


Pure language query understanding has been some of the necessary challenges in synthetic intelligence. Certainly, eminent AI benchmarks such because the Turing take a look at require an AI system to know pure language questions, with numerous matters and complexity, after which reply appropriately. In the course of the previous few years, we’ve witnessed fast progress in query answering expertise, with digital assistants like Siri, Google Now, and Cortana answering day by day life questions, and IBM Watson successful over people in Jeopardy!. Nevertheless, even the perfect query answering programs in the present day nonetheless face two important challenges that must solved concurrently:
-
Query complexity (depth). Many questions the programs encounter are easy lookup questions (e.g., “The place is Chichen Itza?” or “Who’s the supervisor of Man Utd?”). The solutions might be discovered by looking out the floor varieties. However often customers will wish to ask questions that require a number of, non-trivial steps to reply (e.g., “What the most cost effective bus to Chichen Itza leaving tomorrow?” or “What number of occasions did Manchester United attain the ultimate spherical of Premier League whereas Ferguson was the supervisor?”). These questions require deeper understanding and can’t be answered simply by retrieval.
-
Area measurement (breadth). Many programs are skilled or engineered to work very nicely in just a few particular domains similar to managing calendar schedules or discovering eating places. Creating a system to deal with questions in any subject from native climate to world army conflicts, nonetheless, is rather more tough.
