

As prospects search to include their corpus of information into their generative synthetic intelligence (AI) functions, or to construct domain-specific fashions, their knowledge science groups usually need to conduct A/B testing and have repeatable experiments. On this put up, we talk about an answer that makes use of infrastructure as code (IaC) to outline the method of retrieving and formatting knowledge for mannequin customization and initiating the mannequin customization. This lets you model and iterate as wanted.
With Amazon Bedrock, you may privately and securely customise basis fashions (FMs) with your personal knowledge to construct functions which might be particular to your area, group, and use case. With customized fashions, you may create distinctive consumer experiences that replicate your organization’s model, voice, and providers.
Amazon Bedrock helps two strategies of mannequin customization:
- Effective-tuning permits you to improve mannequin accuracy by offering your personal task-specific labeled coaching dataset and additional specialize your FMs.
- Continued pre-training permits you to prepare fashions utilizing your personal unlabeled knowledge in a safe and managed atmosphere and helps customer-managed keys. Continued pre-training helps fashions turn out to be extra domain-specific by accumulating extra sturdy information and flexibility—past their unique coaching.
On this put up, we offer steerage on find out how to create an Amazon Bedrock customized mannequin utilizing HashiCorp Terraform that permits you to automate the method, together with making ready datasets used for personalisation.
Terraform is an IaC software that permits you to handle AWS sources, software program as a service (SaaS) sources, datasets, and extra, utilizing declarative configuration. Terraform gives the advantages of automation, versioning, and repeatability.
Answer overview
We use Terraform to obtain a public dataset from the Hugging Face Hub, convert it to JSONL format, and add it to an Amazon Easy Storage Service (Amazon S3) bucket with a versioned prefix. We then create an Amazon Bedrock customized mannequin utilizing fine-tuning, and create a second mannequin utilizing continued pre-training. Lastly, we configure Provisioned Throughput for our new fashions so we will check and deploy the customized fashions for wider utilization.
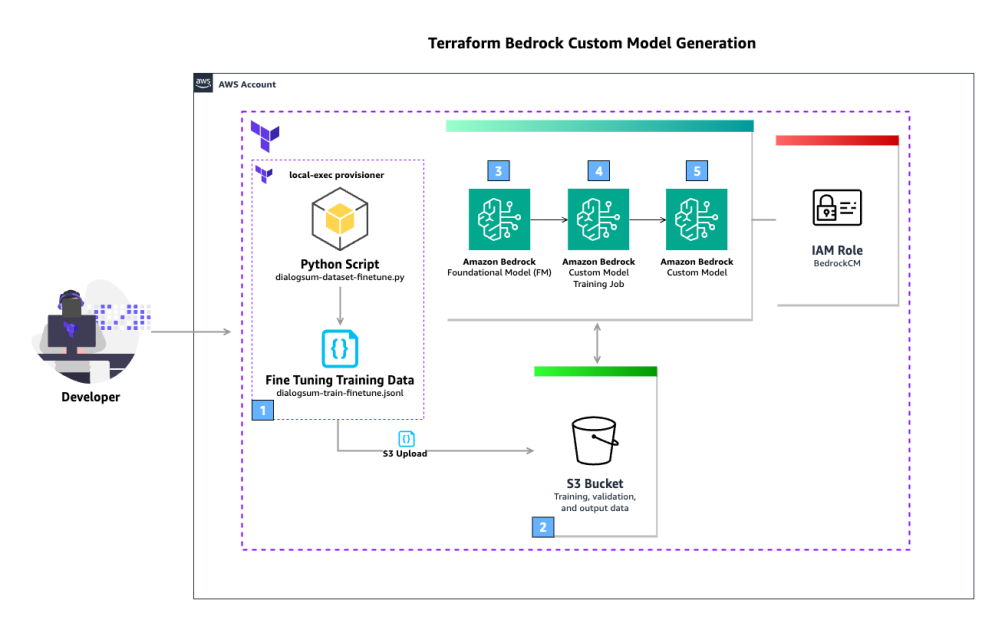
The next diagram illustrates the answer structure.
The workflow contains the next steps:
- The consumer runs the
terraform applyThe Terraformlocal-execprovisioner is used to run a Python script that downloads the general public dataset DialogSum from the Hugging Face Hub. That is then used to create a fine-tuning coaching JSONL file. - An S3 bucket shops coaching, validation, and output knowledge. The generated JSONL file is uploaded to the S3 bucket.
- The FM outlined within the Terraform configuration is used because the supply for the customized mannequin coaching job.
