


Introduction
In at the moment’s data-driven panorama, companies should combine information from numerous sources to derive actionable insights and make knowledgeable selections. This significant course of, known as Extract, Remodel, Load (ETL), includes extracting information from a number of origins, remodeling it right into a constant format, and loading it right into a goal system for evaluation. With information volumes rising at an unprecedented fee, organizations face vital challenges in sustaining their ETL processes’ pace, accuracy, and scalability. This information delves into methods for optimizing information integration and creating environment friendly ETL workflows.
Studying Goals
- Perceive ETL processes to combine and analyze information from numerous sources successfully.
- Consider and choose applicable ETL instruments and applied sciences for scalability and compatibility.
- Implement parallel information processing to reinforce ETL efficiency utilizing frameworks like Apache Spark.
- Apply incremental loading methods to course of solely new or up to date information effectively.
- Guarantee information high quality by means of profiling, cleaning, and validation inside ETL pipelines.
- Develop sturdy error dealing with and retry mechanisms to take care of ETL course of reliability and information integrity.
This text was printed as part of the Knowledge Science Blogathon.
Understanding Your Knowledge Sources
Earlier than diving into ETL growth, it’s essential to have a complete understanding of your information sources. This contains figuring out the sorts of information sources obtainable, resembling databases, recordsdata, APIs, and streaming sources, and understanding the construction, format, and high quality of the info inside every supply. By gaining insights into your information sources, you may higher plan your ETL technique and anticipate any challenges or complexities that will come up through the integration course of.
Deciding on the suitable instruments and applied sciences is important for constructing environment friendly ETL pipelines. Quite a few ETL instruments and frameworks can be found out there, every providing distinctive options and capabilities. Some widespread choices embody Apache Spark, Apache Airflow, Talend, Informatica, and Microsoft Azure Knowledge Manufacturing facility. When selecting a device, think about scalability, ease of use, integration capabilities, and compatibility together with your current infrastructure. Moreover, consider whether or not the device helps the precise information sources and codecs it’s essential combine.
Parallel Knowledge Processing
One extremely efficient method to improve ETL course of efficiency is by parallelizing information processing duties. This includes dividing these duties into smaller, unbiased items that may run concurrently throughout a number of processors or nodes. By harnessing the ability of distributed methods, parallel processing can dramatically cut back processing time. Apache Spark is a extensively used framework that helps parallel information processing throughout in depth clusters. By partitioning your information and using Spark’s capabilities, you may obtain substantial efficiency features in your ETL workflows.