Whereas most programs perceive questions containing both depth or breadth alone (e.g., by dealing with advanced questions in just a few domains and fall again to internet search on the remaining), they usually wrestle on ones that require each. To this finish, we’ve determined to create a brand new dataset, WikiTableQuestions, that tackle each challenges on the similar time.
Within the WikiTableQuestions dataset, every query comes with a desk from Wikipedia. Given the query and the desk, the duty is to reply the query based mostly on the desk. The dataset accommodates 2108 tables from a big number of matters (extra breadth) and 22033 questions with totally different complexity (extra depth). Tables within the take a look at set don’t seem within the coaching set, so a system should have the ability to generalize to unseen tables.
The dataset might be accessed from the mission web page or on CodaLab. The coaching set may also be browsed on-line.
We now give some examples that show the challenges of the dataset. Contemplate the next desk:
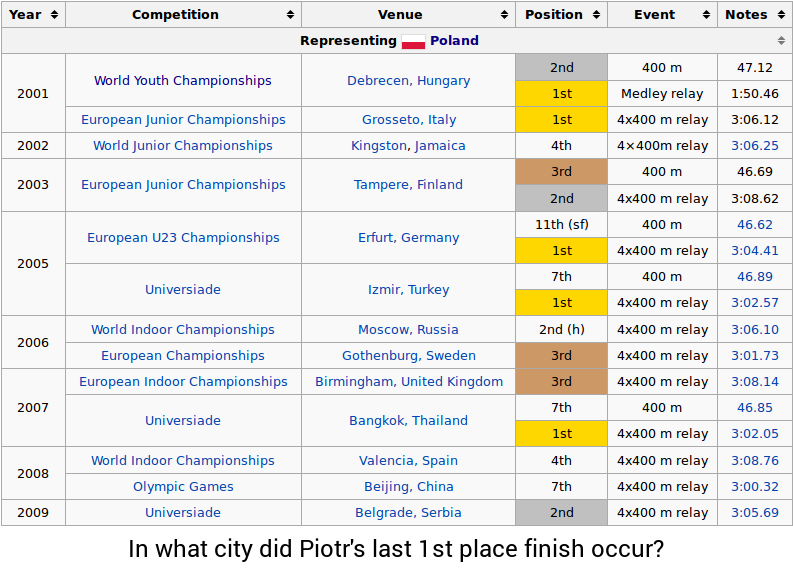
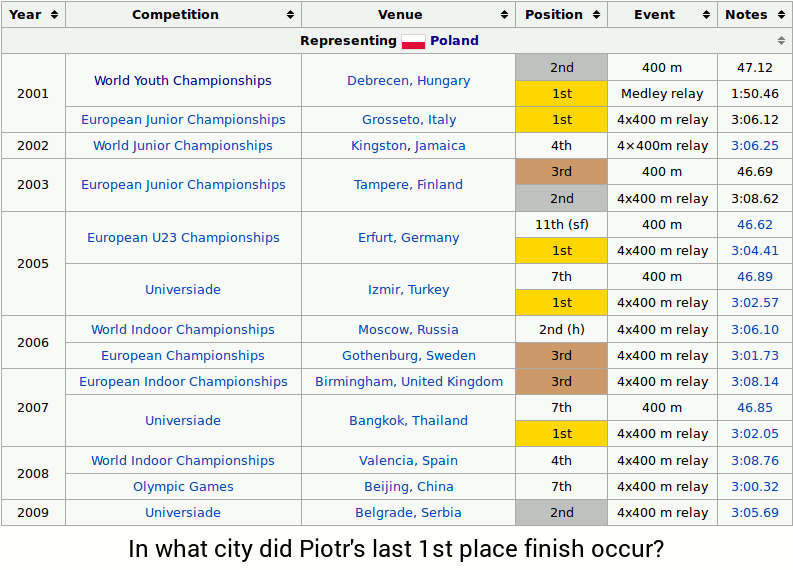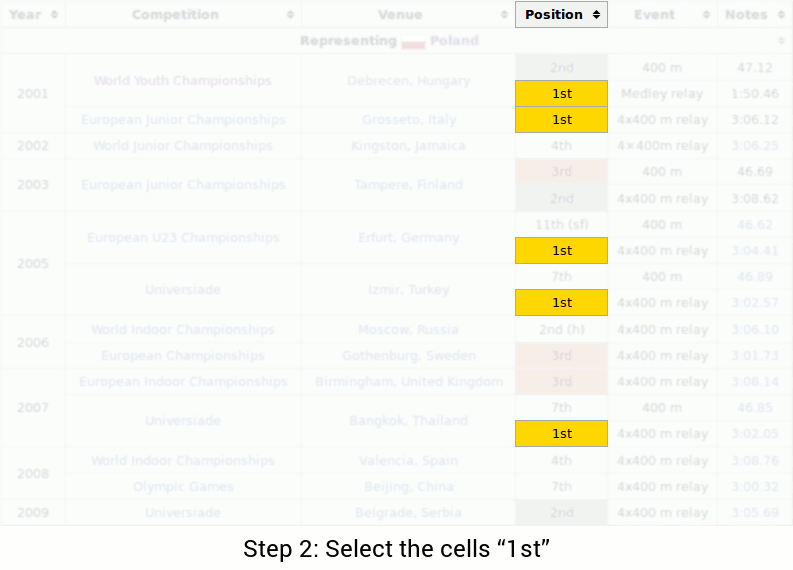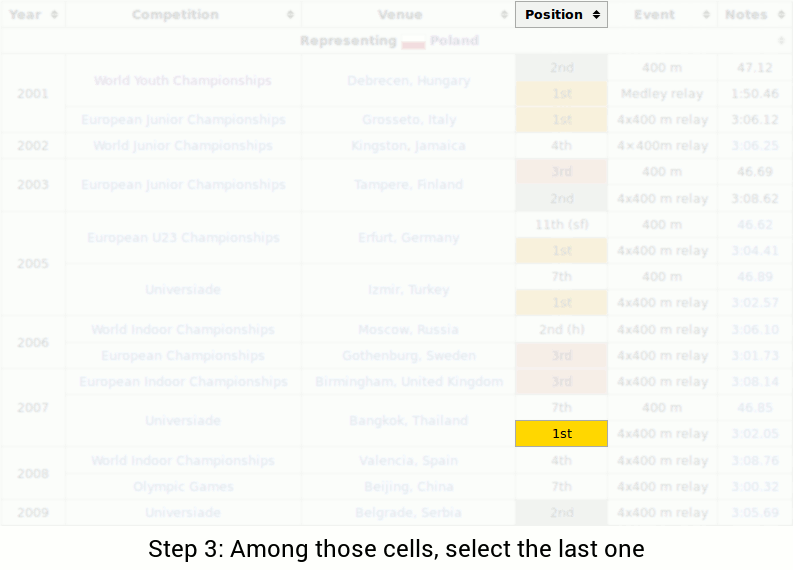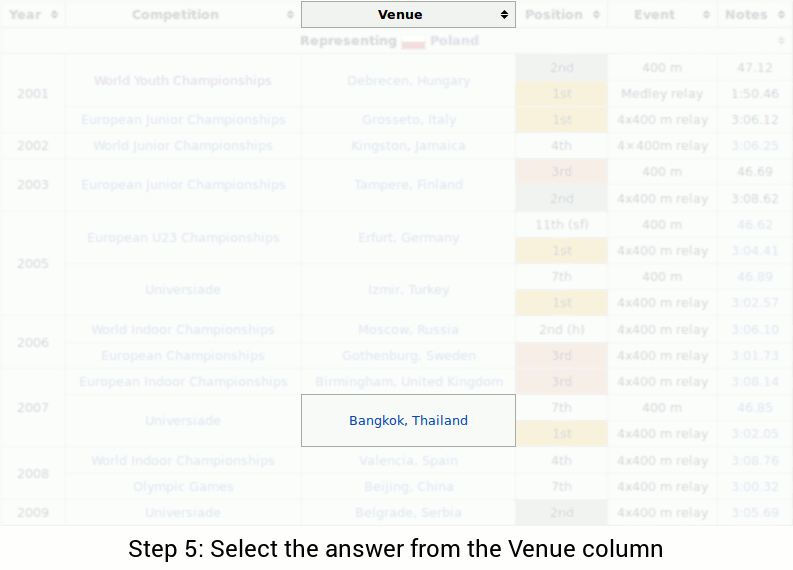
The query is “In what metropolis did Piotr’s final 1st place end happen?” So as to reply the query, one would possibly carry out the next steps:
With this instance, we will observe a number of challenges:
-
Schema mapping. One elementary problem when working with messy real-world knowledge is dealing with numerous and probably unseen knowledge schemas. On this case, the system should know that the phrase “place” refers back to the “Place” column whereas the phrase “metropolis” refers back to the “Venue” column, even when the identical desk schema has not been noticed earlier than throughout coaching.
