efficiency. The Llama2-70B mannequin was fine-tuned utilizing LoRA methods with DeepSpeed and Hugging Face Speed up, optimizing gradient accumulation for balanced coaching pace and accuracy.
“Most submissions have been made on a multi-node setup, with PyTorch, DeepSpeed, and HugeCTR optimizations. Crucially, we optimized inter-node communication with RoCE v2, making certain low-latency, high-bandwidth information transfers, that are essential for environment friendly, distributed coaching workloads.”
Google — “Cloud TPU v5p reveals near-linear scaling efficiency (roughly 99.9% scaling effectivity) on the GPT-3 175b mannequin pre-training job, starting from 512 to 6144 chips. Beforehand, within the MLPerf Coaching v3.1 submission for a similar job, we demonstrated horizontal scaling capabilities of TPU v5e throughout 16 pods (4096 chips) linked over a knowledge middle community (throughout a number of ICI domains). On this submission, we’re showcasing the scaling to 6144 TPU v5p chips podslice (inside a single ICI area). For a comparable compute scale (1536 TPU v5p chips versus 4096 TPU v5e chips), this submission additionally exhibits an approximate 31% enchancment in effectivity (measured as mannequin flops utilization).
“This submission additionally showcases Google/MaxText, Google Cloud’s reference implementation for giant language fashions. The coaching was accomplished utilizing Int8 combined precision, leveraging Correct Quantized Coaching. Close to-linear scaling effectivity demonstrated throughout 512, 1024, 1536, and 6144 TPU v5p slices is an end result of optimizations from codesign throughout the {hardware}, runtime & compiler (XLA), and framework (JAX). We hope that this work will reinforce the message of effectivity which interprets to efficiency per greenback for large-scale coaching workloads.”
Again to Nvidia, final however hardly least. David Salvator, director of accelerated computing merchandise, led a separate briefing on Nvidia’s newest MLPerf exhibiting and maybe just a little chest-thumping is justified.
“So there are 9 workloads in MLPerf and we’ve set new information on 5 of these 9 workloads, which you see form of throughout the highest row (slide under). There a few these are literally model new workloads, the graph, neural community, in addition to the LLM advantageous tuning workloads, are web new workloads to this model of MLPerf. However as well as, we’re continuously optimizing and tuning our software program, and we are literally publishing our containerized software program to the group on a few month-to-month cadence,” mentioned Salvator.
