Synthetic Intelligence is present process speedy evolution, particularly relating to the coaching of huge language fashions (LLMs) with parameters exceeding 70 billion. These fashions have turn into indispensable for numerous duties, together with artistic textual content era, translation, and content material creation. Nevertheless, successfully harnessing the ability of such superior LLMs requires human enter via a method referred to as Reinforcement Studying from Human Suggestions (RLHF). The primary problem arises from present RLHF frameworks struggling to deal with the immense reminiscence necessities of dealing with these colossal fashions, thereby limiting their full potential.
Present RLHF approaches usually contain dividing the LLM throughout a number of GPUs for coaching, however this technique is just not with out its drawbacks. Firstly, extreme partitioning can result in reminiscence fragmentation on particular person GPUs, leading to a diminished efficient batch dimension for coaching and thus slowing down the general course of. Secondly, the communication overhead between the fragmented components creates bottlenecks, analogous to a workforce continuously exchanging messages, which in the end hinders effectivity.
In response to those challenges, researchers suggest a groundbreaking RLHF framework named OpenRLHF. OpenRLHF leverages two key applied sciences: Ray, the Distributed Job Scheduler, and vLLM, the Distributed Inference Engine. Ray capabilities as a complicated challenge supervisor, intelligently allocating the LLM throughout GPUs with out extreme partitioning, thereby optimizing reminiscence utilization and accelerating coaching by enabling bigger batch sizes per GPU. Conversely, vLLM enhances computation velocity by leveraging the parallel processing capabilities of a number of GPUs, akin to a community of high-performance computer systems collaborating on a fancy downside.
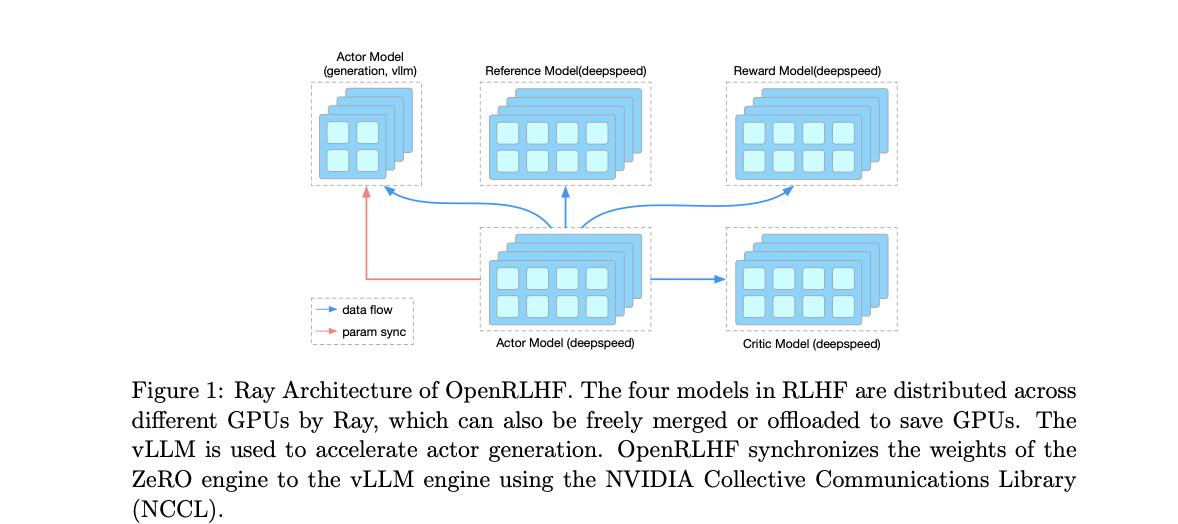
An in depth comparative evaluation with a longtime framework like DSChat, performed in the course of the coaching of a large 7B parameter LLaMA2 mannequin, demonstrated important enhancements with OpenRLHF. It achieved sooner coaching convergence, akin to a pupil greedy an idea shortly attributable to a extra environment friendly studying strategy. Furthermore, vLLM’s speedy era capabilities led to a considerable discount in total coaching time, akin to a producing plant boosting manufacturing velocity with a streamlined meeting line. Moreover, Ray’s clever scheduling minimized reminiscence fragmentation, permitting for bigger batch sizes and sooner coaching.
In conclusion, OpenRLHF’s breakthrough not solely addresses however dismantles the important thing roadblocks encountered in coaching colossal LLMs utilizing RLHF. By harnessing the ability of environment friendly scheduling and accelerated computations, it overcomes reminiscence limitations and achieves sooner coaching convergence. This opens up avenues for fine-tuning even bigger LLMs with human suggestions, heralding a brand new period of purposes in language processing and knowledge interplay that may probably revolutionize numerous domains.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 42k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.