-
Compositionality. Pure language can specific advanced concepts because of the precept of compositionality: the flexibility to compose smaller phrases into larger ones. Small phrases may correspond to totally different operations (e.g., finding the final merchandise), which might be composed to get the ultimate reply.
-
Number of operations. To completely make the most of a wealthy knowledge supply, it’s important to have the ability to carry out totally different operations similar to filtering knowledge (“1st place”, “in 1990”), pinpointing knowledge (“the longest”, “the primary”), computing statistics (“complete”, “common”, “what number of”), and evaluating portions (“distinction between”, “a minimum of 10”). The WikiTableQuestions dataset accommodates questions with a big number of operations, a few of which might be noticed in different questions for the desk above:
- what was piotr’s complete variety of third place finishes?
- which competitors did this competitor compete in subsequent after the world indoor championships in 2008?
- how lengthy did it take piotr to run the medley relay in 2001?
- which 4×400 was sooner, 2005 or 2003?
- what number of occasions has this competitor positioned fifth or higher in competitors?
- Frequent sense reasoning. Lastly, some of the difficult facet of pure language is that the which means of some phrases should be inferred utilizing the context and customary sense. For example, the phrase “higher” within the final instance (… positioned fifth or higher …) means “Place ≤ 5”, however in “scored 5 or higher” it means “Rating ≥ 5”.