“Along with the 2 new fashions the place we set new information, we’ve even improved our efficiency on three of the prevailing fashions, which you see on sort of the correct hand aspect. We even have standing information on the extra 4 workloads, so we mainly maintain information throughout all 9 workloads of MLPerf coaching. And that is simply an absolute tip of the hat and [to] our engineering groups to repeatedly enhance efficiency and get extra efficiency from our present architectures. These have been all achieved on the hopper structure proper.”

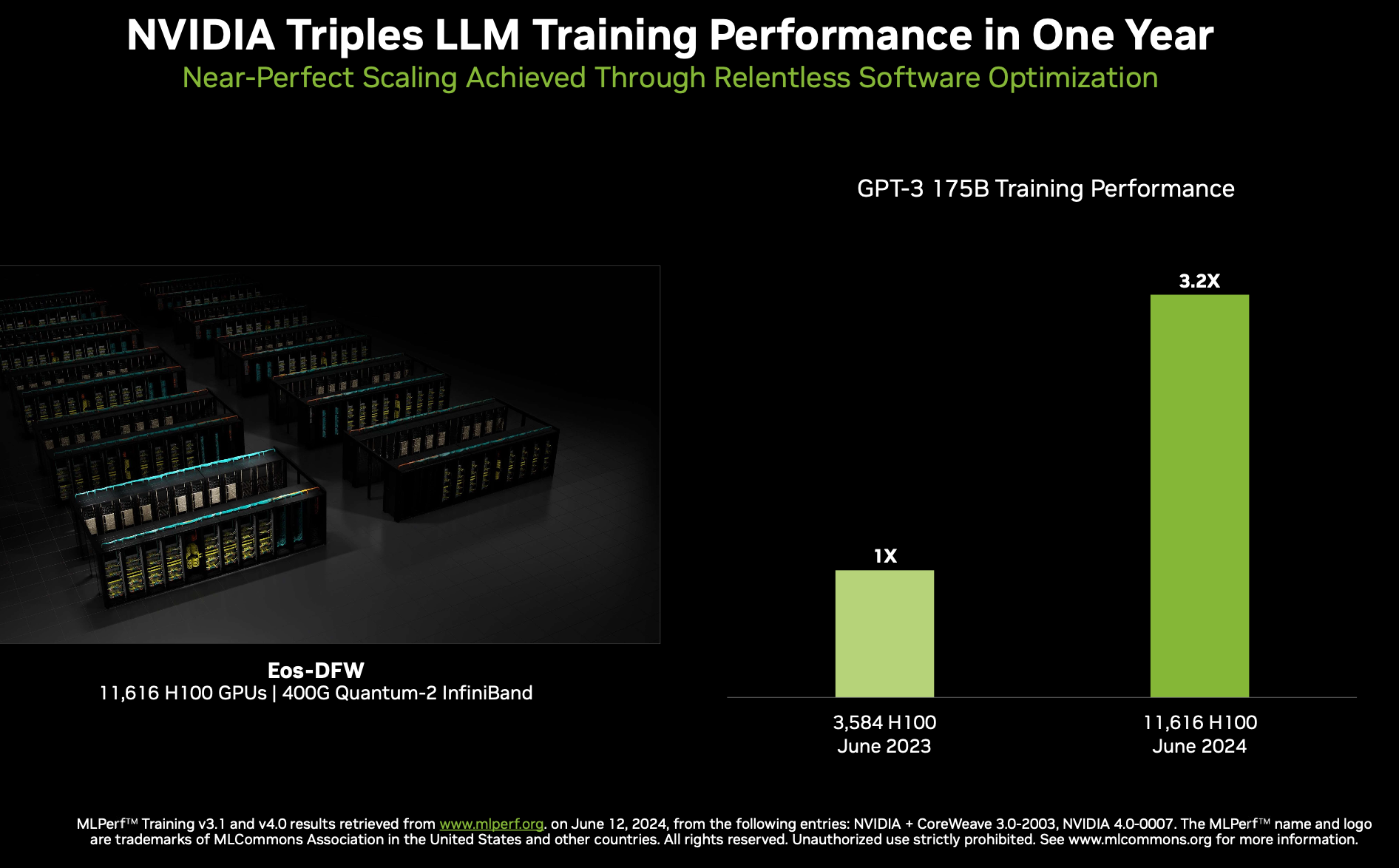
“A few yr in the past, proper, we did a submission at about 3500 GPUs. That was with the software program we had on the time. That is form of a historic evaluate. In case you quick ahead to in the present day, on a most up-to-date submission of 11,616 GPUs, which is the most important at scale submission we’ve ever accomplished. What you see is that we’ve nearly tripled the outcomes, plus just a little. Right here’s what’s attention-grabbing about that. In case you really do the mathematics on 1116, divided by 3584 you’ll see that it’s about 3.2x so what which means is we’re getting basically linear scaling proper now. Lots of instances with workloads, as you go to a lot bigger scales, if you may get 65%-to-70% scaling effectivity, you’re fairly completely happy should you get 80% scaling effectivity. What we’ve been capable of do by way of a mixture of extra {hardware} but in addition a whole lot of software program tuning to get linear scaling on this workload. It’s very uncommon for this to occur,” mentioned Salvator.

Salvator has additionally posted a weblog on the most recent outcomes. It’s greatest to dig into the particular outcomes to ferret helpful perception in your specific functions.
Hyperlink to MLPerf Coaching 4.0 outcomes, https://mlcommons.org/benchmarks/coaching/
MLPerf 4.0 Submitted Assertion by Distributors
The submitting organizations offered the next descriptions as a complement to assist the general public perceive their MLPerf Coaching v4.0 submissions and outcomes. The statements don’t replicate the opinions or views of MLCommons.
Asus
ASUS, a worldwide chief in high-performance computing options, proudly broadcasts its collaboration with MLPerf, the industry-standard benchmark for machine studying efficiency, to show the distinctive capabilities of its ESC-N8A and ESC8000A-E12 servers within the MLPerf Coaching v4.0 benchmarks.
The collaboration highlights ASUS’s dedication to advancing AI and machine studying applied sciences. The ESC-N8A and ESC8000A-E12 servers, outfitted with cutting-edge {hardware}, have showcased exceptional efficiency and effectivity within the rigorous MLPerf Coaching v4.0 evaluations.