- The customized mannequin coaching job makes use of the fine-tuning coaching knowledge saved within the S3 bucket to complement the FM. Amazon Bedrock is ready to entry the info within the S3 bucket (together with output knowledge) because of the AWS Identification and Entry Administration (IAM) position outlined within the Terraform configuration, which grants entry to the S3 bucket.
- When the customized mannequin coaching job is full, the brand new customized mannequin is out there to be used.
The high-level steps to implement this resolution are as follows:
- Create and initialize a Terraform venture.
- Create knowledge sources for context lookup.
- Create an S3 bucket to retailer coaching, validation, and output knowledge.
- Create an IAM service position that permits Amazon Bedrock to run a mannequin customization job, entry your coaching and validation knowledge, and write your output knowledge to your S3 bucket.
- Configure your native Python digital atmosphere.
- Obtain the DialogSum public dataset and convert it to JSONL.
- Add the transformed dataset to Amazon S3.
- Create an Amazon Bedrock customized mannequin utilizing fine-tuning.
- Configure customized mannequin Provisioned Throughput in your fashions.
Stipulations
This resolution requires the next conditions:
Create and initialize a Terraform venture
Full the next steps to create a brand new Terraform venture and initialize it. You’ll be able to work in a neighborhood folder of your selecting.
- In your most well-liked terminal, create a brand new folder named
bedrockcmand alter to that folder:- If on Home windows, use the next code:
- If on Mac or Linux, use the next code:
Now you may work in a textual content editor and enter in code.
- In your most well-liked textual content editor, add a brand new file with the next Terraform code:
- Save the file within the root of the
bedrockcmfolder and title itforemost.tf. - In your terminal, run the next command to initialize the Terraform working listing:
The output will include a profitable message like the next:
“Terraform has been efficiently initialized”
- In your terminal, validate the syntax in your Terraform recordsdata:
Create knowledge sources for context lookup
The subsequent step is so as to add configurations that outline knowledge sources that lookup details about the context Terraform is at present working in. These knowledge sources are used when defining the IAM position and insurance policies and when creating the S3 bucket. Extra data will be discovered within the Terraform documentation for aws_caller_identity, aws_partition, and aws_region.
- In your textual content editor, add the next Terraform code to your
foremost.tffile:
- Save the file.
Create an S3 bucket
On this step, you utilize Terraform to create an S3 bucket to make use of throughout mannequin customization and related outputs. S3 bucket names are globally distinctive, so you utilize the Terraform knowledge supply aws_caller_identity, which lets you lookup the present AWS account ID, and use string interpolation to incorporate the account ID within the bucket title. Full the next steps:
- Add the next Terraform code to your
foremost.tffile:
- Save the file.
Create an IAM service position for Amazon Bedrock
Now you create the service position that Amazon Bedrock will assume to function the mannequin customization jobs.
You first create a coverage doc, assume_role_policy, which defines the belief relationship for the IAM position. The coverage permits the bedrock.amazonaws.com service to imagine this position. You employ international situation context keys for cross-service confused deputy prevention. There are additionally two circumstances you specify: the supply account should match the present account, and the supply ARN have to be an Amazon Bedrock mannequin customization job working from the present partition, AWS Area, and present account.
Full the next steps:
- Add the next Terraform code to your
foremost.tffile:
The second coverage doc, bedrock_custom_policy, defines permissions for accessing the S3 bucket you created for mannequin coaching, validation, and output. The coverage permits the actions GetObject, PutObject, and ListBucket on the sources specified, that are the ARN of the model_training S3 bucket and the entire buckets contents. You’ll then create an aws_iam_policy useful resource, which creates the coverage in AWS.
- Add the next Terraform code to your
foremost.tffile:
Lastly, the aws_iam_role useful resource, bedrock_custom_role, creates an IAM position with a reputation prefix of BedrockCM- and an outline. The position makes use of assume_role_policy as its belief coverage and bedrock_custom_policy as a managed coverage to permit the actions specified.
- Add the next Terraform code to your
foremost.tffile:
- Save the file.
Configure your native Python digital atmosphere
Python helps creating light-weight digital environments, every with their very own unbiased set of Python packages put in. You create and activate a digital atmosphere, after which set up the datasets bundle.
- In your terminal, within the root of the
bedrockcmfolder, run the next command to create a digital atmosphere:
- Activate the digital atmosphere:
- If on Home windows, use the next command:
- If on Mac or Linux, use the next command:
Now you put in the datasets bundle by way of pip.
