

The latest introduction of Massive Language Fashions has taken the world by storm. Now, creativeness is the restrict. Right this moment, WavJourney can automate the artwork of storytelling. Given a single immediate, WavJourney leverages the ability of LLMs to generate greedy audio scripts, full with an correct storyline, lifelike human voices, and fascinating background music.
To correctly view the powers of audio era, think about the next state of affairs. We solely want to offer a easy instruction, describing a state of affairs and scene setting, and the mannequin generates a gripping audio script highlighting the supreme context relevance to the unique instruction.
INSTRUCTION: Generate audio in Science Fiction theme: Mars Information reporting that People ship a light-speed probe to Alpha Centauri. Begin with a information anchor, adopted by a reporter interviewing a chief engineer from a company that constructed this probe, based by United Earth and Mars Authorities, and finish with the information anchor once more.
GENERATED AUDIO: https://audio-agi.github.io/WavJourney_demopage/sci-fi/sci-fipercent20news.mp4
To really perceive the interior workings of this marvel, allow us to dive deep into the methodology and implementation particulars of the era course of.
The picture under summarizes the entire course of in a easy flowchart.
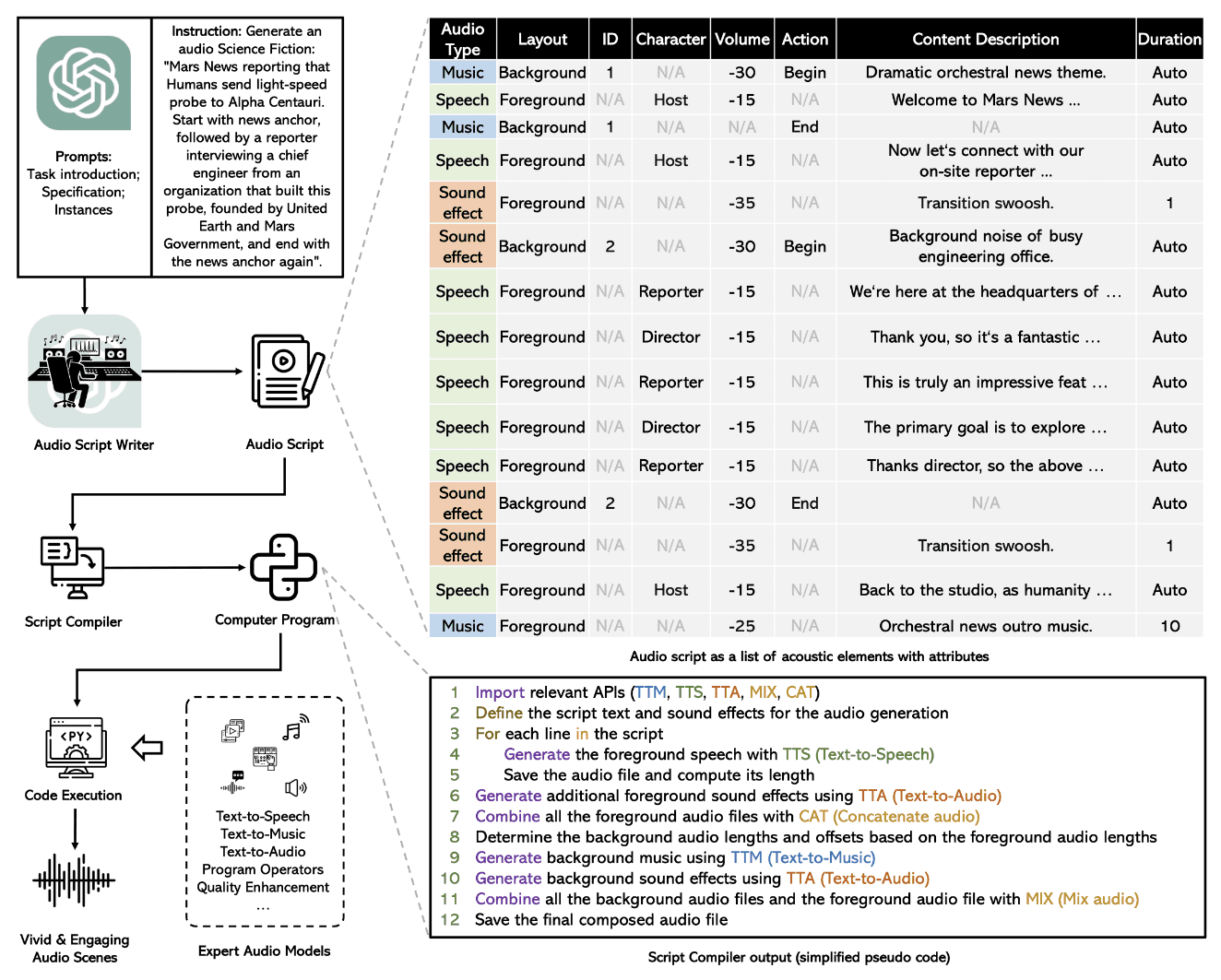
Picture from Paper
The top-to-end audio era course of consists of a number of submodules, which might be executed sequentially for a whole Textual content-to-Audio mannequin.
Audio Script Technology
WavJourney makes use of GPT-4 mannequin with a predefined immediate template to generate the script. The immediate templates limit the output to be in a easy JSON format, that may simply be parsed later by a pc program. Every script has 3 totally different audio varieties as proven within the picture above: Speech, sound results, and music. Every audio kind can then be run as foreground audio, or overlaid as a background sound impact over different audio. Different attributes reminiscent of content material description, size, and character are ample attributes to formally outline an audio setting for script era.