This collaboration with MLPerf reinforces ASUS’s function as a pioneer in AI and machine studying innovation. By regularly pushing the boundaries of what’s doable, ASUS goals to empower researchers, information scientists, and enterprises with the instruments they should drive technological developments and obtain breakthrough outcomes.
Partnering with MLPerf permits us to validate our servers’ capabilities in probably the most demanding AI benchmarks. The excellent outcomes achieved by the ESC-N8A and ESC8000A-E12 servers in MLPerf Coaching v4.0 spotlight our dedication to delivering high-performance, scalable, and environment friendly options for AI workloads
Dell Applied sciences
Dell Applied sciences continues to speed up the AI revolution by creating the {industry}’s first AI Manufacturing facility with NVIDIA. On the coronary heart of this manufacturing unit is the continued dedication to advancing AI workloads. MLPerf submissions function a testomony to Dell’s dedication to serving to prospects make knowledgeable selections. Within the MLPerf v4.0 Coaching Benchmark submissions, Dell PowerEdge servers confirmed glorious efficiency.
Dell submitted two new fashions, together with Llama 2 and Graph Neural Networks. The Dell PowerEdge XE9680 server with 8 NVIDIA H100 Tensor Core GPUs continued to ship Dell’s greatest efficiency outcomes.
The Dell PowerEdge XE8640 server with 4 NVIDIA H100 GPUs and its direct liquid-cooled (DLC) sibling, the Dell PowerEdge XE9640, additionally carried out very effectively. The XE8640 and XE9640 servers are perfect for purposes requiring a balanced ratio of fourth-generation Intel Xeon Scalable CPUs to SXM or OAM GPU cores. The PowerEdge XE9640 was purpose-built for high-efficiency DLC, decreasing the four-GPU server profile to a dense 2RU kind issue, yielding most GPU core density per rack.
The Dell PowerEdge R760xa server was additionally examined, utilizing 4 L40S GPUs and rating excessive in efficiency for coaching these fashions. The L40S GPUs are PCIe-based and energy environment friendly. The R760xa is a mainstream 2RU server with optimized energy and airflow for PCIe GPU density.
Generate larger high quality, sooner time-to-value predictions, and outputs whereas accelerating decision-making with highly effective options from Dell Applied sciences. Come and take a take a look at drive in one in every of our worldwide Buyer Resolution or collaborate with us utilizing one in every of our innovation labs to faucet into one in every of our Facilities of Excellence.
Fujitsu
Fujitsu gives a improbable mix of programs, options, and experience to ensure most productiveness, effectivity, and adaptability delivering confidence and reliability. Since 2020, we have now been actively collaborating in and submitting to inference and coaching rounds for each information middle and edge divisions.
On this spherical, we submitted benchmark outcomes with two programs. The primary is PRIMERGY CDI, outfitted with 16 L40S GPUs in exterior PCIe-BOXes, and the second is PRIMERGY GX2560M7, outfitted with 4 H100 SXM GPUs contained in the server. The PRIMERGY CDI can accommodate as much as 20 GPUs in three exterior PCI-BOXes as a single node server and might share the assets amongst a number of nodes. Moreover, the system configuration could be adjusted in response to the scale of coaching and inference workloads. Measurement outcomes are displayed within the determine under. In image-related benchmarks, PRIMERGY CDI dominated, whereas PRIMERGY GX2560K7 excelled in language-related benchmarks.
Our function is to make the world extra sustainable by constructing belief in society by way of innovation. With a wealthy heritage of driving innovation and experience, we’re devoted to contributing to the expansion of society and our valued prospects. Due to this fact, we are going to proceed to fulfill the calls for of our prospects and attempt to supply enticing server programs by way of the actions of MLCommons.
Giga Computing
The MLPerf Coaching benchmark submitter – Giga Computing – is a GIGABYTE subsidiary that made up GIGABYTE’s enterprise division that designs, manufactures, and sells GIGABYTE server merchandise.
The GIGABYTE model has been acknowledged as an {industry} chief in HPC & AI servers and has a wealth of expertise in creating {hardware} for all information middle wants, whereas working alongside know-how companions: NVIDIA, AMD, Ampere Computing, Intel, and Qualcomm.