- In your terminal, run the next command to put in the datasets bundle:
Obtain the general public dataset
You now use Terraform’s local-exec provisioner to invoke a neighborhood Python script that may obtain the general public dataset DialogSum from the Hugging Face Hub. The dataset is already divided into coaching, validation, and testing splits. This instance makes use of simply the coaching break up.
You put together the info for coaching by eradicating the id and subject columns, renaming the dialogue and abstract columns, and truncating the dataset to 10,000 information. You then save the dataset in JSONL format. You might additionally use your personal inside personal datasets; we use a public dataset for instance functions.
You first create the native Python script named dialogsum-dataset-finetune.py, which is used to obtain the dataset and put it aside to disk.
- In your textual content editor, add a brand new file with the next Python code:
- Save the file within the root of the
bedrockcmfolder and title itdialogsum-dataset-finetune.py.
Subsequent, you edit the foremost.tf file you have got been working in and add the terraform_data useful resource kind, makes use of a neighborhood provisioner to invoke your Python script.
- In your textual content editor, edit the
foremost.tffile and add the next Terraform code:
Add the transformed dataset to Amazon S3
Terraform gives the aws_s3_object useful resource kind, which lets you create and handle objects in S3 buckets. On this step, you reference the S3 bucket you created earlier and the terraform_data useful resource’s output attribute. This output attribute is the way you instruct the Terraform useful resource graph that these sources must be created with a dependency order.
- In your textual content editor, edit the
foremost.tffile and add the next Terraform code:
Create an Amazon Bedrock customized mannequin utilizing fine-tuning
Amazon Bedrock has a number of FMs that help customization with fine-tuning. To see a listing of the fashions out there, use the next AWS Command Line Interface (AWS CLI) command:
- In your terminal, run the next command to listing the FMs that help customization by fine-tuning:
You employ the Cohere Command-Gentle FM for this mannequin customization. You add a Terraform knowledge supply to question the inspiration mannequin ARN utilizing the mannequin title. You then create the Terraform useful resource definition for aws_bedrock_custom_model, which creates a mannequin customization job, and instantly returns.
The time it takes for mannequin customization is non-deterministic, and relies on the enter parameters, mannequin used, and different elements.
- In your textual content editor, edit the
foremost.tffile and add the next Terraform code:
- Save the file.
Now you utilize Terraform to create the info sources and sources outlined in your foremost.tf file, which can begin a mannequin customization job.
- In your terminal, run the next command to validate the syntax in your Terraform recordsdata:
- Run the next command to apply the configuration you created. Earlier than creating the sources, Terraform will describe all of the sources that will probably be created so you may confirm your configuration:
Terraform will generate a plan and ask you to approve the actions, which can look just like the next code:
- Enter
sureto approve the adjustments.
Terraform will now apply your configuration. This course of runs for a couple of minutes. Right now, your customized mannequin just isn’t but prepared to be used; will probably be in a Coaching state. Look forward to coaching to complete earlier than persevering with. You’ll be able to evaluation the standing on the Amazon Bedrock console on the Customized fashions web page.

When the method is full, you obtain a message like the next:
You can even view the standing on the Amazon Bedrock console.

You’ve now created an Amazon Bedrock customized mannequin utilizing fine-tuning.
Configure customized mannequin Provisioned Throughput
Amazon Bedrock permits you to run inference on customized fashions by buying Provisioned Throughput. This ensures a constant degree of throughput in trade for a time period dedication. You specify the variety of mannequin models wanted to satisfy your utility’s efficiency wants. For evaluating customized fashions initially, you should buy Provisioned Throughput hourly (on-demand) with no long-term dedication. With no dedication, a quota of 1 mannequin unit is out there per Provisioned Throughput.
You create a brand new useful resource for Provisioned Throughput, affiliate considered one of your customized fashions, and supply a reputation. You omit the commitment_duration attribute to make use of on-demand.
- In your textual content editor, edit the
foremost.tffile and add the next Terraform code:
- Save the file.
Now you utilize Terraform to create the sources outlined in your foremost.tf file.
- In your terminal, run the next command to re-initialize the Terraform working listing:
The output will include a profitable message like the next:
- Validate the syntax in your Terraform recordsdata:
- Run the next command to apply the configuration you created:
Greatest practices and concerns
Be aware the next greatest practices when utilizing this resolution:
- Knowledge and mannequin versioning – You’ll be able to model your datasets and fashions by utilizing model identifiers in your S3 bucket prefixes. This lets you examine mannequin efficacy and outputs. You might even function a brand new mannequin in a shadow deployment in order that your staff can consider the output relative to your fashions being utilized in manufacturing.
