


Inside multimedia and communication contexts, the human face serves as a dynamic medium able to expressing feelings and fostering connections. AI-generated speaking faces symbolize an development with potential implications throughout varied domains. These embrace enhancing digital communication, bettering accessibility for people with communicative impairments, revolutionizing schooling via AI tutoring, and providing therapeutic and social assist in healthcare settings. This know-how stands to complement human-AI interactions and reshape numerous fields.
Quite a few approaches have emerged for creating speaking faces from audio, but present strategies fall wanting attaining the authenticity of pure speech. Whereas lip synchronization accuracy has improved, expressive facial dynamics and lifelike nuances obtain insufficient consideration, leading to inflexible and unconvincing generated faces. Although some research handle practical head motions, a big disparity persists in comparison with human motion patterns. Additionally, era effectivity is essential for real-time functions, however computational calls for hinder practicality. Bridging this hole requires optimized algorithms balancing high-quality synthesis and low-latency calls for for interactive programs.
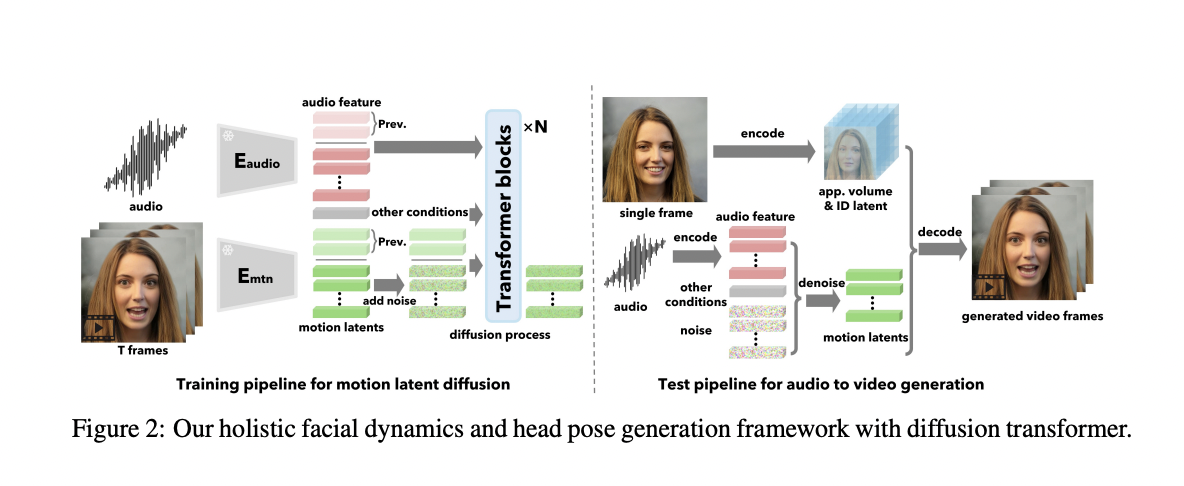
Microsoft researchers introduce VASA, a framework for producing lifelike speaking faces endowed with interesting visible affective abilities (VAS) from a static picture and a speech audio clip. Their premier mannequin, VASA-1, achieves exact lip synchronization and captures a broad vary of facial nuances and pure head actions, enhancing authenticity and liveliness. Key improvements embrace a diffusion-based mannequin for holistic facial dynamics and head motion era inside a face latent house, developed utilizing expressive and disentangled face latent house from movies.
VASA goals to generate lifelike movies of a given face talking with offered audio. It emphasizes clear picture frames, exact lip sync, expressive facial dynamics, and pure head poses. Elective management indicators information era. Holistic facial dynamics and head movement are generated in a latent house conditioned on audio. A face latent house is constructed, and diffusion transformers are utilized for movement era. Conditioning indicators like audio options and gaze course improve controllability. At inference, look and identification options are extracted, and movement sequences are generated to supply the ultimate video.
The researchers in contrast LISA with current audio-driven speaking face era strategies: MakeItTalk, Audio2Head, and SadTalker. Outcomes reveal the superior efficiency of LISA throughout metrics on VoxCeleb2 and OneMin-32 benchmarks. Their methodology achieved larger audio-lip synchronization, superior pose alignment, and decrease Frechet Video Distance (FVD), indicating larger high quality and realism than current strategies and even actual movies.

To sum up, Microsoft researchers current VASA-1. This audio-driven speaking face era mannequin effectively produces practical lip synchronization, expressive facial dynamics, and pure head actions from a single picture and audio enter. It surpasses current video high quality and efficiency effectivity strategies, showcasing promising visible affective abilities in generated face movies. The important thing innovation lies in a holistic facial dynamics and head motion era mannequin working inside an expressive and disentangled face latent house. These developments can remodel human-human and human-AI interactions in communication, schooling, and healthcare.
Try the Paper and Mission. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Neglect to hitch our 40k+ ML SubReddit
For Content material Partnership, Please Fill Out This Type Right here..
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.
/cdn.vox-cdn.com/uploads/chorus_asset/file/25385148/Mario_Kart_8_Deluxe_Booster_Course_Pass.jpg)



/cdn.vox-cdn.com/uploads/chorus_asset/file/25547597/Screen_Shot_2024_07_26_at_3.55.30_PM.png)