In 2020, GIGABYTE joined MLCommons and submitted its first system. And with this spherical of the most recent benchmarks, MLPerf Coaching v4.0 (closed division), the submitted GIGABYTE G593 Collection platform has proven its versatility in supporting each AMD EPYC and Intel Xeon processors. The efficiency is within the pudding, and these benchmarks (v3.1 and v4.0) exemplify the spectacular efficiency that’s doable within the G593 sequence. Moreover, larger compute density and rack density are additionally part of the G593 design that has been thermally optimized in a 5U kind issue.
- ● GIGABYTE G593-SD1: dense accelerated computing in a 5U server o 2x Intel Xeon 8480+ CPUs
o 8x NVIDIA SXM H100 GPUs
o Optimized for baseboard GPUs - ● Benchmark frameworks: Mxnet, PyTorch, dgl, hugectr
To be taught extra about our options, go to: https://www.gigabyte.com/Enterprise
Giga Computing’s web site continues to be being rolled out: https://www.gigacomputing.com/
Google Cloud
Within the MLPerf Coaching model 4.0 coaching submission, we’re happy to current Google Cloud TPU v5p, our most scalable TPU in manufacturing.
Cloud TPU v5p reveals near-linear scaling efficiency (roughly 99.9% scaling effectivity) on the GPT-3 175b mannequin pre-training job, starting from 512 to 6144 chips. Beforehand, within the MLPerf Coaching v3.1 submission for a similar job, we demonstrated horizontal scaling capabilities of TPU v5e throughout 16 pods (4096 chips) linked over a knowledge middle community (throughout a number of ICI domains). On this submission, we’re showcasing the scaling to 6144 TPU v5p chips podslice (inside a single ICI area). For a comparable compute scale (1536 TPU v5p chips versus 4096 TPU v5e chips), this submission additionally exhibits an approximate 31% enchancment in effectivity (measured as mannequin flops utilization).
This submission additionally showcases Google/MaxText, Google Cloud’s reference implementation for giant language fashions. The coaching was accomplished utilizing Int8 combined precision, leveraging Correct Quantized Coaching. Close to-linear scaling effectivity demonstrated throughout 512, 1024, 1536, and 6144 TPU v5p slices is an end result of optimizations from codesign throughout the {hardware}, runtime & compiler (XLA), and framework (JAX). We hope that this work will reinforce the message of effectivity which interprets to efficiency per greenback for large-scale coaching workloads.
Hewlett Packard Enterprise
Hewlett Packard Enterprise (HPE) demonstrated robust inference efficiency in MLPerf Inference v4.0 together with robust AI mannequin coaching and fine-tuning efficiency in MLPerf Coaching v4.0. Configurations this spherical featured an HPE Cray XD670 server with 8x NVIDIA H100 SXM 80GB Tensor Core GPUs and HPE ClusterStor parallel storage system as backend storage. HPE Cray programs mixed with HPE ClusterStor are the proper option to energy data-intensive workloads like AI mannequin coaching and fine-tuning.
HPE’s outcomes this spherical included single- and double-node configurations for on-premise deployments. HPE participated throughout three classes of AI mannequin coaching: giant language mannequin (LLM) fine-tuning, pure language processing (NLP) coaching, and laptop imaginative and prescient coaching. In all submitted classes and AI fashions, HPE Cray XD670 with NVIDIA H100 GPUs achieved the corporate’s quickest time-to-train efficiency thus far for MLPerf on single- and double-node configurations. HPE additionally demonstrated distinctive efficiency in comparison with earlier coaching submissions, which used NVIDIA A100 Tensor Core GPUs.
Primarily based on our benchmark outcomes, organizations could be assured in attaining robust efficiency after they deploy HPE Cray XD670 to energy AI coaching and tuning workloads.
Intel (Habana Labs)
Intel is happy to take part within the MLCommons newest benchmark, Coaching v4.0, submitting time-to-train outcomes for GPT-3 coaching and Llama-70B fine-tuning with its Intel Gaudi 2 AI accelerators.
Coaching and fine-tuning outcomes present aggressive Intel Gaudi accelerator efficiency at each ends of the coaching and fine-tuning spectrum. The v4.0 benchmark options time-to-train (TTT) of a consultant 1% slice of the GPT-3 mannequin, a precious measurement for assessing coaching efficiency on a really giant 175B parameter mannequin. Intel submitted outcomes for GPT-3 coaching for time-to-train on 1024 Intel Gaudi accelerators, the biggest cluster outcome to be submitted by Intel thus far, with TTT of 66.9 minutes, demonstrating robust Gaudi 2 scaling efficiency on ultra-large LLMs.