Script Parsing
The output script is then handed via a pc program, that parses the related data from the predefined JSON script format. It associates every description and character to a preset speech audio. This course of helps in breaking down the audio era course of into separate steps, that embrace text-to-speech, music, and sound addition.
Audio Technology
The parsed script is executed as a Python program. Foreground speech is first generated that’s overlaid by background music and sound results. For speech era, the mannequin makes use of the pre-trained Bark mannequin and a VoiceFixer restoration mannequin to enhance audio high quality. AudioLDM and MusicGen fashions are utilized for sound results and music overlays. The outputs of all three fashions are mixed for the ultimate audio output.
The method maintains context of the generated scripts, and may be prompted much like GPT fashions. You possibly can simply modify the generated script utilizing human suggestions and chat capabilities of GPT fashions.
Including particular particulars and sound results couldn’t have been simpler than this.The flowchart under reveals how easy it’s so as to add or modify particular particulars of the generated script.
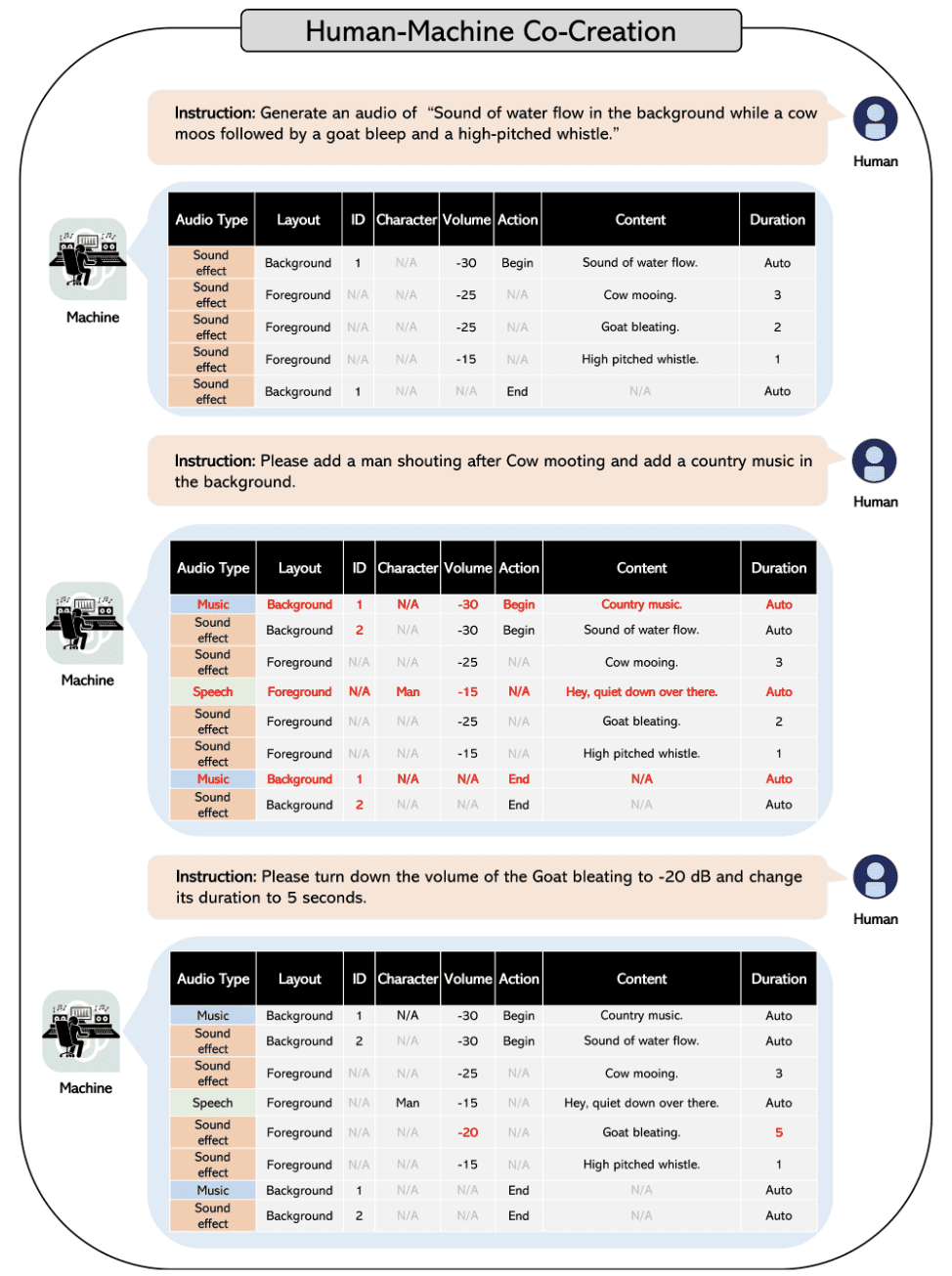
Picture from Paper
The audio era mannequin generally is a game-changer for the leisure trade. The method has the flexibility to generate participating narratives and tales, that may be utilized for academic and leisure functions, automating tedious voice-over and video era processes.
For an in depth understanding, overview the paper right here. The code will quickly be obtainable on GitHub.
Muhammad Arham is a Deep Studying Engineer working in Laptop Imaginative and prescient and Pure Language Processing. He has labored on the deployment and optimizations of a number of generative AI functions that reached the worldwide prime charts at Vyro.AI. He’s concerned with constructing and optimizing machine studying fashions for clever methods and believes in continuous enchancment.


/cdn.vox-cdn.com/uploads/chorus_asset/file/25588208/Megalopolis_Adam_Driver.png)