To run the supplied PySpark script, you could set up the mandatory dependencies. Right here’s a listing of the required dependencies and their set up instructions:
- PySpark: That is the first library for working with Apache Spark in Python.
- Pandas (optionally available if it’s essential manipulate information with Pandas earlier than or after Spark processing).
You possibly can set up these dependencies utilizing pip:
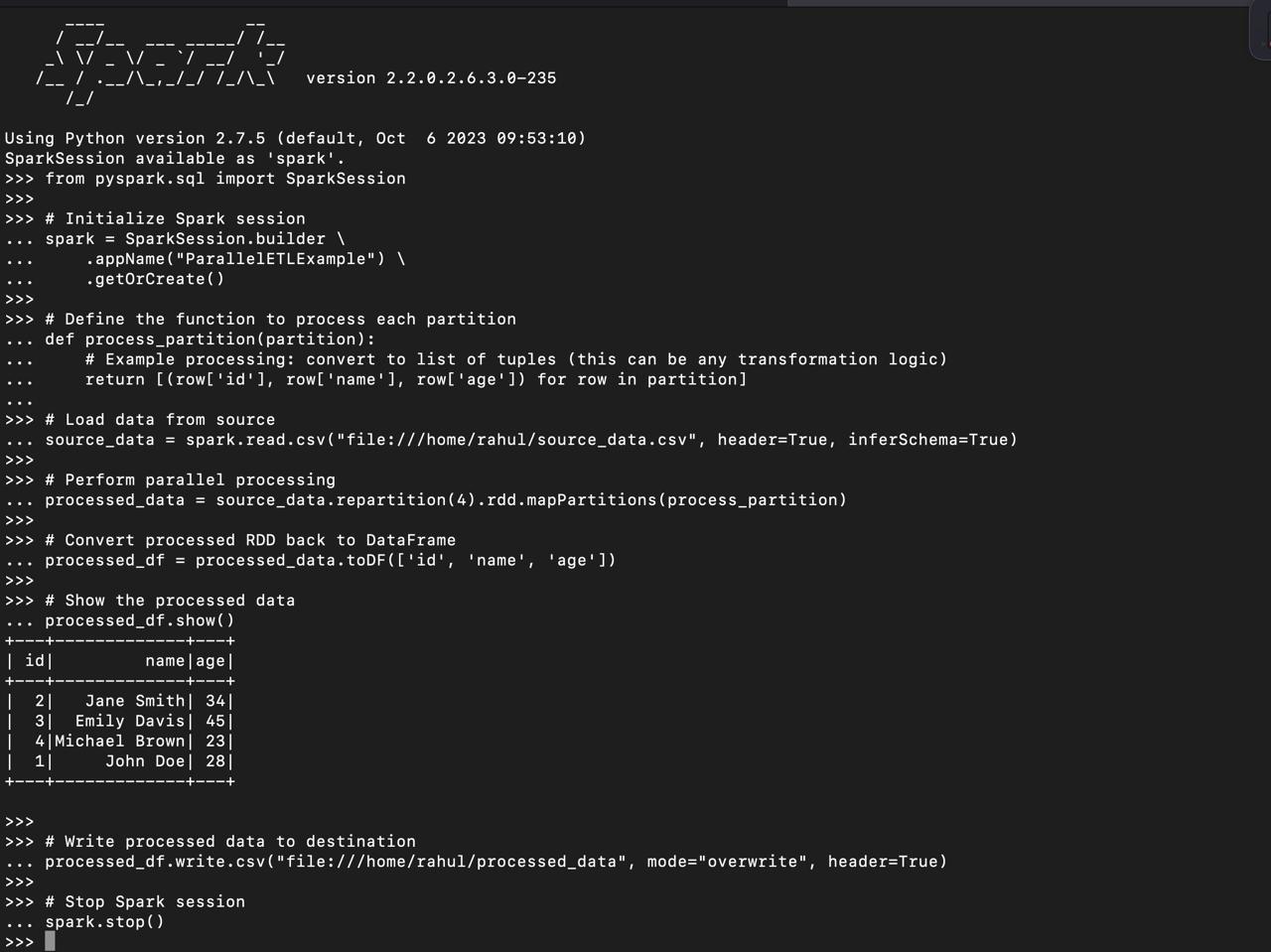
pip set up pyspark pandasfrom pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder
.appName("ParallelETLExample")
.getOrCreate()
# Outline the operate to course of every partition
def process_partition(partition):
# Instance processing: convert to listing of tuples (this may be any transformation logic)
return [(row['id'], row['name'], row['age']) for row in partition]
# Load information from supply
source_data = spark.learn.csv("file:///house/rahul/source_data.csv", header=True, inferSchema=True)
# Carry out parallel processing
processed_data = source_data.repartition(4).rdd.mapPartitions(process_partition)
# Convert processed RDD again to DataFrame
processed_df = processed_data.toDF(['id', 'name', 'age'])
# Present the processed information
processed_df.present()
# Write processed information to vacation spot
processed_df.write.csv("file:///house/rahul/processed_data", mode="overwrite", header=True)
# Cease Spark session
spark.cease()
On this instance, we’re utilizing Apache Spark to parallelize information processing from a CSV supply. The repartition(4) technique distributes the info throughout 4 partitions for parallel processing, enhancing effectivity.
source_data.csv file, right here’s a small instance of how one can create it domestically:
id,title,age
1,John Doe,28
2,Jane Smith,34
3,Emily Davis,45
4,Michael Brown,23Implementing Incremental Loading
As an alternative of processing the whole dataset every time, think about using incremental loading methods to deal with solely new or up to date information. Incremental loading focuses on figuring out and extracting simply the info that has modified because the final ETL run, which reduces processing overhead and minimizes useful resource use. This method could be applied by sustaining metadata or utilizing change information seize (CDC) mechanisms to trace modifications in your information sources over time. By processing solely the incremental modifications, you may considerably increase the effectivity and efficiency of your ETL processes.
Detailed Steps and Instance Code
Let’s stroll by means of an instance to show how incremental loading could be applied utilizing SQL. We’ll create a easy situation with supply and goal tables and present how you can load new information right into a staging desk and merge it into the goal desk.