The benchmark additionally encompasses a new coaching measurement: fine-tuning a Llama 2 mannequin with 70B parameters. Effective-tuning LLMs is a typical job for a lot of prospects and AI practitioners, making it a spotlight related benchmark for on a regular basis purposes. Intel’s submission achieved a time-to-train of 78.1 minutes utilizing 8 Intel Gaudi 2 accelerators. The submission leverages Zero-3 from DeepSpeed for optimizing reminiscence effectivity and scaling throughout giant mannequin coaching, in addition to Flash-Consideration-2 to speed up consideration mechanisms.
The benchmark job power – led by the engineering groups from Intel’s Habana Labs and Hugging Face, who additionally function the benchmark homeowners – are liable for the reference code and benchmark guidelines.
The Intel group appears to be like ahead to submitting MLPerf outcomes primarily based on the Intel Gaudi 3 AI accelerator within the upcoming inference benchmark. Introduced in April, options primarily based on Intel Gaudi 3 accelerators shall be usually obtainable from OEMs in fall 2024.
Juniper Networks
Juniper is thrilled to collaborate with MLCommons to speed up AI innovation and make information middle infrastructure easier, sooner and extra economical to deploy. Coaching AI fashions is an enormous, parallel processing downside depending on strong networking options. AI workloads have distinctive traits and current new necessities for the community, however fixing robust challenges comparable to these is what Juniper has been doing for over 25 years.
For MLPerf Coaching v4.0, Juniper submitted benchmarks for BERT, DLRM, and Llama2-70B with LoRA advantageous tuning on a Juniper AI Cluster consisting of Nvidia A100 and H100 GPUs utilizing Juniper’s AI Optimized Ethernet cloth because the accelerator interconnect. For BERT, we optimized pre-training duties utilizing a Wikipedia dataset, evaluating efficiency with MLM accuracy. Our DLRM submission utilized the Criteo dataset and HugeCTR for environment friendly dealing with of sparse and dense options, with AUC because the analysis metric, attaining distinctive efficiency. The Llama2-70B mannequin was fine-tuned utilizing LoRA methods with DeepSpeed and Hugging Face Speed up, optimizing gradient accumulation for balanced coaching pace and accuracy.
Most submissions have been made on a multi-node setup, with PyTorch, DeepSpeed, and HugeCTR optimizations. Crucially, we optimized inter-node communication with RoCE v2, making certain low-latency, high-bandwidth information transfers, that are essential for environment friendly, distributed coaching workloads.
Juniper is dedicated to an operations-first strategy to assist prospects handle all the information middle lifecycle with market-leading capabilities in intent-based networking, AIOps and 800Gb Ethernet. Open applied sciences comparable to Ethernet and our Apstra information middle cloth automation software program remove vendor lock-in, benefit from the {industry} ecosystem to push down prices and drive innovation, and allow frequent community operations throughout AI coaching, inference, storage and administration networks. As well as, rigorously pre-tested, validated designs are essential to make sure that prospects can deploy safe information middle infrastructure on their very own.
Lenovo
Leveraging MLPerf Coaching v4.0, Lenovo Drives AI Innovation
At Lenovo, we’re devoted to empowering our prospects with cutting-edge AI options that rework industries and enhance lives. To attain this imaginative and prescient, we put money into rigorous analysis and testing utilizing the most recent MLPerf Coaching v4.0 benchmarking instruments.
Benchmarking Excellence: Collaborative Efforts Yield Business-Main Outcomes
By way of our strategic partnership with MLCommons, we’re capable of show our AI options’ efficiency and capabilities quarterly, showcasing our dedication to innovation and buyer satisfaction. Our collaborations with {industry} leaders like NVIDIA and AMD on essential AI purposes comparable to picture classification, medical picture segmentation, speech-to-text, and pure language processing have enabled us to attain excellent outcomes.
ThinkSystem SR685A v3 with 8x NVIDIA H100 (80Gb) GPUs and the SR675 v3 with 8x NVIDIA L40s GPUs: Delivering AI-Powered Options
We’re proud to have participated in these challenges utilizing our ThinkSystem SR685A v3 with 8x NVIDIA H100 (80Gb) GPUs and the SR675 v3 with 8x NVIDIA L40s GPUs. These highly effective programs allow us to develop and deploy AI-powered options that drive enterprise outcomes and enhance buyer experiences.