Listed below are another examples (cherry-picked from the primary 50 examples) that present the number of operations and matters of our dataset:
Most QA datasets tackle solely both breadth (area measurement) or depth (query complexity). Early semantic parsing datasets similar to GeoQuery and ATIS include advanced sentences (excessive depth) in a centered area (low breadth). Listed below are some examples from GeoQuery, which accommodates questions on a US geography database:
- what number of states border texas?
- what states border texas and have a significant river?
- what’s the complete inhabitants of the states that border texas?
- what states border states that border states that border states that border texas?
Extra lately, Fb launched the bAbI dataset that includes 20 sorts of mechanically generated questions with totally different complexity on simulated worlds. Right here is an instance:
John picked up the apple.
John went to the workplace.
John went to the kitchen.
John dropped the apple.
Query: The place was the apple earlier than the kitchen?
In distinction, many QA datasets include questions spanning quite a lot of matters (excessive breadth), however the questions are a lot easier or retrieval-based (low depth). For instance, WebQuestions dataset accommodates factoid questions that may be answered utilizing a structured data base. Listed below are some examples:
- what’s the title of justin bieber brother?
- what character did natalie portman play in star wars?
- the place donald trump went to varsity?
- what nations all over the world converse french?
Different data base QA datasets embrace Free917 (additionally on Freebase) and QALD (on each data bases and unstructured knowledge).
QA datasets that target data retrieval and reply choice (similar to TREC, WikiQA, QANTA Quiz Bowl, and plenty of Jeopardy! questions) are additionally of this type: whereas some questions in these datasets look advanced, the solutions might be principally inferred by working with the floor kind. Right here is an instance from QANTA Quiz Bowl dataset:
With the assistence of his chief minister, the Duc de Sully, he lowered taxes on peasantry, promoted financial restoration, and instituted a tax on the Paulette. Victor at Ivry and Arquet, he was excluded from succession by the Treaty of Nemours, however gained an incredible victory at Coutras. His excommunication was lifted by Clement VIII, however that pope later claimed to be crucified when this monarch promulgated the Edict of Nantes. For 10 factors, title this French king, the primary Bourbon who admitted that “Paris is value a mass” when he transformed following the Struggle of the Three Henrys.
Lastly, there are a number of datasets that tackle each breadth and depth however in a unique angle. For instance, QALD Hybrid QA requires the system to mix data from a number of knowledge sources, and in AI2 Science Examination Questions and Todai Robotic College Entrance Questions, the system has to carry out frequent sense reasoning and logical inference on a big quantity of data to derive the solutions.
In our paper, we current a semantic parsing system which learns to assemble formal queries (“logical varieties”) that may be executed on the tables to get the solutions.
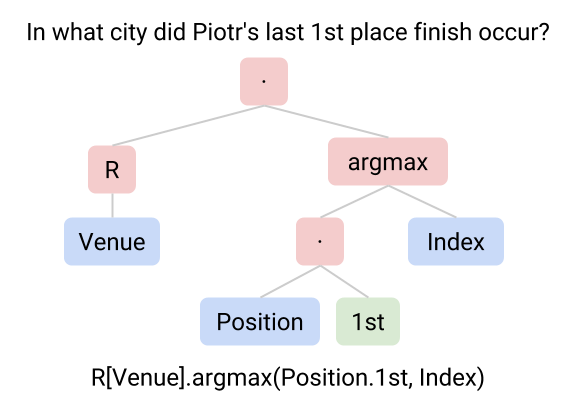
The system learns a statistical mannequin that builds logical varieties in a hierarchical vogue (extra depth) utilizing elements might be freely constructed from any desk schema (extra breadth). The system obtain a take a look at accuracy of 37.1%, which is larger than the earlier semantic parsing system and an data retrieval baseline.
We encourage everybody to play with the dataset, develop programs to sort out the challenges, and advance the sphere of pure language understanding! For solutions and feedback on the dataset, please contact the creator Ice Pasupat.




/cdn.vox-cdn.com/uploads/chorus_asset/file/25547597/Screen_Shot_2024_07_26_at_3.55.30_PM.png)

