


Machine studying has seen vital developments, with Transformers rising as a dominant structure in language modeling. These fashions have revolutionized pure language processing by enabling machines to grasp and generate human language precisely. The effectivity and scalability of those fashions stay a big problem, significantly as a result of quadratic scaling of conventional consideration mechanisms with the sequence size. Researchers intention to deal with this by exploring various strategies to take care of efficiency whereas enhancing effectivity.
A key problem on this subject is to enhance the effectivity and scalability of those fashions. Conventional consideration mechanisms utilized in Transformers scale quadratically with the sequence size, posing limitations for lengthy sequences. Researchers intention to deal with this by exploring various strategies to take care of efficiency whereas enhancing effectivity. One such problem is the numerous computational demand and reminiscence utilization related to conventional consideration mechanisms, which restricts the efficient dealing with of longer sequences.
Current work contains Structured State Area Fashions (SSMs), which supply linear scaling throughout coaching and fixed state measurement throughout technology, making them appropriate for long-range duties. Nonetheless, integrating these fashions into present deep-learning frameworks stays difficult as a result of their distinctive construction and optimization necessities. SSMs have demonstrated robust efficiency in duties requiring long-range dependencies however want assist in integration and optimization inside established deep-learning frameworks.
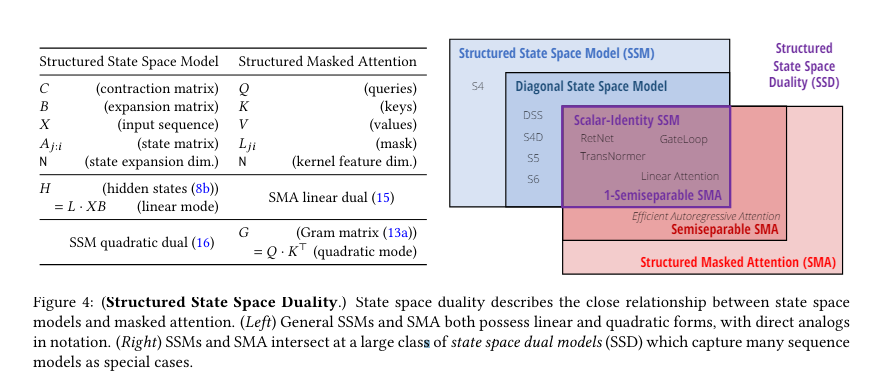
Researchers from Princeton College and Carnegie Mellon College have launched the State Area Duality (SSD) framework, which connects SSMs and a focus mechanisms. This new structure, Mamba-2, refines the selective SSM, attaining speeds 2-8 occasions sooner than its predecessor whereas sustaining aggressive efficiency with Transformers. Mamba-2 leverages the effectivity of matrix multiplication models in fashionable {hardware} to optimize coaching and inference processes. The SSD framework permits the exploitation of specialised matrix multiplication models, considerably enhancing computation speeds and effectivity.
The core of Mamba-2’s design entails a sequence of environment friendly algorithms that exploit the construction of semi separable matrices. These matrices enable optimum computing, reminiscence utilization, and scalability trade-offs, considerably enhancing the mannequin’s efficiency. The analysis crew employed a wide range of methods to refine Mamba-2, together with the usage of matrix multiplication models on GPUs, that are referred to as tensor cores. These tensor cores considerably pace up the computation course of. Moreover, to enhance effectivity, the mannequin integrates grouped-value consideration and tensor parallelism, methods borrowed from Transformer optimizations. The Mamba-2 structure additionally makes use of selective SSMs, which may dynamically select to deal with or ignore inputs at each timestep, permitting for higher data retention and processing. The coaching setup follows the GPT-3 specs, utilizing the Pile dataset and adhering to the coaching recipes from prior fashions. These improvements collectively make sure that Mamba-2 balances computational and reminiscence effectivity whereas sustaining excessive efficiency, making it a sturdy instrument for language modeling duties.
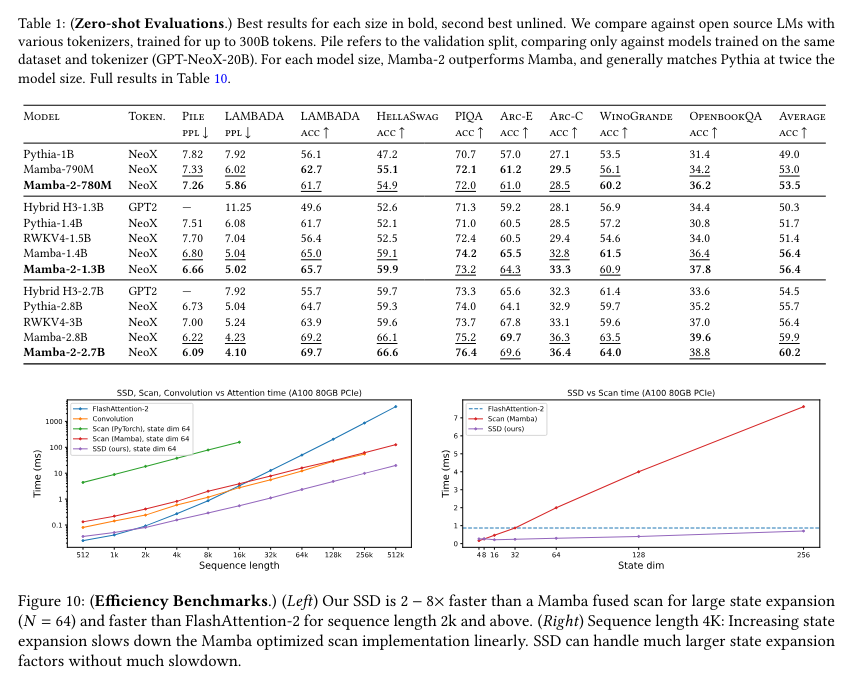
The efficiency of Mamba-2 is validated by varied benchmarks, demonstrating its superiority over earlier fashions. It achieves higher perplexity and wall-clock time, making it a sturdy various for language modeling duties. As an example, Mamba-2, with 2.7B parameters educated on 300B tokens, outperforms its predecessor and different fashions like Pythia-2.8B and Pythia-6.9B on normal downstream evaluations. The mannequin achieves notable outcomes, together with decrease perplexity scores and sooner coaching occasions, validating its effectiveness in real-world functions.
When it comes to particular efficiency metrics, Mamba-2 exhibits vital enhancements. It achieves a perplexity rating 6.09 on the Pile dataset, in comparison with 6.13 for the unique Mamba mannequin. Furthermore, Mamba-2 reveals sooner coaching occasions, being 2-8 occasions faster as a result of its environment friendly use of tensor cores for matrix multiplication. These outcomes spotlight the mannequin’s effectivity in dealing with large-scale language duties, making it a promising instrument for future developments in pure language processing.
In conclusion, the analysis introduces an modern technique that bridges the hole between SSMs and a focus mechanisms, providing a scalable and environment friendly answer for language modeling. This development not solely enhances efficiency but additionally paves the way in which for future developments within the subject. Introducing the SSD framework and the Mamba-2 structure offers a promising course for overcoming the restrictions of conventional consideration mechanisms in Transformers.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to hitch our 43k+ ML SubReddit | Additionally, try our AI Occasions Platform
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.