Step 1: Create the Supply and Goal Tables
First, let’s create the supply and goal tables and insert some preliminary information into the supply desk.
sql
-- Create supply desk
CREATE TABLE source_table (
id INT PRIMARY KEY,
column1 VARCHAR(255),
column2 VARCHAR(255),
timestamp DATETIME
);
-- Insert preliminary information into supply desk
INSERT INTO source_table (id, column1, column2, timestamp) VALUES
(1, 'data1', 'info1', '2023-01-01 10:00:00'),
(2, 'data2', 'info2', '2023-01-02 10:00:00'),
(3, 'data3', 'info3', '2023-01-03 10:00:00');
-- Create goal desk
CREATE TABLE target_table (
id INT PRIMARY KEY,
column1 VARCHAR(255),
column2 VARCHAR(255),
timestamp DATETIME
);
On this SQL instance, we’re loading new information from a supply desk right into a staging desk based mostly on a timestamp column. Then, we use a merge operation to replace current information within the goal desk and insert new information from the staging desk.
Step 2: Create the Staging Desk
Subsequent, create the staging desk that quickly holds the brand new information extracted from the supply desk.
-- Create staging desk
CREATE TABLE staging_table (
id INT PRIMARY KEY,
column1 VARCHAR(255),
column2 VARCHAR(255),
timestamp DATETIME
);
Step 3: Load New Knowledge into the Staging Desk
We’ll write a question to load new information from the supply desk into the staging desk. This question will choose information from the supply desk the place the timestamp is larger than the utmost timestamp within the goal desk.
-- Load new information into staging desk
INSERT INTO staging_table
SELECT *
FROM source_table
WHERE source_table.timestamp > (SELECT MAX(timestamp) FROM target_table);Step 4: Merge Knowledge from Staging to Goal Desk
Lastly, we use a merge operation to replace current information within the goal desk and insert new information from the staging desk.
-- Merge staging information into goal desk
MERGE INTO target_table AS t
USING staging_table AS s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET t.column1 = s.column1, t.column2 = s.column2, t.timestamp = s.timestamp
WHEN NOT MATCHED THEN
INSERT (id, column1, column2, timestamp)
VALUES (s.id, s.column1, s.column2, s.timestamp);
-- Clear the staging desk after the merge
TRUNCATE TABLE staging_table;Rationalization of Every Step
- Extract New Knowledge: The INSERT INTO staging_table assertion extracts new or up to date rows from the source_table based mostly on the timestamp column. This ensures that solely the modifications because the final ETL run are processed.
- Merge Knowledge: The MERGE INTO target_table assertion merges the info from the staging_table into the target_table.
- Clear Staging Desk: After the merge operation, the TRUNCATE TABLE staging_table assertion clears the staging desk to organize it for the following ETL run.
Monitoring and Optimising Efficiency
Frequently monitoring your ETL processes is essential for pinpointing bottlenecks and optimizing efficiency. Use instruments and frameworks like Apache Airflow, Prometheus, or Grafana to trace metrics resembling execution time, useful resource utilization, and information throughput. Leveraging these efficiency insights means that you can fine-tune ETL workflows, modify configurations, or scale infrastructure as wanted for steady effectivity enhancements. Moreover, implementing automated alerting and logging mechanisms may help you determine and deal with efficiency points in actual time, guaranteeing your ETL processes stay easy and environment friendly
Knowledge High quality Assurance
Guaranteeing information high quality is essential for dependable evaluation and decision-making. Knowledge high quality points can come up from numerous sources, together with inaccuracies, inconsistencies, duplicates, and lacking values. Implementing sturdy information high quality assurance processes as a part of your ETL pipeline may help determine and rectify such points early within the information integration course of. Knowledge profiling, cleaning, validation guidelines, and outlier detection could be employed to enhance information high quality.
# Carry out information profiling
data_profile = source_data.describe()
# Determine duplicates
duplicate_rows = source_data.groupBy(source_data.columns).rely().the place("rely > 1")
# Knowledge cleaning
cleaned_data = source_data.dropna()
# Validate information towards predefined guidelines
validation_rules = {
"column1": lambda x: x > 0,
"column2": lambda x: isinstance(x, str),
}
invalid_rows = cleaned_data.filter ----(write Filter situations right here)...
On this Python instance, we carry out information profiling, determine duplicates, carry out information cleaning by eradicating null values, and validate information towards predefined guidelines to make sure information high quality.