Partnership for Progress: MLCommons Collaboration Enhances Product Growth
Our partnership with MLCommons supplies precious insights into how our AI options evaluate towards the competitors, units buyer expectations, and permits us to constantly improve our merchandise. By way of this collaboration, we will work carefully with {industry} consultants to drive progress and in the end ship higher merchandise for our prospects, who stay our high precedence.
NVIDIA
The NVIDIA accelerated computing platform confirmed distinctive efficiency in MLPerf Coaching v4.0. The NVIDIA Eos AI SuperPOD greater than tripled efficiency on the LLM pretraining benchmark, primarily based on GPT-3 175B, in comparison with NVIDIA submissions from a yr in the past. That includes 11,616 NVIDIA H100 Tensor Core GPUs linked with NVIDIA Quantum-2 InfiniBand networking, Eos achieved this by way of bigger scale and intensive full-stack engineering. Moreover, NVIDIA’s 512 H100 GPU submissions are actually 27% sooner in contrast with only one yr in the past resulting from quite a few optimizations to the NVIDIA software program stack.
As enterprises search to customise pretrained giant language fashions, LLM fine-tuning is changing into a key {industry} workload. MLPerf added to this spherical the brand new LLM fine-tuning benchmark, which relies on the favored low-rank adaptation (LoRA) method utilized to Llama 2 70B. The NVIDIA platform excelled at this job, scaling from eight to 1,024 GPUs. And, in its MLPerf Coaching debut, the NVIDIA H200 Tensor Core GPU prolonged H100’s efficiency by 14%.
NVIDIA additionally accelerated Secure Diffusion v2 coaching efficiency by as much as 80% on the similar system scales submitted final spherical. These advances replicate quite a few enhancements to the NVIDIA software program stack. And, on the brand new graph neural community (GNN) take a look at primarily based on RGAT, the NVIDIA platform with H100 GPUs excelled at each small and enormous scales. H200 additional accelerated single-node GNN coaching, delivering a 47% increase in comparison with H100.
Reflecting the breadth of the NVIDIA AI ecosystem, 10 NVIDIA companions submitted spectacular outcomes, together with ASUSTek, Dell, Fujitsu, GigaComputing, HPE, Lenovo, Oracle, Quanta Cloud Know-how, Supermicro, and Sustainable Steel Cloud.
MLCommons’ ongoing work to deliver benchmarking greatest practices to AI computing is important. By way of enabling peer-reviewed, apples-to-apples comparisons of AI and HPC platforms, and protecting tempo with the speedy change that characterizes AI computing, MLCommons supplies firms in all places with essential information that may assist information essential buying selections.
Oracle
Oracle Cloud Infrastructure (OCI) gives AI Infrastructure, Generative AI, AI Companies, ML Companies, and AI in our Fusion Functions. Our AI infrastructure portfolio contains naked metallic situations powered by NVIDIA H100, NVIDIA A100, and NVIDIA A10 GPUs. OCI additionally supplies digital machines powered by NVIDIA A10 GPUs. By mid-2024, we plan so as to add NVIDIA L40S GPU and NVIDIA GH200 Grace Hopper Superchip.
The MLPerf Coaching benchmark outcomes for the high-end BM.GPU.H100.8 occasion show that OCI supplies excessive efficiency that at the least matches that of different deployments for each on-premises and cloud infrastructure. These situations present eight NVIDIA GPUs per node and the coaching efficiency is elevated manifold resulting from RoCEv2 enabling environment friendly NCCL communications. The benchmarks have been accomplished on 1 Node, 8 Node and 16 Node clusters which correspond to eight, 64, 128 NVIDIA H100 GPUs and linear scaling was noticed for the benchmarks as we scale from 1 node to 16 nodes. The GPUs are RAIL optimized. The GPU Nodes with H100 GPUs could be clustered utilizing a excessive efficiency RDMA community for a cluster of tens of 1000’s of GPUs.
Quanta Cloud Know-how
Quanta Cloud Know-how (QCT), a worldwide chief in information middle options, excels in enabling HPC and AI workloads. Within the newest MLPerf Coaching v4.0, QCT demonstrated its dedication to excellence by submitting two programs within the closed division. These submissions lined duties in picture classification, object detection, pure language processing, LLM, advice, picture era, and graph neural community. Each the QuantaGrid D54U-3U and QuantaGrid D74H-7U programs efficiently met stringent high quality targets.