- Knowledge privateness and community safety – With Amazon Bedrock, you’re answerable for your knowledge, and all of your inputs and customizations stay personal to your AWS account. Your knowledge, similar to prompts, completions, customized fashions, and knowledge used for fine-tuning or continued pre-training, just isn’t used for service enchancment and isn’t shared with third-party mannequin suppliers. Your knowledge stays within the Area the place the API name is processed. All knowledge is encrypted in transit and at relaxation. You should use AWS PrivateLink to create a personal connection between your VPC and Amazon Bedrock.
- Billing – Amazon Bedrock prices for mannequin customization, storage, and inference. Mannequin customization is charged per tokens processed. That is the variety of tokens within the coaching dataset multiplied by the variety of coaching epochs. An epoch is one full move by way of the coaching knowledge throughout customization. Mannequin storage is charged per thirty days, per mannequin. Inference is charged hourly per mannequin unit utilizing Provisioned Throughput. For detailed pricing data, see Amazon Bedrock Pricing.
- Customized fashions and Provisioned Throughput – Amazon Bedrock permits you to run inference on customized fashions by buying Provisioned Throughput. This ensures a constant degree of throughput in trade for a time period dedication. You specify the variety of mannequin models wanted to satisfy your utility’s efficiency wants. For evaluating customized fashions initially, you should buy Provisioned Throughput hourly with no long-term dedication. With no dedication, a quota of 1 mannequin unit is out there per Provisioned Throughput. You’ll be able to create as much as two Provisioned Throughputs per account.
- Availability – Effective-tuning help on Meta Llama 2, Cohere Command Gentle, and Amazon Titan Textual content FMs is out there as we speak in Areas US East (N. Virginia) and US West (Oregon). Continued pre-training is out there as we speak in public preview in Areas US East (N. Virginia) and US West (Oregon). To be taught extra, go to the Amazon Bedrock Developer Expertise and take a look at Customized fashions.
Clear up
Whenever you now not want the sources created as a part of this put up, clear up these sources to avoid wasting related prices. You’ll be able to clear up the AWS sources created on this put up utilizing Terraform with the terraform destroy command.
First, you could modify the configuration of the S3 bucket within the foremost.tf file to allow power destroy so the contents of the bucket will probably be deleted, so the bucket itself will be deleted. This can take away the entire pattern knowledge contained within the S3 bucket in addition to the bucket itself. Be certain there isn’t a knowledge you need to retain within the bucket earlier than continuing.
- Modify the declaration of your S3 bucket to set the
force_destroyattribute of the S3 bucket:
- Run the terraform apply command to replace the S3 bucket with this new configuration:
- Run the terraform destroy command to delete all sources created as a part of this put up:
Conclusion
On this put up, we demonstrated find out how to create Amazon Bedrock customized fashions utilizing Terraform. We launched GitOps to handle mannequin configuration and knowledge related along with your customized fashions.
We advocate testing the code and examples in your growth atmosphere, and making applicable adjustments as required to make use of them in manufacturing. Think about your mannequin consumption necessities when defining your Provisioned Throughput.
We welcome your suggestions! In case you have questions or solutions, depart them within the feedback part.
In regards to the Authors
 Josh Famestad is a Options Architect at AWS serving to public sector prospects speed up development, add agility, and cut back threat with cloud-based options.
Josh Famestad is a Options Architect at AWS serving to public sector prospects speed up development, add agility, and cut back threat with cloud-based options.
 Kevon Mayers is a Options Architect at AWS. Kevon is a Core Contributor for Terraform and has led a number of Terraform initiatives inside AWS. Previous to becoming a member of AWS, he was working as a DevOps engineer and developer, and earlier than that was working with the GRAMMYs/The Recording Academy as a studio supervisor, music producer, and audio engineer.
Kevon Mayers is a Options Architect at AWS. Kevon is a Core Contributor for Terraform and has led a number of Terraform initiatives inside AWS. Previous to becoming a member of AWS, he was working as a DevOps engineer and developer, and earlier than that was working with the GRAMMYs/The Recording Academy as a studio supervisor, music producer, and audio engineer.
 Tyler Lynch is a Principal Answer Architect at AWS. Tyler leads Terraform supplier engineering at AWS and is a Core Contributor for Terraform.
Tyler Lynch is a Principal Answer Architect at AWS. Tyler leads Terraform supplier engineering at AWS and is a Core Contributor for Terraform.

/cdn.vox-cdn.com/uploads/chorus_asset/file/25451807/DSC07421_processed.jpg)