Error Dealing with and Retry Mechanisms
Regardless of finest efforts, errors can happen through the execution of ETL processes for numerous causes, resembling community failures, information format mismatches, or system crashes. Implementing error dealing with and retry mechanisms is important to make sure the robustness and reliability of your ETL pipeline. Logging, error notification, computerized retries, and back-off methods may help mitigate failures and guarantee information integrity.
from tenacity import retry, stop_after_attempt, wait_fixed
@retry(cease=stop_after_attempt(3), wait=wait_fixed(2))
def process_data(information):
# Course of information
...
# Simulate potential error
if error_condition:
elevate Exception("Error processing information")
attempt:
process_data(information)
besides Exception as e:
# Log error and notify stakeholders
logger.error(f"Error processing information: {e}")
notify_stakeholders("ETL course of encountered an error")
This Python instance defines a operate to course of information with retry and back-off mechanisms. If an error happens, the operate retries the operation as much as thrice with a set wait time between makes an attempt.
Scalability and Useful resource Administration
As information volumes and processing necessities develop, guaranteeing the scalability of your ETL pipeline turns into paramount. Scalability includes effectively dealing with rising information volumes and processing calls for with out compromising efficiency or reliability. Implementing scalable architectures and useful resource administration methods permits your ETL pipeline to scale seamlessly with rising information masses and consumer calls for. Strategies resembling horizontal scaling, auto-scaling, useful resource pooling, and workload administration may help optimize useful resource utilization and guarantee constant efficiency throughout various workloads and information volumes. Moreover, leveraging cloud-based infrastructure and managed companies can present elastic scalability and alleviate the burden of infrastructure administration, permitting you to give attention to constructing sturdy and scalable ETL processes.
Conclusion
Environment friendly information integration is important for organizations to unlock the complete potential of their information belongings and drive data-driven decision-making. By implementing methods resembling parallelizing information processing, incremental loading, and efficiency optimization, you may streamline your ETL processes and make sure the well timed supply of high-quality insights. Adapt these methods to your particular use case and leverage the correct instruments and applied sciences to attain optimum outcomes. With a well-designed and environment friendly ETL pipeline, you may speed up your information integration efforts and acquire a aggressive edge in at the moment’s fast-paced enterprise surroundings.
Key Takeaways
- Understanding your information sources is essential for efficient ETL growth. It means that you can anticipate challenges and plan your technique accordingly.
- Choosing the proper instruments and applied sciences based mostly on scalability and compatibility can streamline your ETL processes and enhance effectivity.
- Parallelizing information processing duties utilizing frameworks like Apache Spark can considerably cut back processing time and improve efficiency.
- Implementing incremental loading methods and sturdy error-handling mechanisms ensures information integrity and reliability in your ETL pipeline.
- Scalability and useful resource administration are important issues to accommodate rising information volumes and processing necessities whereas sustaining optimum efficiency and value effectivity.
The media proven on this article aren’t owned by Analytics Vidhya and is used on the Writer’s discretion.
Often Requested Questions
A. ETL stands for Extract, Remodel, Load. It’s a course of used to extract information from numerous sources, rework it right into a constant format, and cargo it right into a goal system for evaluation. ETL is essential for integrating information from disparate sources and making it accessible for analytics and decision-making.
A. You possibly can enhance the efficiency of your ETL processes by parallelizing information processing duties, implementing incremental loading methods to course of solely new or up to date information, optimizing useful resource allocation and utilization, and monitoring and optimizing efficiency frequently.
A. Frequent challenges in ETL growth embody coping with numerous information sources and codecs, guaranteeing information high quality and integrity, gracefully dealing with errors and exceptions, managing scalability and useful resource constraints, and assembly efficiency and latency necessities.
A. A number of ETL instruments and applied sciences can be found, together with Apache Spark, Apache Airflow, Talend, Informatica, Microsoft Azure Knowledge Manufacturing facility, and AWS Glue. The selection of device depends upon elements resembling scalability, ease of use, integration capabilities, and compatibility with current infrastructure.
A. Guaranteeing information high quality in ETL processes includes implementing information profiling to know the construction and high quality of information, performing information cleaning and validation to appropriate errors and inconsistencies, establishing information high quality metrics and guidelines, and monitoring information high quality constantly all through the ETL pipeline.