The QuantaGrid D74H-7U is a twin Intel Xeon Scalable Processor server with eight-way GPUs, that includes the NVIDIA HGX H100 SXM5 module, supporting non-blocking GPUDirect RDMA and GPUDirect Storage. This makes it an excellent selection for compute-intensive AI coaching. Its revolutionary {hardware} design and software program optimization guarantee top-tier efficiency.
The QuantaGrid D54U-3U is a flexible 3U system that accommodates as much as 4 dual-width or eight single-width accelerators, together with twin Intel Xeon Scalable Processors and 32 DIMM slots. This versatile structure is tailor-made to optimize varied AI/HPC purposes. Configured with 4 NVIDIA H100-PCIe 80GB accelerators with NVLink bridge adapters, it achieved excellent efficiency on this spherical.
QCT is dedicated to offering complete {hardware} programs, options, and providers to each educational and industrial customers. We keep transparency by overtly sharing our MLPerf outcomes with the general public, masking each coaching and inference benchmarks.
Crimson Hat + Supermicro
Supermicro, builder of Giant-Scale AI Information Heart Infrastructure, and Crimson Hat Inc, the world’s main supplier of enterprise open supply options, collaborated on this primary ever MLPerf Coaching benchmark that included finetuning of LLM llama-2-70b utilizing LoRA.
GPU A+ Server, the AS-4125GS-TNRT has versatile GPU help and configuration choices: with energetic & passive GPUs, and dual-root or single-root configurations for as much as 10 double-width, full-length GPUs. Moreover, the dual-root configuration options instantly hooked up eight GPUs with out PLX switches to attain the bottom latency doable and enhance efficiency, which is vastly useful for demanding eventualities our prospects face with AI and HPC workloads.
This submission demonstrates the supply of efficiency, inside the error bar of different submissions on related {hardware}, whereas offering an distinctive Developer, Consumer and DevOps expertise.
Get entry to a free 60 day trial of Crimson Hat OpenShift AI right here.
Sustainable Steel Cloud (SMC)
Sustainable Steel Cloud, one of many latest members of ML Commons, is an AI GPU cloud developed by Singapore primarily based Firmus Applied sciences utilizing its proprietary single-phase immersion platform, named “Sustainable AI Factories”. Sustainable Steel Cloud’s operations are based in Asia, with a globally increasing community of scaled GPU clusters and infrastructure – together with NVIDIA H100 SXM accelerators.
Our first revealed MLPerf outcomes show that when our prospects prepare their fashions utilizing our GPU cloud service, they entry world-class efficiency with considerably decreased power consumption. Our GPT-3 175B, 512 H100 GPU submission consumed solely 468 kWh of complete power when linked with NVIDIA Quantum-2 Infiniband networking, demonstrating vital power financial savings over typical air-cooled infrastructure.
We’re devoted to advancing the agenda of power effectivity in operating and coaching AI. Our outcomes, verified by MLCommons, spotlight our dedication to this objective. We’re very happy with our GPT3-175B complete energy outcome proving our resolution scales and considerably reduces total energy use. The numerous discount in power consumption is primarily as a result of distinctive design of our Sustainable AI Factories.
With AI’s speedy progress, it’s essential to handle useful resource consumption by focusing alternatives to cut back power utilization in each aspect of the AI Manufacturing facility. Estimates place the power necessities of latest AI succesful information facilities at between 5-8GWh yearly; probably exceeding the US’s projected new energy era capability of 3-5GWh per yr.
As a part of ML Commons, we intention to showcase progressive applied sciences, set benchmarks for greatest practices, and advocate for long-term energy-saving initiatives.
tiny corp
Within the newest spherical of MLPerf Coaching v4.0 (closed division) benchmarks, tiny corp submitted benchmarks for ResNet50. We’re proud to be the primary to undergo MLPerf Coaching on AMD accelerators.
Our outcomes present aggressive efficiency between each AMD accelerators and NVIDIA accelerators, widening the selection for customers to pick the most effective accelerator, decreasing the barrier to entry for prime efficiency machine studying.
This was all achieved with tinygrad, a from scratch, backend agnostic, neural community library that simplifies neural networks down to some fundamental operations, that may then be extremely optimized for varied {hardware} accelerators.
tiny corp will proceed to push the envelope on machine studying efficiency, with a deal with democratizing entry to excessive efficiency compute.
Associated

/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



